












bonjour à tous,
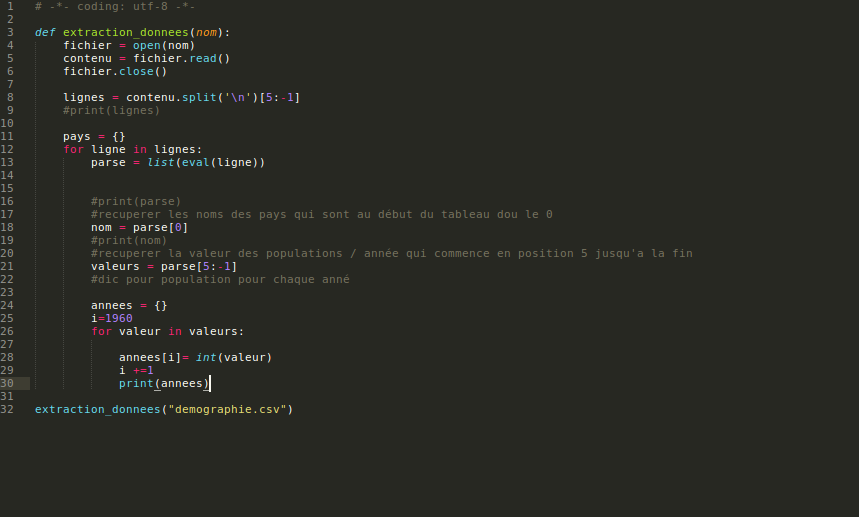
jai un probleme au niveau de mon code, enfaite j'ai un fichier csv avec des noms de pays, nombre d'habitants/années...etc. Je souhaiterais afficher le nombre d'habitant/années pour chaque pays sous forme d'une liste mais jai rencontré une erreur de python. la coversion marche bien mais quand le programme rencontre un chiffre (nombre d'habitant) avec un virgule il me genere une erreur et sarrete automatiquement je ne sais pas comment coriger cela]...pourriez vous m'aider svp parce que cela m'empeche d'avancer sur mon programme ou m'expliquer ou se trouve mon erreur? je vous remercie par avance
[ATTACH=CONFIG]339231[/ATTACH
 Répondre avec citation
Répondre avec citation
Partager