











Salut,
Bloqué depuis quelques jours sur une tache, je fais appel à toi lecteur émérite et expert SQL.
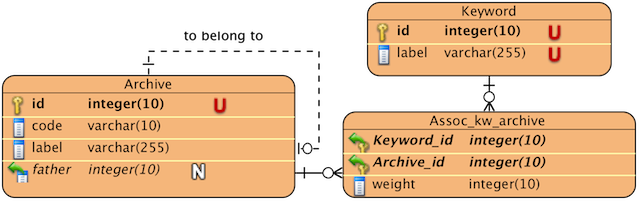
Tout d'abord un petit diagramme d'entités-relations
Une archive peut comporter des archives fils. Pour chaque mot clé associé à une archive un poids est attribué et ce pour donner de l'importance au mot.
Un exemple du contenu de la base
Archive
id code label father 1 B28 Confidentiel 2 B28.1 Zone nucléaire 1
Association archive - mot clé
id keyword_id archive_id weight 1 1 1 10 2 1 2 20 3 2 2 30 4 3 2 40
Mots clés
id label 1 SECURITE 2 ZONE 3 NUCLEAIRE
La demande
L'objectif ici est de réaliser une recherche sur cette base.
Scénario d'utilisation
L'utilisateur saisit une chaine de caractère composée de mots du langage courant (français) ou de mots spécifiques. En fonction de ces derniers, une liste d'archives lui est retourné.
Volumétrie
La table d'archive est composée de 100 000 tuples, 80 000 pour la table de mots clés et 1 000 000 d'associations entre ces deux entités.
Le raisonnement
La logique
Pour répondre au problème, différents facteurs sont à prendre en compte :
- L'être humain peut se tromper dans l'orthographe d'un mot, l'accorder, le préfixer...
- Le poids d'un mot lui donne de l'importance
- Donner une plus-value aux archives comportent les x mots clés proches de ce que tape l'utilisateur
Pour répondre au premier facteur j'utilise la distance de levenshtein entre le mot tapé par l'utilisateur et le mot clé, mais aussi la distance de levenshtein entre le double métaphone du mot tapé par l'utilisateur et le double métaphone du mot clé.
Pour le second facteur, plus le poids est élevé plus le mot à de l'importance.
D'un point de vue SQL
Ayant tourné très longtemps sur différentes versions de la requête, mon esprit est maintenant embrouillé et je n'arrive plus à prendre de recul.
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
Le problème
Il est simple. En l'état cette requête fonctionne avec un mot clé, en revanche avec X mots clés elle est très longue (+ de 40 secondes). Normal me direz vous, je fais une jointure pour chaque mot donné par l'utilisateur, et sur 1 million d'associations c'est douloureux. Mais je n'arrive pas à trouver une solution où je donne une plus-value à un ensemble de mots clés proches de la chaine tapée par l'utilisateur.
Conclusion
Je fais appel à ta logique, l'exercice étant de trouver les archives en fonction de la chaine de caractères tapée par l'utilisateur.
Exemple :
recherche -> "Sécurité en zaunes nucléaires" (zaunes au lieu de zones, et aux pluriel alors qu'en base c'est au singulier)
résultat -> Archives "D28.1 Zone nucléaire, D28 Confidentiel"
Si t'as une piste, donnes, si t'as une autre solution de recherche (plein-text...) donnes, si t'as des remarques donnes, en fait donnes tout ce que t'as, je suis preneur
Un grand merci pour ton aide par avance.
 Répondre avec citation
Répondre avec citation
Partager