











Google publie en open source sur GitHub "Magika", un outil alimenté par l'IA pour l'identification rapide et efficace des types de fichiers
Google a décidé de rendre Magika open source, mais de quoi s'agit-il exactement ? Il s'agit d'un système innovant basé sur l'IA que le géant de la recherche a conçu pour révolutionner la manière dont les types de fichiers binaires et textuels sont identifiés. Magika se distingue par sa capacité à identifier les fichiers avec précision en quelques millisecondes, même lorsqu'il fonctionne sur une unité centrale.
Magika utilise un modèle d'apprentissage profond (deep-learning) personnalisé et hautement optimisé qui a été méticuleusement conçu et entraîné à l'aide de Keras. Ce modèle est remarquablement léger, puisqu'il ne pèse qu'environ 1 Mo. Pour l'inférence, Magika utilise Onnx comme moteur, ce qui garantit que les fichiers sont identifiés rapidement, presque aussi rapidement que les outils sans IA, même sur un CPU.
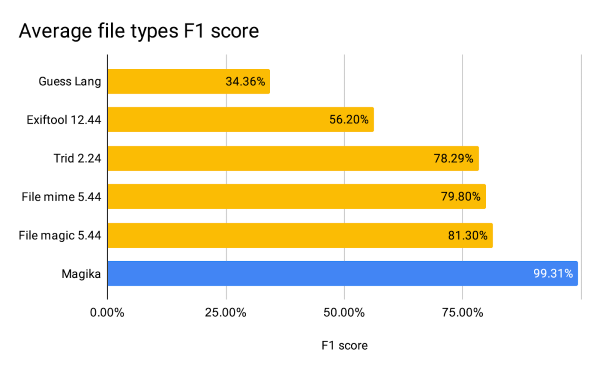
Les performances de Magika sont tout simplement impressionnantes. Lorsqu'il est évalué sur un benchmark d'un million de fichiers couvrant plus de 100 types de fichiers, Magika surpasse les outils existants d'environ 20 %. Le système affiche des gains de performance encore plus importants pour les fichiers textuels, y compris les fichiers de code et les fichiers de configuration, qui ont traditionnellement posé des problèmes aux autres outils.
En interne, Google a déjà exploité Magika pour améliorer la sécurité des utilisateurs. Le système est déployé à grande échelle pour acheminer les fichiers dans Gmail, Drive et Safe Browsing vers les scanners de sécurité et de règles de contenu appropriés. Avec Magika, Google a observé une amélioration de 50 % de la précision d'identification des types de fichiers par rapport aux systèmes précédents qui s'appuyaient sur des règles élaborées à la main. Cette amélioration de la précision a permis d'analyser 11 % de fichiers supplémentaires à l'aide de scanners de documents spécialisés dans l'IA malveillante et de réduire le nombre de fichiers non identifiés à 3 %.
En outre, l'intégration prochaine de Magika avec VirusTotal promet d'améliorer encore l'efficacité et la précision de la plateforme. Magika agira comme un préfiltre avant que les fichiers ne soient analysés par Code Insight de VirusTotal, qui utilise l'IA générative de Google pour détecter les codes malveillants. Cette collaboration devrait contribuer de manière significative à l'écosystème mondial de la cybersécurité.
En ouvrant Magika, Google entend aider d'autres logiciels à améliorer la précision de leur identification de fichiers et fournir aux chercheurs une méthode fiable d'identification des types de fichiers à grande échelle. Le code et le modèle de Magika sont désormais librement accessibles sur GitHub sous la licence Apache2.
Magika peut être facilement installé en tant qu'utilitaire autonome et bibliothèque Python via le gestionnaire de paquets pypi avec la simple commande pip install magika, sans GPU requis. Un package npm expérimental est également disponible pour ceux qui souhaitent utiliser la version TFJS.
Magika : Identification rapide et efficace des types de fichiers grâce à l'IA
Goole met en open source Magika, le système d'identification des types de fichiers alimenté par l'IA de Google, afin d'aider d'autres personnes à détecter avec précision les types de fichiers binaires et textuels. Sous le capot, Magika utilise un modèle d'apprentissage profond personnalisé et hautement optimisé, permettant une identification précise des fichiers en quelques millisecondes, même lorsqu'il est exécuté sur un processeur.
Pourquoi l'identification du type de fichier est difficile
Depuis les premiers jours de l'informatique, la détection précise des types de fichiers a été cruciale pour déterminer comment traiter les fichiers. Linux est équipé de libmagic et de l'utilitaire file, qui ont servi de norme de facto pour l'identification des types de fichiers pendant plus de 50 ans. Aujourd'hui, les navigateurs web, les éditeurs de code et d'innombrables autres logiciels s'appuient sur la détection du type de fichier pour décider comment rendre correctement un fichier. Par exemple, les éditeurs de code modernes utilisent la détection du type de fichier pour choisir le schéma de coloration syntaxique à utiliser lorsque le développeur commence à taper dans un nouveau fichier.
