










bonjour à tous et meilleurs voeux 2019 à vous
comme vous m'avez gentillement (et efficacement) répondu je risque d'abuser encore de vos bontés car comme vous le savez après un problème, un problème, c'est bien le soucis avec un newbie motivé
donc en résumé :
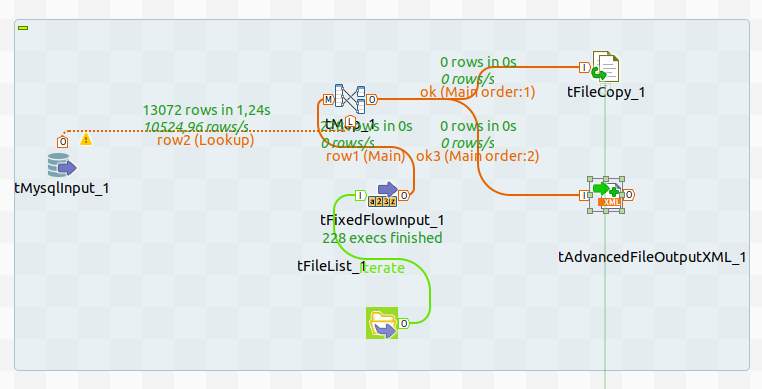
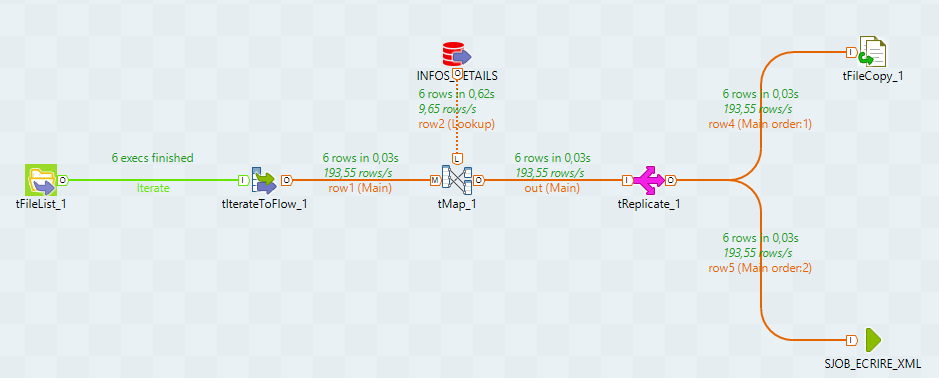
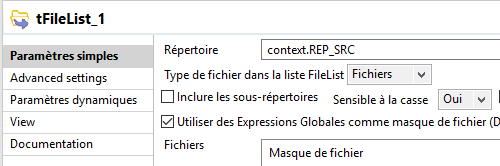
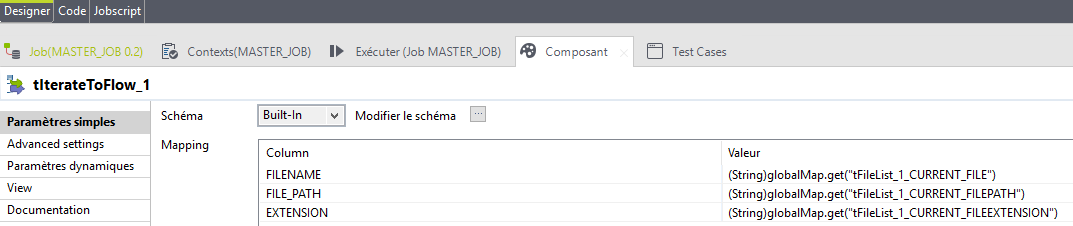
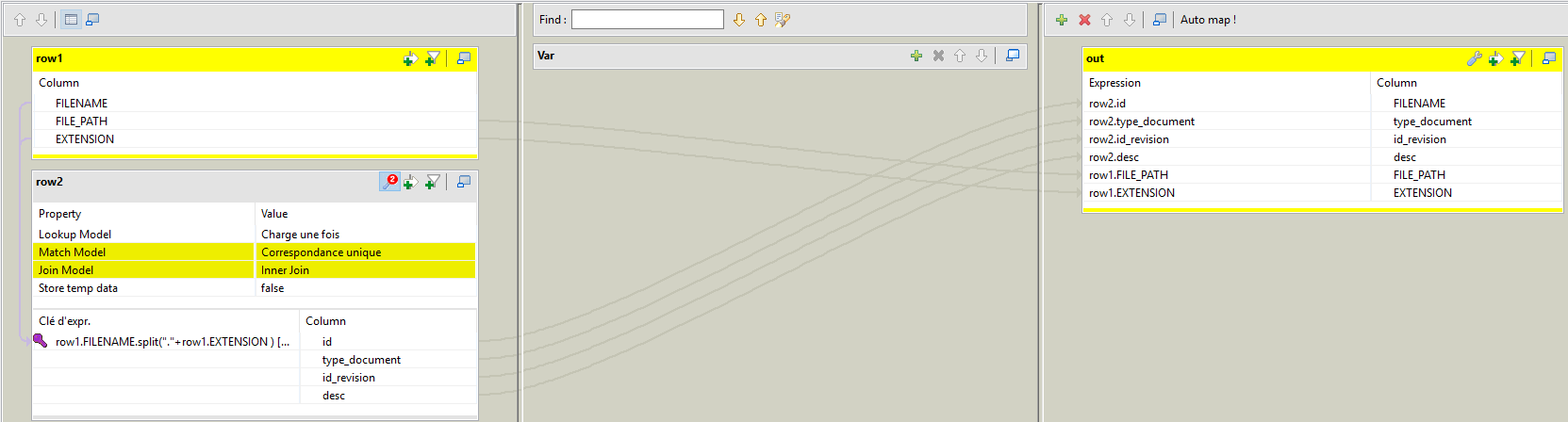
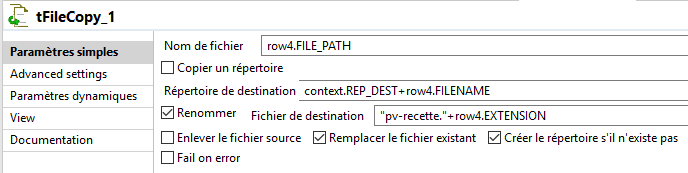
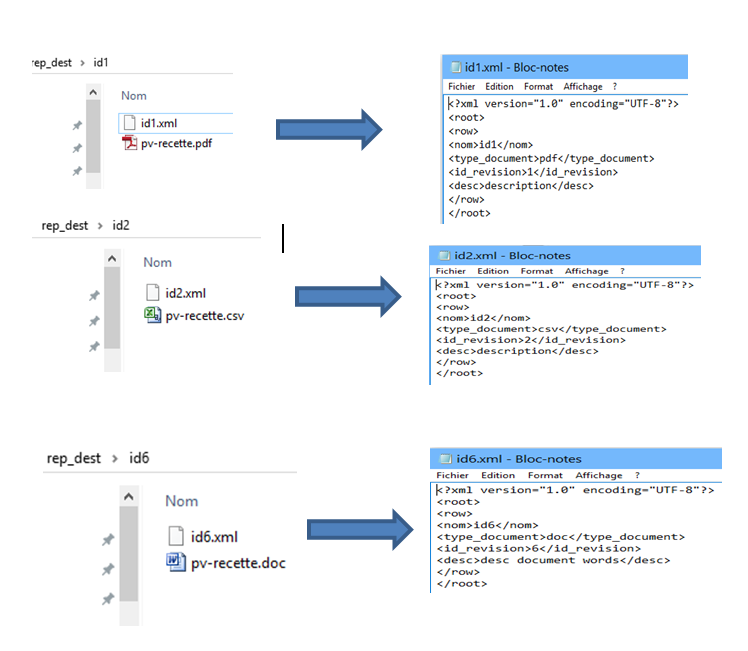
