











je mets au point un programme dont la solidité/fiabilité dépend de la génération de nombres aléatoires. une des applications dans le programme est la génération de clés.
je sais que par nature le "vrai" hasard n'existe pas sur un ordinateur.
je me souviens encore avec un frisson dans le dos de la célèbre vunérabilité introduite dans le package openssl dans debian qui est resté indétectée entre 2006 et 2008 (un bug dans l'algo de random a eu pour effet de bord de réduire l'espace des clés à seulement ~32000 possibilités...), appelons-ce "désir de couvrir tout l'espace des clés de manière homogène" le probleme #A. J'ai également entendu parler de temps en temps de casino online qui se font dépouiller parce que leur "hasard" peut en fait etre prédit avec une marge d'erreur faible. Appelons "désir de non prédictibilité" probleme #B.
J'aimerais bien me résoudre A et B.
Mon probleme principal n'est pas vraiment l'absence d'idée mais plutot : comment spécifier mathématiquement les propriétés que je cherche à valider pour ensuite les convertir en tests scriptés (unitaires) et enfin utiliser ces tests scriptés pour comparer les différentes implémentation de génération de nombre aléatoire.
je précise tt de suite : les math/stats j'aimais bien ca à l'école, mais 10 ans plus tard j'ai bcp de mal à re-rentrer dans.
D'intuition B me parait +délicat et +inaccessible. Alors je préfère commencer par A.
Je pensais à générer un nombre "grand" de clés de 1024 bits (100k ou 1M) et vérifier que le nombre de doublon est quasi nul. Le ratio qualité/cout/délai de cette vérif me semble bon, mais c'est pas très élégant. Du coup, je comptais y aller plus finement : cad générer 1 000 000 octets aléatoires et faire des controles statistiques.
Par exemple : compter et comparer le nombre doccurrences de chacune des 256 possibilités après ce million de tirages
L'évènement X251 "obtenir le nombre 251 après un tirage" n'a que deux issues : le succès (proba = 1/256) et l'échec (255/256). La question "quelle est la probabilité d'obtenir au moins K succès sur N tirages" est typiquement une loi binomiale (en avant les gros mots)
=> http://fr.wikipedia.org/wiki/Loi_binomiale
avec un écart type :
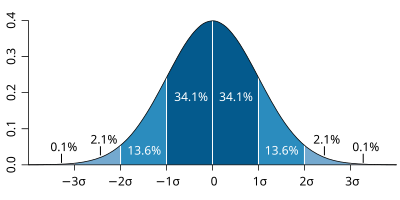
or d'après cette page, avec un tirage grand -- le cas ici -- ca tent vers la loi normale.
donc
score moyen = 1 000 000 / 256 = 3906,25
écartype = sqrt( 1 000 000 * (1/256) * (255/256) ) = 62,37781024
En gros au bout d'un million de tirages, si on prend l'intervalle +/- 2 écarts-type, j'ai 95.4% de chances de tirer entre
3782 (3906.25 - 2 * 62.37781024 = 3781,49438
et
4031 (3906.25 + 2 * 62.37781024 = 4031,00562)
fois le nombre 251
Mes questions
1. est-ce que ce raisonnement se tient jusque là ou je me suis déjà vautré avant ?
1.a si c'est correct, ai-je donc une probabilité de 0.954 ^ 256 ~= 5.8E-6 (cad quasi nulle) que tous les scores soient dans l'intervale 3782 -> 4031 (attention aux arrondis) ? ou est-ce qu'il faut alors parler de proba conditionnelle ?
1.b en suivant la mmeme idée, je crois avoir de l'ordre de 35% de chances d'avoir tous les scores dans l'intervalle +/- 3 écart-type. est-ce exact?
2. est-ce que je ferai mieux de m'interesser aux centiles ou déciles de ces 256 scores plutot que chercher à vérifier qu'ils sont tous dans tel ou tel intervalle ?
3. en m'attaquant au probleme B, est-il pertinent de chercher à déterminer (tjs avec un nombre élevé de tirages) la probabilité d'observer ensuite 0, 1, 2, 3, ... 255 sachant qu'on a eu X au tirage précédent ? cad observer les 256 * 256 = 65 536 successions possibles de deux tirages pour déterminer si avoir précédemment obtenu telle valeur influe sur le tirage suivant)
4. quelle autre mesure me permettrait de tester le caractère non prédictible d'une fonction de génération de nombre aléatoire ? (j'ai entendu parlé des fonctions acf et pacf dans R pour détecter un pattern dans une séquence de nombres, mais là je me sens largué)
les idées sont bienvenues

 Répondre avec citation
Répondre avec citation






Partager