










Bonjour à tous,
Alors voilà, je compte essayer de programmer une couche de convolution en C++, mais les sources que je trouve sur le sujet me paraissent trop légères (haut niveau).
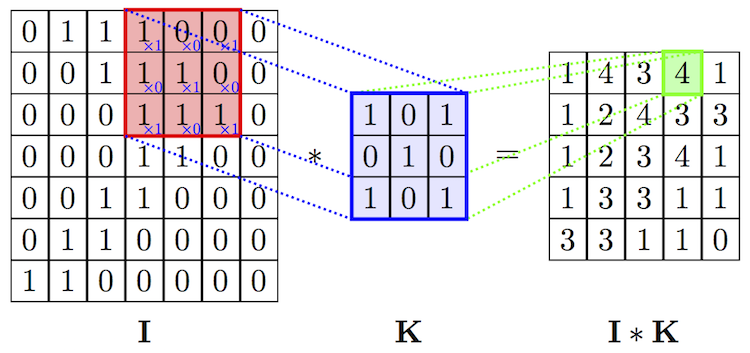
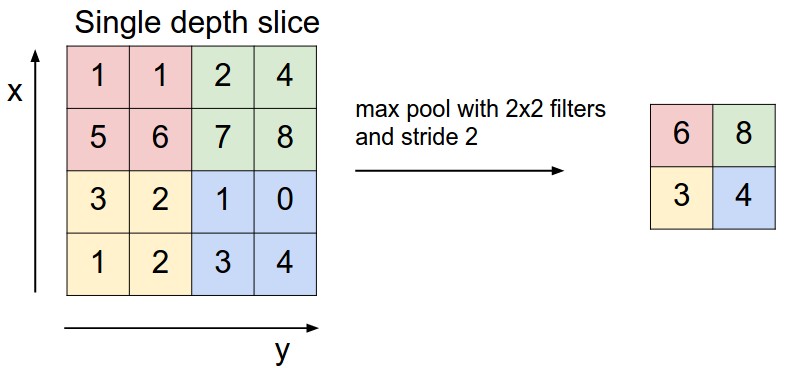
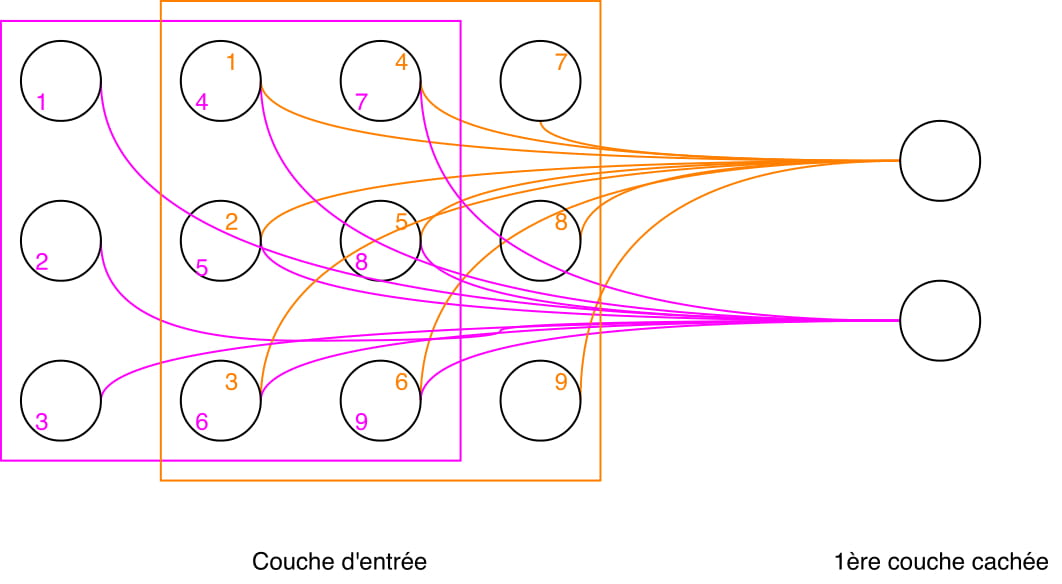
Je comprends bien le fonctionnement des filtres, comment est établi la "features map", les raisons pour lesquelles on ajoute du padding etc... MAIS ! Je ne vois pas du tout où interviennent nos neurones dans cette couche, et je me demande même si, dans le noyau de convolution en lui-même, on a des neurones....
Souvent les sources que je trouve s'arrêtent là et partent de suite sur la résolution d'un problème simple via les bibliothèques que l'on trouve pour python, mais n'expliquent finalement en rien comment est réalisée plus profondément la couche de convolution.
Une idée de l'architecture "réelle" de ce genre de réseaux ? Ou sinon, un lien vers une source expliquant le fonctionnement plus loin que l'obtention des features map via l'application de filtres sur une image (les additions et multiplications, je connais, ça va) ?
Merci d'avance.
 Répondre avec citation
Répondre avec citation



















Partager