









Bonjour !
Je me suis récemment intéressé aux réseaux de neurones. En commençant par les réseaux dits "Feed-Forward". J'ai obtenu de bons résultats dans la reconnaissance de chiffres (MNIST). Cependant, ces simples réseaux de neurones ne permettent pas l'invariance des données. Càd qu'il faudra passer par une segmentation/ normalisation de l'image pour que le réseau puisse détecter avec un bon taux de réussite les chiffres.
Je me suis donc intéressé aux réseaux de neurones à convolutions, qui ont pour avantage l'invariance des données. Je me suis documenté sur le net, j'ai trouvé toute la théorie nécessaire à la compréhension du réseau. Excepté un point, la rétro-propagation du gradient utilisé pour ces réseaux (Càd, la manière de propager l'erreur de sortie en fonction des paramètres, les poids, du réseau).
Je me suis dis que si certains francophones pouvaient m'aider, ce serait surement ici.
Je ne rentrerai pas dans la théorie complète des rdn et je ne vous cache pas que de toute manière, seule une personne connaissant plus ou moins le sujet pourra m'éclairer.
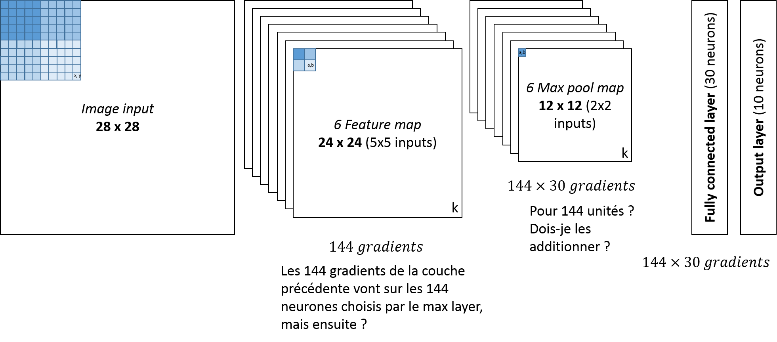
Donc, voici une image qui illustre les questions restant floues dans mon esprit :
Point par point :
1. Je calcule les gradients de mes couches de neurones entièrement connectées (les deux à droites, en commençant par la plus à droite)
2. Je dois ensuite faire passer ces 144 x 30 (chaque neurones de l'avant dernière couche est connecté à chaque neurone de chaque max pool map). Ma question est la suivante, dois-je additionner les 30 gradients connecté à un "neurone" de la max pool map pour obtenir le gradient de ce "neurone" ? Si non, comment faire ?
3. Imaginons que nous ayons choisi la solution de l'addition des gradients pour la couche précédente, on a donc 144 gradient qui arrivent à la feature map. Celle ci contient 576 neurones. Ici l'inégalité du nombre de gradient s'explique par le fait qu'un Max pooling redirige son gradient vers son entrée la plus grande. Cependant, pour calculer le gradient d'un neurone d'une feature map, il faut convoler sa matrice de poids (inversée) avec sa matrice de gradient, or, dans notre cas, UN seul gradient est associé à UN neurone dans la feature map.. Je ne comprends pas.
Désolé si je ne suis pas clair, mais à force d'essayer de faire interagir entre eux des neurones artificiels ce sont mes propres neurones qui finissent par ne plus interagir entre eux
 Répondre avec citation
Répondre avec citation






 ton poste tu dois marquer quand la bonne réponse tu as obtenu.
ton poste tu dois marquer quand la bonne réponse tu as obtenu.




Partager