









Bonjour,
je dois faire un modèle de prédiction qui me permettrait de prédire sur une autre base de données, le benefice net annuel par client.
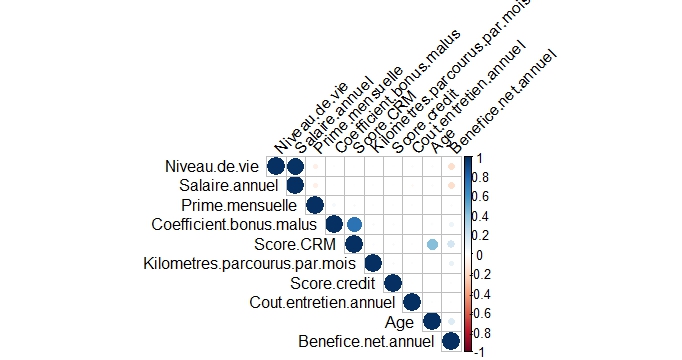
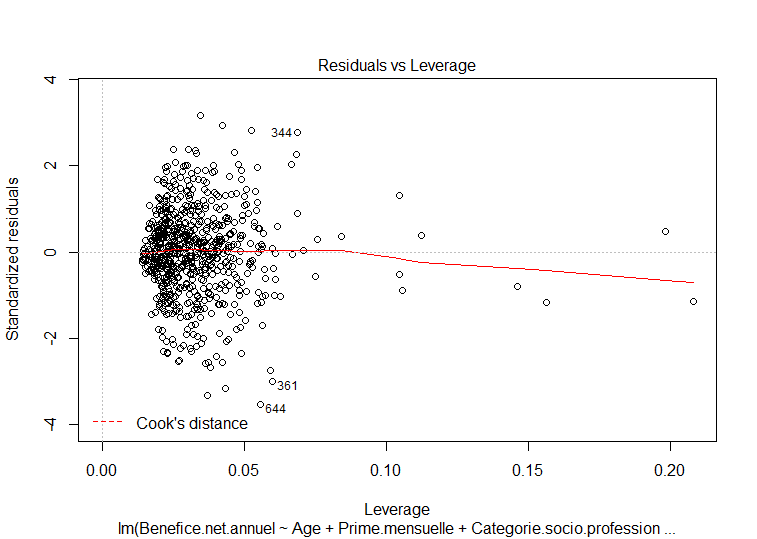
Mon problème est que la variable à expliquer (le bénéfice net annuel) est très peu corrélée avec les autres variables. (image ci-dessous)
La couleur bleue indique la corrélation.
Je me demande si la précision de mon modèle pourrait être acceptable.
Qu'en pensez vous ?
Cordialement

 Répondre avec citation
Répondre avec citation


Partager