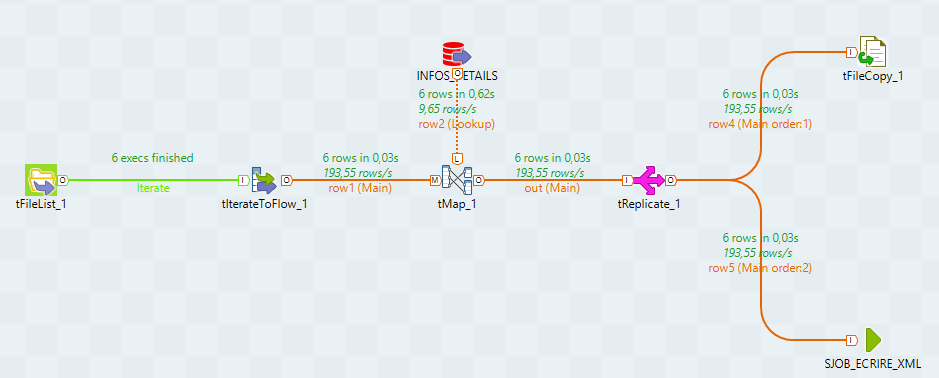
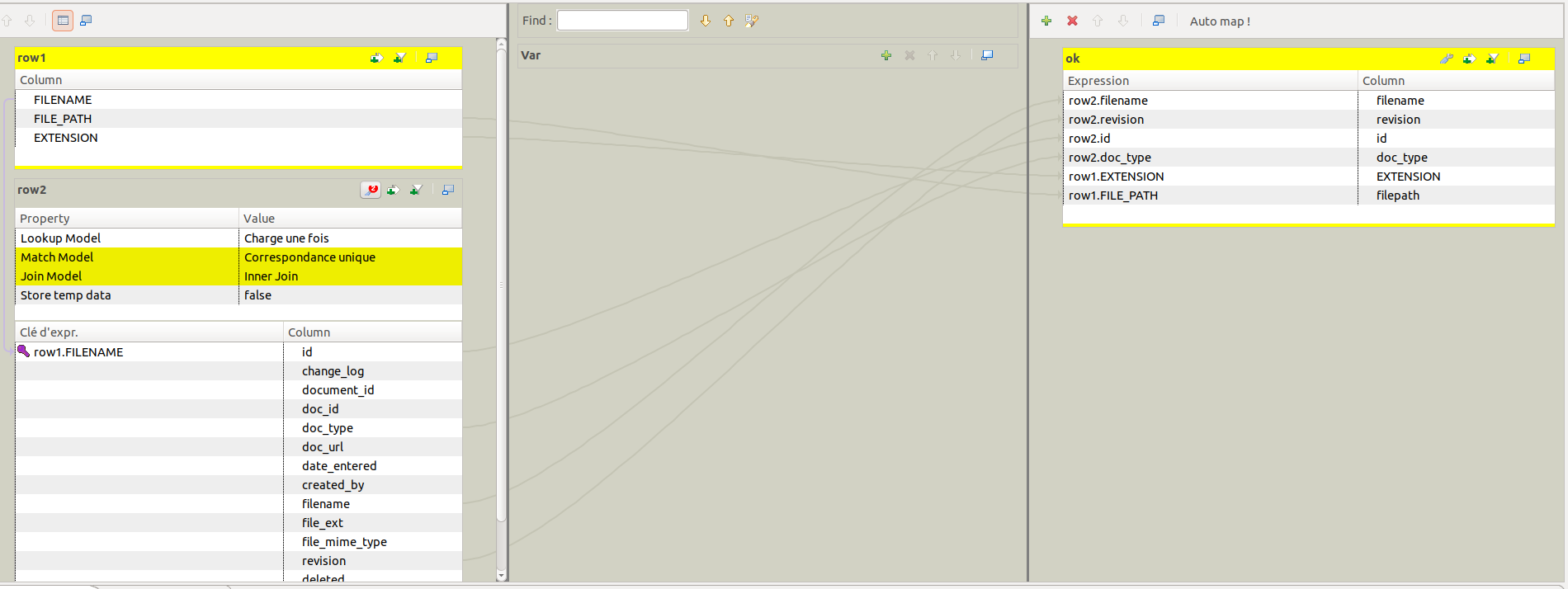
un job (screenshot ci dessous) qui renomme à la volée des fichiers et qui copie le résultat dans des répertoires renommés à la vole aussi avec l'ID du nom d'origine des fichiers. jusque là grâce à vous nickel.
