











Intel rend open source nGraph, un compilateur de réseau neuronal
pour résoudre le problème de compatibilité entre les frameworks deep learning
Intel a annoncé la mise en open source de nGraph, une bibliothèque pour les réseaux neuronaux profonds (en anglais, DNN, pour Deep Neural Network) conçu pour les systèmes deep learning (ou apprentissage profond). L'apprentissage profond est un ensemble de méthodes d'apprentissage automatique utilisables pour modéliser à un haut niveau d'abstraction des données. Ainsi, la machine apprend par elle-même à réaliser une tâche donnée.
Ce concept regorge de domaines d'application : la reconnaissance d'image, la détection d'objets, la reconnaissance vocale, la traduction automatique de texte, la compréhension du langage écrit ou parlé, la génération automatique d'images, etc.
Selon Intel, avec nGraph, les spécialistes des données peuvent se concentrer sur la science des données sans avoir besoin de s'inquiéter de la manière dont leur modèle DNN sera adapté pour fonctionner efficacement sur différents appareils. Aussi, nGraph peut être utilisé tant pour l'apprentissage que l'inférence.
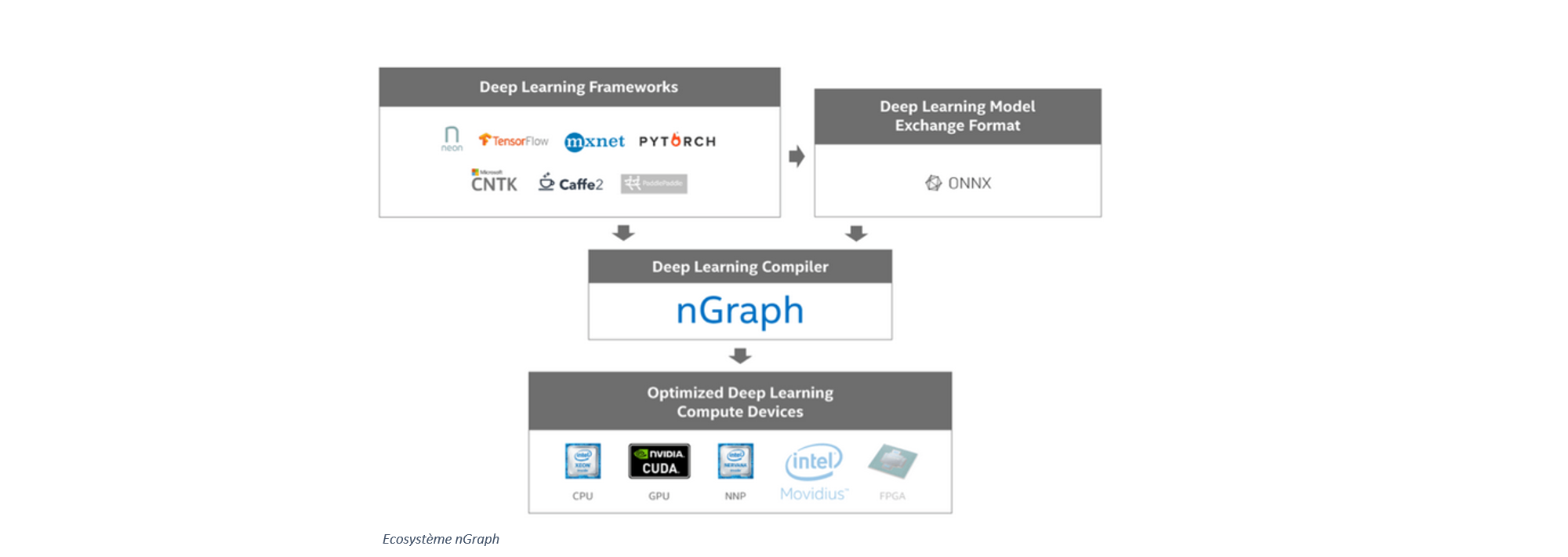
Actuellement, seuls les supports TensorFlow, MXNet et neon, des frameworks de deep learning d'Intel sont directement supportés sur nGraph. CNTK, PyTorch et Caffe2 sont également supportés, mais indirectement à travers ONNX. Les utilisateurs peuvent exécuter leurs frameworks sur nombreux équipements : architecture Intel (x86, Intel® Xeon® et Xeon Phi®), GPU et Intel Nervana Neural Network Processor (NNP).
