Exécutons le code :
[Year,Date,Time, Elev, Dev, Nb, Cy]=textread('R_con_uel_env_0543_02_20021019T200844_20091226T195730', '%s %s %s %f %f %s %s','hearderlines',1,'commentstyle','#','delimiter',';');
MATLAB renvoie le message d'erreur :
Error using dataread
Invalid comment style.
Error in textread (line 174)
[varargout{1:nlhs}]=dataread('file',varargin{:}); %#ok<REMFF1>Si on lis la documentation de la fonction
textread, on remarque que la propriété
commenstyle prend les valeurs matlab (%), shell (#), c (/**/), ou c++ (//)
En remplaçant
'#' par
'shell' :
[Year,Date,Time, Elev, Dev, Nb, Cy]=textread('R_con_uel_env_0543_02_20021019T200844_20091226T195730', '%s %s %s %f %f %s %s','hearderlines',1,'commentstyle','shell','delimiter',';');
MATLAB renvoie le message d'erreur :
Error using dataread
Unknown option 'hearderlines'.
Error in textread (line 174)
[varargout{1:nlhs}]=dataread('file',varargin{:}); %#ok<REMFF1>Il y a un
r en trop dans le nom de la propriété
headerlines Bravo pour avoir vu cela ... je reste encore fébrile sur l'utilisation des commandes et leur orthographe
En corrigeant cette coquille :
[Year,Date,Time, Elev, Dev, Nb, Cy]=textread('R_con_uel_env_0543_02_20021019T200844_20091226T195730', '%s %s %s %f %f %s %s','headerlines',1,'commentstyle','shell','delimiter',';');
Le code ne renvoie plus d'erreur.
Par contre, les valeurs renvoyées ne sont pas parfaites :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| Year =
'2000.0700 '
''
'2000.1500 '
''
'2000.2100 '
''
'2000.3000 '
''
'2000.3700 '
''
'2000.4400 '
''
'2000.6200 '
''
'2000.7200 '
''
'2000.7900 '
''
'2000.8800 '
'' |
Regardons le format de plus près :
'%s %s %s %f %f %s %s'. Tu utilises
%s pour extraire des chaines de caractères et
'%f' pour extraire des valeurs numériques. Mais en analysant le contenu des colonnes j'écrirais plutôt :
'%f %s %s %f %f %f %f' non ? Voire sans les espaces inutiles :
'%f%s%s%f%f%f%f' C'est que dans mon esprit %f était plus pour des chiffres avec décimales et %s pour des infos dont je n'ai pas vraiment besoin pour mon traitement
Essayons :
[Year,Date,Time, Elev, Dev, Nb, Cy]=textread('R_con_uel_env_0543_02_20021019T200844_20091226T195730','%f%s%s%f%f%f%f','headerlines',1,'commentstyle','shell','delimiter',';');
Renvoie :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| Year =
1.0e+03 *
2.0001
0
2.0002
0
2.0002
0
2.0003
0
2.0004
0
2.0004
0
2.0006
0
2.0007
0
2.0008
0
2.0009
0 |
On remarque toujours les valeur intercalées. Tu demandes à lire 7 valeurs par ligne alors qu'il y a 8 colonnes (8 fois le séparateur
")
avec la dernière colonne vide.
Bien vu aussi. Je compte tout le temps les colonnes et pas leur séparateurs
On va donc demander à
textread de lire une dernière valeur sur chaque ligne sans la stocker avec le marqueur * :
[Year,Date,Time, Elev, Dev, Nb, Cy]=textread('R_con_uel_env_0543_02_20021019T200844_20091226T195730','%f%s%s%f%f%f%f%*f','headerlines',1,'commentstyle','shell','delimiter',';');
Ce qui renvoie :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
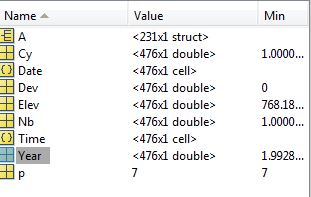
| >> Year
Year =
1.0e+03 *
2.0001
2.0002
2.0002
2.0003
2.0004
2.0004
2.0006
2.0007
2.0008
2.0009
>> Date
Date =
'2000/01/26 '
'2000/02/24 '
'2000/03/17 '
'2000/04/19 '
'2000/05/15 '
'2000/06/10 '
'2000/08/14 '
'2000/09/20 '
'2000/10/16 '
'2000/11/18 ' |
C'est nettement mieux.










 Répondre avec citation
Répondre avec citation


















Partager