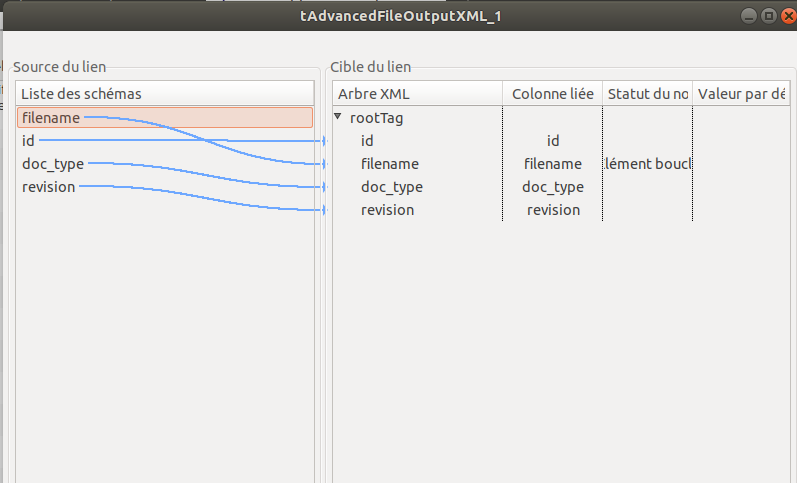
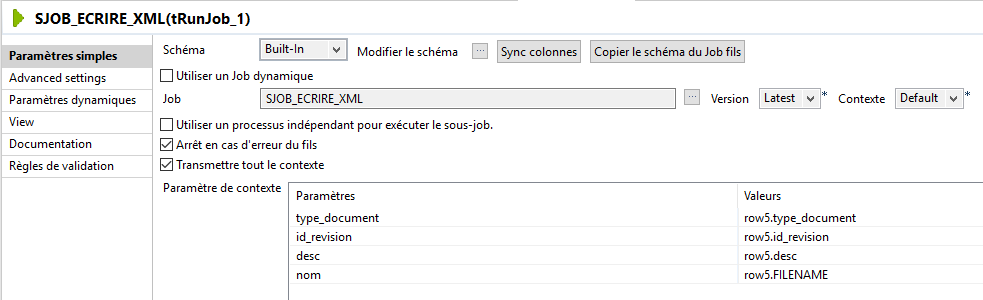
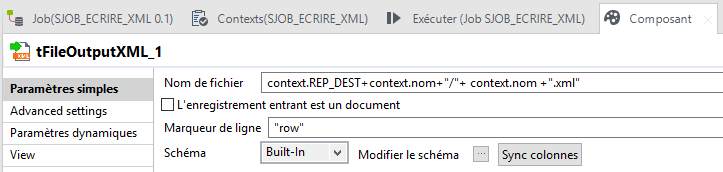
à cela j'ajoute un tadvancedfileoutputxml pour écrire un xml nommé comme les fichiers renommés pas le tfilecopy_1 dans le répertoire (nommé avec l'ID du fichier d'origine). et la tout fonctionne sauf que...à l'intérieur du fichier xml bien nommé et placé au bon endrooit les données ne correspondent pas ID et nom de fichier différents ....
j'espère avoir été clair...et le screen devrait aider j'espere...
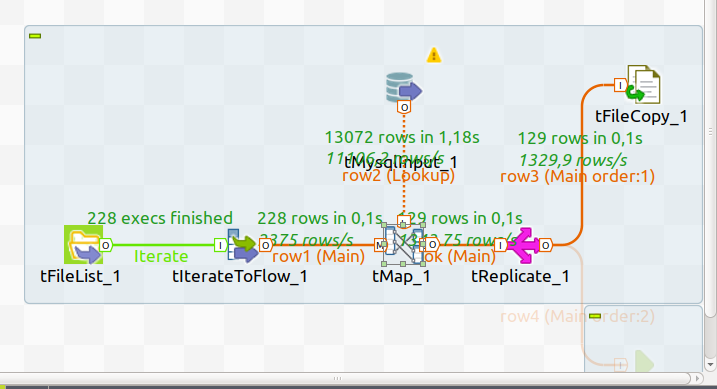
bon zéro row comprends pas pourquoi mais ça marche nickel, sauf à l'intérieur des xml...
