1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
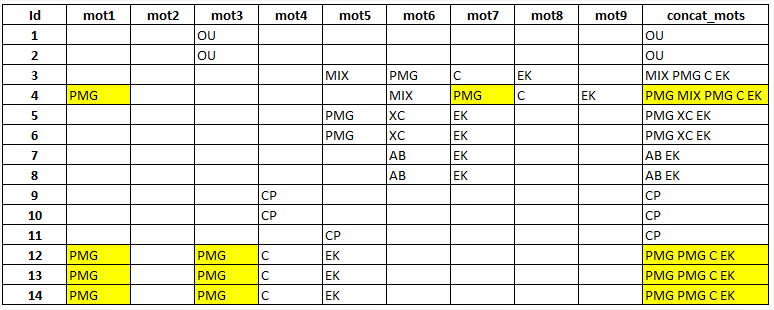
| data test;
infile cards dsd dlm=',';
input id mot1 $ mot2 $ mot3 $ mot4 $ mot5 $;
cards;
1,ou,ou,ou,pmg ,
2, ,ou,ou,ou,
3,PMG,PMG,ou ,PMG,
4,PGM,ou,PGM,ou,
;run;
DATA test2;
LENGTH motdic $80 ;
IF _N_=1 THEN DO;
DECLARE HASH DIC();
DIC.DEFINEKEY('motdic');
DIC.DEFINEDONE();
END;
SET test;
ARRAY mot(*) mot1 mot2 mot3 mot4 mot5;
RC_dic=DIC.CLEAR();
DO Boucle=1 TO dim(mot);
motdic=mot(Boucle);
RC_dic=DIC.CHECK();
IF RC_dic=0 THEN CALL MISSING(mot(Boucle));
ELSE RC_dic=DIC.ADD();
END;
DROP RC_dic motdic boucle ;
RUN; |









 Répondre avec citation
Répondre avec citation







Partager