En effet, quand les premières bibliothèques d'apprentissage profond sont apparues, elles étaient implémentées autour d'un certain nombre de noyaux optimisés pour un matériel donné. Ces noyaux et la manière de décrire des modèles avec une bibliothèque donnée étaient très intriqués, ce qui rendait l'utilisation d'un même modèle avec une autre bibliothèque assez difficile. Changer de matériel impose aussi de revoir de fond en comble l'implémentation de ces noyaux, pour retirer la quintessence des nouveaux processeurs et donc aussi en partie la manière d'écrire les modèles.
nGraph est là pour réduire ces complexités techniques. Des noyaux spécifiquement optimisés sont proposés pour certaines opérations fondamentales, tant dans nGraph que MKL-DNN. Cependant, nGraph apporte aussi des techniques héritées des compilateurs pour encore optimiser le code produit pour exécuter un certain modèle. La communication des opérations à effectuer se fait par un graphe représentant les calculs à effectuer sans aucune dépendance au matériel, ce qui permet de retravailler à volonté le code implémentant le modèle.
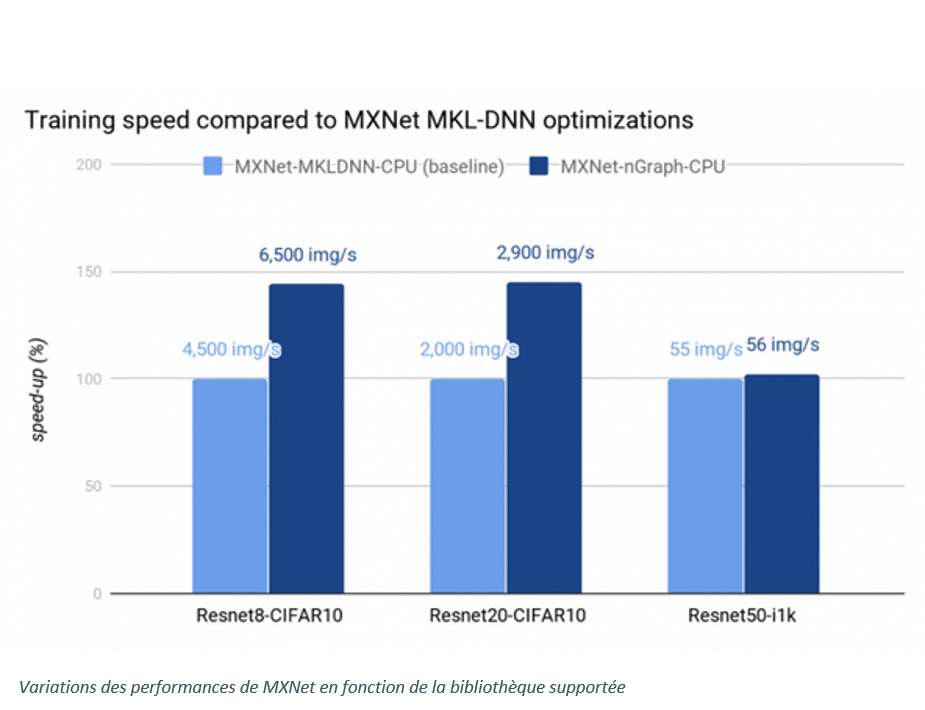
Lorsque MXNet est supporté par la bibliothèque nGraph, il grimpe en performance. Par contre, s'il est supporté par MK-DNN, il baisse en performance. Voir le graphique ci-dessous :
Source : Intel
Et vous ?
Qu'en pensez-vous ?
Voir aussi :

 Répondre avec citation
Répondre avec citation
Partager