La détection précise du type de fichier est un problème notoirement difficile, car chaque format de fichier a une structure différente, voire pas de structure du tout. Cela est particulièrement difficile pour les formats textuels et les langages de programmation, car ils ont des constructions très similaires. Jusqu'à présent, libmagic et la plupart des autres logiciels d'identification de type de fichier s'appuient sur un ensemble d'heuristiques et de règles personnalisées pour détecter chaque format de fichier.
Cette approche manuelle est à la fois chronophage et sujette aux erreurs, car il est difficile pour les humains de créer des règles généralisées à la main. Pour les applications de sécurité en particulier, la création d'une détection fiable est particulièrement difficile car les attaquants tentent constamment de brouiller la détection avec des charges utiles conçues par des adversaires.
Pour résoudre ce problème et fournir une détection rapide et précise des types de fichiers, Google a étudié et développé Magika, un nouveau détecteur de types de fichiers basé sur l'intelligence artificielle. Sous le capot, Magika utilise un modèle d'apprentissage profond personnalisé et hautement optimisé, conçu et entraîné à l'aide de Keras, qui ne pèse qu'environ 1 Mo. Au moment de l'inférence, Magika utilise Onnx comme moteur d'inférence pour s'assurer que les fichiers sont identifiés en quelques millisecondes, presque aussi rapidement qu'un outil sans IA, même sur CPU.
Performance de Magika
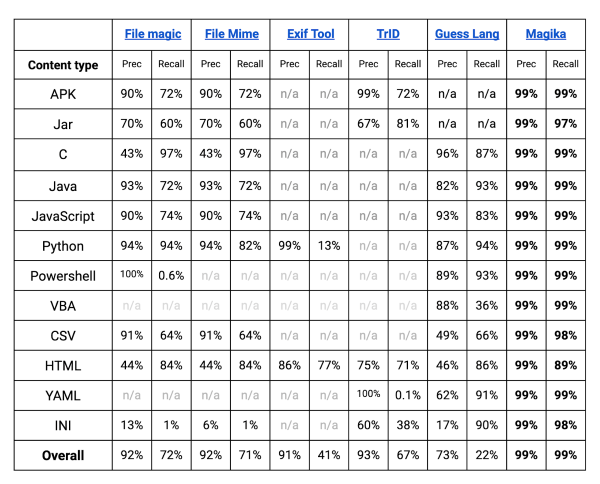
En termes de performances, Magika, grâce à son modèle d'IA et à son vaste ensemble de données d'entraînement, est capable de surpasser les autres outils existants d'environ 20 % lorsqu'il est évalué sur un benchmark de 1 million de fichiers qui englobe plus de 100 types de fichiers. En décomposant par type de fichier, comme indiqué dans le tableau ci-dessous, on constate des gains de performance encore plus importants sur les fichiers textuels, y compris les fichiers de code et les fichiers de configuration avec lesquels d'autres outils peuvent éprouver des difficultés.
Magika chez Google
Google décrit son utilisation de Magika comme suit :
Rendre open-source MagikaEn interne, Magika est utilisé à grande échelle pour améliorer la sécurité des utilisateurs de Google en acheminant les fichiers Gmail, Drive et Safe Browsing vers les scanners de sécurité et de règles de contenu appropriés. L'analyse d'une moyenne hebdomadaire de centaines de milliards de fichiers révèle que Magika améliore la précision de l'identification des types de fichiers de 50 % par rapport à notre système précédent, qui reposait sur des règles élaborées à la main. En particulier, cette amélioration de la précision nous permet d'analyser 11 % de fichiers supplémentaires avec nos scanners de documents malveillants spécialisés et de réduire le nombre de fichiers non identifiés à 3 %.
L'intégration prochaine de Magika à VirusTotal viendra compléter la fonctionnalité Code Insight de la plateforme, qui utilise l'IA générative de Google pour analyser et détecter les codes malveillants. Magika agira comme un préfiltre avant que les fichiers ne soient analysés par Code Insight, améliorant ainsi l'efficacité et la précision de la plateforme. Cette intégration, due à la nature collaborative de VirusTotal, contribue directement à l'écosystème mondial de la cybersécurité, favorisant un environnement numérique plus sûr.
En mettant Magika en open-source, Google souhaite aider d'autres logiciels à améliorer la précision de leur identification de fichiers et offrir aux chercheurs une méthode fiable pour identifier les types de fichiers à grande échelle.
Le code et le modèle de Magika sont disponibles gratuitement dès aujourd'hui sur Github sous la licence Apache2. Magika peut également être rapidement installé en tant qu'utilitaire autonome et bibliothèque python via le gestionnaire de paquets pypi en tapant simplement pip install magika sans GPU requis. Google a également un package npm expérimental si vous souhaitez utiliser la version TFJS.
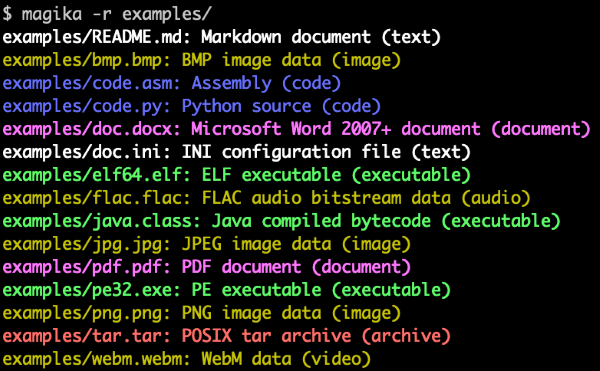
Vous pouvez essayer la démo web de Magika dès aujourd'hui, ou l'installer en tant que bibliothèque Python et outil de ligne de commande autonome en utilisant la ligne de commande standard pip install magika.
Source : Google
Et vous ?
Quel est votre avis sur le sujet ?
Voir aussi :

 Répondre avec citation
Répondre avec citation




Partager