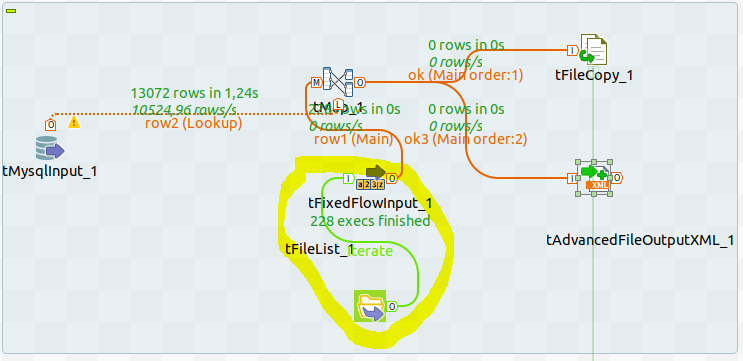
ça aussi pourrait aider :
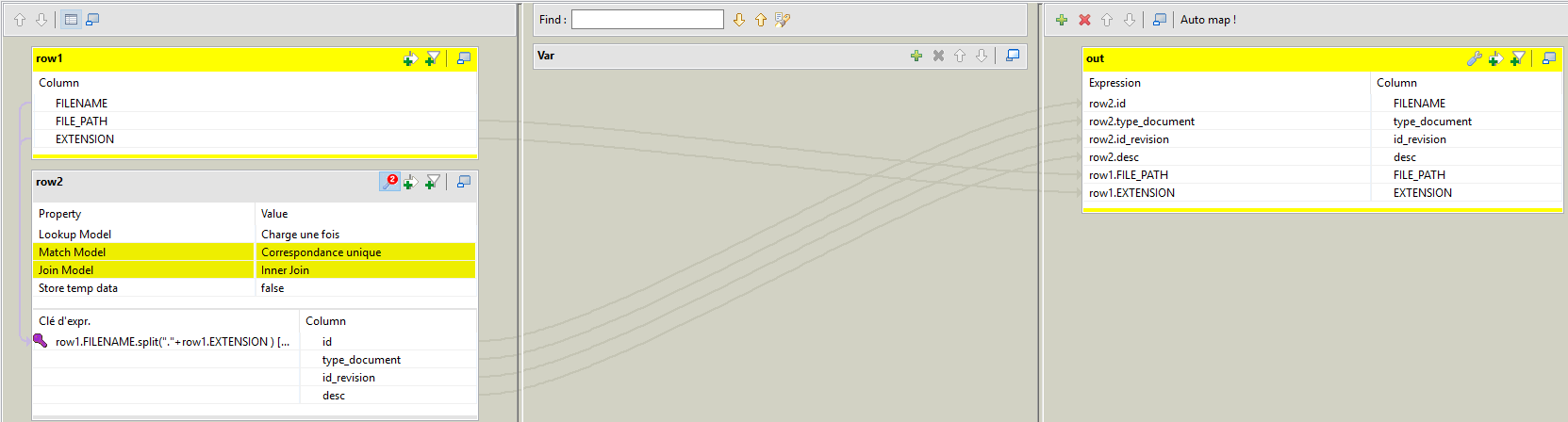
pour le Tmap la jointure est identique pour tfilecopy et tadvancedfileoutputxml donc je m'attendais naivement à obtenir les même résultats (ce qui est vrai sur le nom des fichier et le répertoire où ils vont...seul le contenu des xml est complètement erroné.
Merci d'avance?")
 Répondre avec citation
Répondre avec citation

 pour mettre en valeur la ou les réponses qui vous ont été les plus utiles. Marquez comme
pour mettre en valeur la ou les réponses qui vous ont été les plus utiles. Marquez comme  si c'est le cas.
si c'est le cas.



Partager