Bonjour à tous,
Je dois crée une base de donnée capable d'enregistrer différents relevés de température puis les afficher dans un navigateur sous forme de graphique.
Pour peupler cette base, j'ai différents boitiers qui enregistrent entre 1 à 15 sondes puis envoient les données à intervalle régulier (toutes les 5min) au serveur via une requette HTTP. Pour info, le boitier envoi ses données dans un tableau dont la clef correspond au nom de la température mesurée : value['piece1'] = 10°C
Ces sondes peuvent mesurer la température de différentes choses que je dois être capable d'identifier.
Exemple:
Aujourd'hui, la sonde #1 mesure la température de la pièce N°1. La sonde #2 n'est pas utilisée.
Demain, la sonde #1 mesure la température de la pièce N°2. La sonde #2 mesure la température de la pièce N°1.
Je me demande donc comment ordonner cela...
Pouvez vous m'indiquer laquelle des solutions ci-dessous est selon vous la meilleure (ou m'indiquer une autre solution plus adéquate le cas échéant):
- 1 ligne "mesures" par enregistrement liée à une configuration donnée (1 à 15 données)
- boitiers [boitier_id | localisation]
- enregistrements [enregistrement_id | boitier_id | enregistrement_date]
- configurations [configuration_id | name_in1 | name_in2 | name_in3 ....... name_in15]
- mesures [mesure_id | enregistrement_id | configuration_id | value_in1 | value_in2 | value_in3 ....value_in15]
Le problème est que dans la majorité des cas, le boitier n'enregistre que quelques valeurs de température (4/5) et non les 15 maxi. J'aurais donc beaucoup de valeurs NULL.
- 1 ligne "mesures" par température mesurée pour chaque boitier
- boitiers [boitier_id | localisation]
- enregistrements [enregistrement_id | boitier_id | enregistrement_date]
- entrées [entrée_id | entrée_nom]
- mesures [mesure_id | enregistrement_id | entrée_id | value_entrée]
Je me pose alors la question du nombre de ligne générées par ce genre de schéma: imaginons que j'ai 100 régulations qui me génèrent 1 ligne dans "enregistrement" toutes les 5min. Cela me génère entre 1 et 15 lignes associées dans la base "mesures" soit entre 1200 et 18.000 lignes par heures... soit entre 1 à 13 millions de lignes par mois...
- 1 table pour chaque température relevée
- boitiers [boitier_id | localisation]
- enregistrements [enregistrement_id | boitier_id | enregistrement_date]
- mesures1 [mesure1_id | enregistrement_id | value_entrée1]
- mesures2 [mesure2_id | enregistrement_id | value_entrée2]
- mesures3 [mesure3_id | enregistrement_id | value_entrée3]
- ....
- mesures15 [mesure15_id | enregistrement_id | value_entrée15]
Quand est il du post traitement (PHP) où il va falloir attribuer à chaque valeur une clef pour afficher mon graph correctement ?











 Répondre avec citation
Répondre avec citation















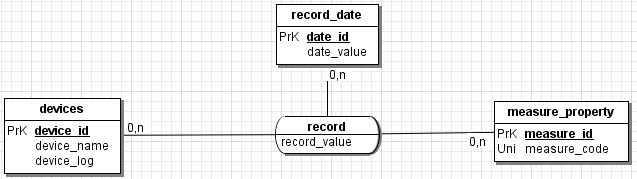

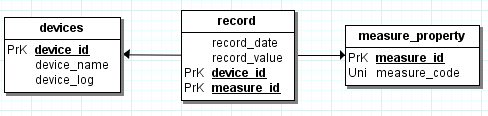
 a partir du moment ou un boitier possède plusieurs sondes, même si une sonde mesure toujours la même pièce, il convient de maintenir cette ET
a partir du moment ou un boitier possède plusieurs sondes, même si une sonde mesure toujours la même pièce, il convient de maintenir cette ET
Partager