1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
| ;================================================================
; CyclesHorloge.asm
; Programme de comptage de durée d'exécution
;----------------------------------------------------------------
.386
.model flat,stdcall
option casemap:none
include \masm32\include\windows.inc
include \masm32\include\user32.inc
include \masm32\include\kernel32.inc
includelib \masm32\lib\user32.lib
includelib \masm32\lib\kernel32.lib
.data
MsgBoxCaption db "Nombre de cycles d'horloge",0
MemoTime1 dd 0
MemoTime2 dd 0
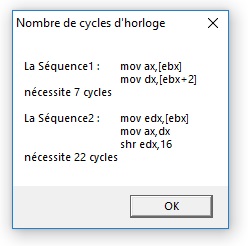
Sequence1 db 'La Séquence1 :',9,'mov ax,[ebx]',13,10,9,9,'mov dx,[ebx+2]',13,10,'nécessite ',0
CyclesH db " cycles",0
Sequence2 db 13,10,13,10,'La Séquence2 :',9,'mov edx,[ebx]',13,10,9,9,'mov ax,dx',13,10,9,9,'shr edx,16',13,10,'nécessite ',0
BufferAscii db 512 dup(?)
.code
Start:
;==== Test Séquence 1
db 0Fh, 31h ; instruction RDTSC (n'existe pas sur cette version de MASM)
mov esi,eax ; mémo partie basse du compteur
;---- Séquence 1 répétée 8 fois
mov ax,[ebx] ; 1
mov dx,[ebx+2]
mov ax,[ebx] ; 2
mov dx,[ebx+2]
mov ax,[ebx] ; 3
mov dx,[ebx+2]
mov ax,[ebx] ; 4
mov dx,[ebx+2]
mov ax,[ebx] ; 5
mov dx,[ebx+2]
mov ax,[ebx] ; 6
mov dx,[ebx+2]
mov ax,[ebx] ; 7
mov dx,[ebx+2]
mov ax,[ebx] ; 8
mov dx,[ebx+2]
db 0Fh, 31h ; instruction RDTSC
sub eax,esi
shr eax,3 ; équivaut à une division par 8
mov MemoTime1,eax
;==== Test Séquence 2
db 0Fh, 31h ; instruction RDTSC (n'existe pas sur cette version de MASM)
mov esi,eax ; mémo partie basse du compteur
;---- Séquence 2 répétée 8 fois
mov edx,[ebx] ; 1
mov ax,dx
shr edx,16
mov edx,[ebx] ; 2
mov ax,dx
shr edx,16
mov edx,[ebx] ; 3
mov ax,dx
shr edx,16
mov edx,[ebx] ; 4
mov ax,dx
shr edx,16
mov edx,[ebx] ; 5
mov ax,dx
shr edx,16
mov edx,[ebx] ; 6
mov ax,dx
shr edx,16
mov edx,[ebx] ; 7
mov ax,dx
shr edx,16
mov edx,[ebx] ; 8
mov ax,dx
shr edx,16
db 0Fh, 31h ; instruction RDTSC
sub eax,esi
shr eax,3 ; équivaut à une division par 8
mov MemoTime2,eax
mov esi,offset Sequence1
mov edi,offset BufferAscii
call CopyChaine
mov eax,MemoTime1
call ConvertAscii
mov esi,offset CyclesH
call CopyChaine
mov esi,offset Sequence2
call CopyChaine
mov eax,MemoTime2
call ConvertAscii
mov esi,offset CyclesH
call CopyChaine
xor al,al ; un zéro pour terminer la chaîne
stosb
;------------ Boîte de message d'affichage de la séquence 1 -------------
invoke MessageBoxA, NULL, addr BufferAscii, addr MsgBoxCaption, MB_OK
;------------ Boîte de message d'affichage puis sortie -------------
;invoke MessageBoxA, NULL, addr BufferAscii, addr MsgBoxCaption, MB_OK
invoke ExitProcess, NULL
;================================================================================
; Conversion valeur binaire format Word en chaîne ASCII dans le Buffer
;--------------------------------------------------------------------------------
; A l'entrée : EAX contient la valeur binaire à transformer en chaîne ASCII
; EDI pointe le buffer recevant la chaîne ASII
ConvertAscii:
push ebx
push ecx
push edx
mov ebx,10
xor ecx,ecx
;--- Divisions par 10 successives pour obtenir un résultat affichable
BcleAscii:
xor edx,edx ; edx = 0 (car c'est la partie haute du dividende)
div ebx ; division par 10 de EDX:EAX
push edx ; on stocke le reste en pile
inc ecx ; on compte le nombre d'empilages
or eax,eax ; si le quotient est nul, on arrête
jnz BcleAscii
;--- Restitution de la pile dans le buffer
BcleBuffer:
pop eax
add al,30h ; conversion en ASCII
stosb
loop BcleBuffer
pop edx
pop ecx
pop ebx
ret
;================================================================================
; Copie d'une chaîne ASCIIZ
;--------------------------------------------------------------------------------
; A l'entrée : ESI pointe la chaîne à copier
; EDI pointe l'emplacement accueillant la chaîne à copier
; NE COPIE PAS LE ZERO DE FIN !!!!
CopyChaine:
lodsb
or al,al ; fin de chaîne à copier ?
jz FinChaine
stosb
jmp CopyChaine
FinChaine:
ret
end Start |









 Répondre avec citation
Répondre avec citation













 Consultez nos FAQ :
Consultez nos FAQ : 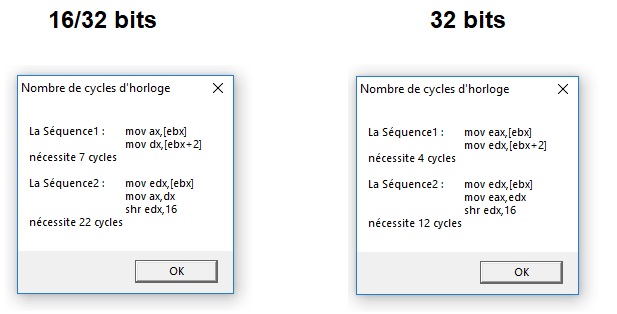




Partager