Bonjour,
J'ai un peu avancé sur le nom des ordonnées-abscisses.
Alors alors, j'ai un fichier .txt dont la première ligne contient les titres de 7 colonnes puis la 2e ligne contient des informations non voulues. Et enfin, la 3e ligne contient le jeu de données séparés par des \t
mon code pour cette partie est :
data<-read.table("chemin_fichier.txt",header=TRUE,sep="\t",quote="\"'",dec=".",skip=2
Je m'intéresse à la 3e colonne contenant des valeurs avec doublons compris sur un intervalle large de 2 à 7 avec 2 décimales. J'en fait un rapide histogramme :
hist(data$V3,col="lightblue",border="black",xlab="valeurs",main="chemin_fichier.txt")
Sans rentrer dans les détails des classes et des sous-intervalles, je fais une uniformisation via runif que je multiple par 360. Je me suis servie de l'aide heR.Misc
1
2
3
|
library(heR.Misc)
hist_cir<-runif(data$V3)*360 |
Je fais mon histogramme circulaire :
1
2
| rose(hist_cir,bins=30,rscale=10,labels=FALSE,rings=TRUE,col="cyan")
title(main="chemin_fichier_circular",xlab="valeur",ylab="effectif") |
Grossièrement, j'obtiens des portions partant du centre vers l'extérieur. Ces portions ont une forme triangulaire. Je souhaite que ces portions aient une forme rectangulaire.
En clair :
Que ça :
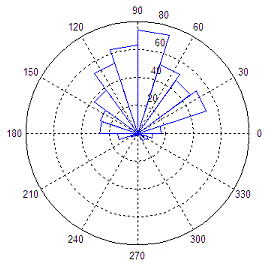
source : http://www.google.fr/imgres?client=u...ed=0CFcQrQMwAA
Devienne ça :
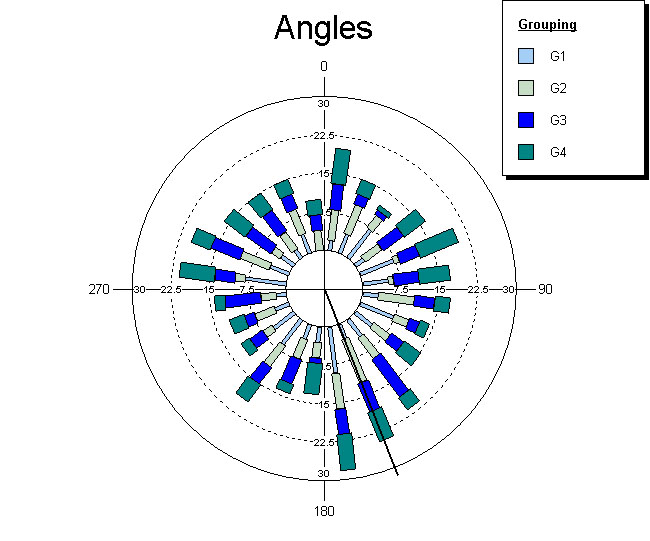
source : http://www.google.fr/imgres?start=26...IUCEK0DMFU4yAE
merci google pour les images...
Est-ce que c'est plus clair ? 




 Répondre avec citation
Répondre avec citation







Partager