Bonsoir,

Envoyé par
CinePhil

Là j'ai plus de mal...
Je reprends donc le fil de mes tentatives dexplication et passe aux index. Dans ce qui suit, je me limiterai à la façon dont travaille DB2 for z/OS dans les versions précédant la V9, laquelle comporte des raffinements pouvant à loccasion rendre incomplètes, voire caduques certaines de mes explications.
Un index DB2 est un arbre équilibré (balanced tree) ; comme je lai déjà dit, cela signifie que toutes les feuilles sont à la même distance de la racine, autrement dit, le temps daccès est le même pour toutes les feuilles. Ceci est capital quand il sagit de sattaquer au réglage des performances, lesquelles seraient aléatoires si larbre nétait pas équilibré. Les index sont donc le plus souvent, des arbres B, et dans le cas de DB2 ce sont même des B+, je reviendrai un peu plus loin sur cette particularité.
N.B. Jai écrit que le temps daccès est le même pour toutes les feuilles : ceci est vrai quand lindex vient dêtre créé ou réorganisé, mais au fil du temps il peut y avoir une dégradation perceptible des performances du fait de nombreuses mises à jour, et il est alors préférable de procéder à une réorganisation de lindex. DB2 met à notre disposition, dans son catalogue, toutes informations utiles à cet effet.
Observons maintenant comment DB2 (disons version 5) organise un index. Celui que je dépiaute (appelons-le MEMBRE_X1) est destiné à contenir les valeurs de la clé primaire de la table MEMBRE des membres de DVP : '0012' (valeur de la clé primaire du membre CinePhil), '4089' (valeur de la clé primaire du membre Fsmrel), etc.
Supposons que lindex vient dêtre défini et vide. Lors du premier INSERT, par exemple du membre SQLpro dans la table MEMBRE, DB2 crée un enregistrement dans le table space daccueil des images des lignes de la table. Appelons MEMBRE_TS ce table space.
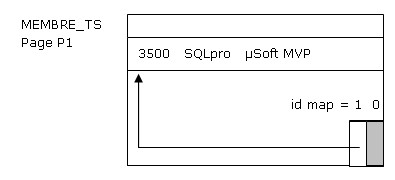
La page P1 contient un certain nombre dinformations « système », dont une petite table appelée id map contenant ladresse dans P1 de la ligne qui vient dêtre insérée. Le rôle de lid map est capital : les index branchés sur la table ne connaîtront jamais ladresse exacte dune ligne dans le table space, mais seulement ladresse de la page P1 et le numéro du poste (invariable) de cette ligne dans lid map (1 dans lexemple). Ainsi, si les enregistrements bougent dans la page, ou sont carrément expulsés vers dautres pages (« Ôte-toi de là, que je my mette ! » dit le gros enregistrement au petit), ces phénomènes nauront aucun impact sur les valeurs connues par les index (dans lexemple, la seule information connue est 'P1,1', à savoir ladresse de la page et le numéro de poste dans lid map).
Concernant lindex MEMBRE_X1, DB2 réalise les opérations suivantes à loccasion de ce premier insert :
Création de la page racine et dune page feuille.
DB2 note dans la page feuille les coordonnées de SQLpro dans MEMBRE_TS, à savoir un record identifier (RID), composé du numéro de la page hébergeant SQLpro, et du numéro qui lui est affecté dans lid map : 'P1,1'.
DB2 note dans la page racine la plus grande valeur de clé au niveau inférieur et ladresse de celle-ci (symbolisée par '↑').

Effectuons un deuxième INSERT, par exemple du membre CinePhil. Il reste de la place dans la page P1 du table space MEMBRE_TS, et elle ressemblera à quelque chose comme ceci :
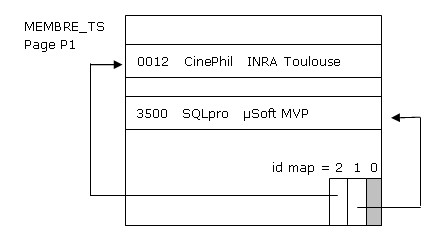
Lid map sest enrichie dun élément (poste), portant le numéro 2 et contenant ladresse dans P1 du nouvel enregistrement.
Lindex MEMBRE_X1 est mis à jour en conséquence :
La feuille est enrichie dun élément permettant dadresser dans MEMBRE_TS le membre dont la valeur de clé est égale à '0012'. Les éléments dans la feuille sont triés, ce qui fait que lélément "3500 (RID = 'P1,1')" passe derrière le nouvel arrivant.
La racine ne change pas de contenu, par construction elle conserve toujours la plus grande valeur de clé de la feuille cible.
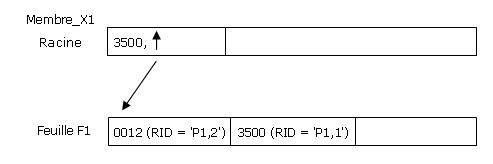
Les inserts se suivent et se ressemblent : Fsmrel (clé = '4089'), Antoun (clé = '0967'), etc.
Au fil de ces inserts, le table space contiendra de plus en plus de pages et lindex suivra. A un moment donné, il ny aura plus assez de place dans la feuille F1 : DB2 créera une feuille supplémentaire F2 et en notera ladresse dans la racine. Dans la figure ci-dessous, la racine contient donc deux entrées, une pour F1 et une pour F2. Chaque entrée contient la plus grande valeur de clé pour chaque feuille ainsi que ladresse de celle-ci.
La séquence des clés doit être strictement respectée, aussi les feuilles seront-elles chaînées à cet effet : ceci favorise les traitements de masse (batch) pour lesquels les requêtes SQL SELECT comportent une clause ORDER BY (attention, au sein des pages de données, P1, etc., les lignes ne sont pas triées). Ce chaînage des feuilles fait que les index DB2 ne sont pas seulement des arbres B, mais B+.
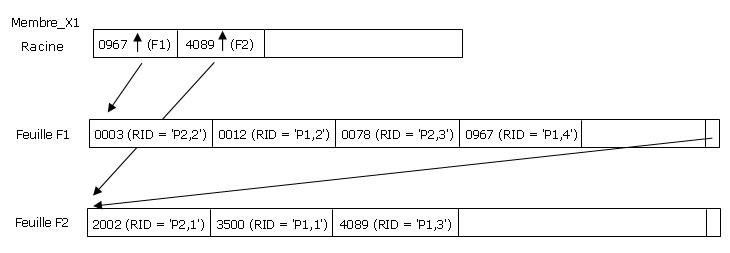
Si lon soumet linstruction :
1
2
3
4
|
SELECT NOM
FROM MEMBRE
WHERE MembreId = '3500' |
Alors DB2 lira le contenu de la racine de lindex Membre_X1, et comme '3500' est supérieur à '0967' et inférieur à '4089', ce sera la feuille F2 qui sera lue à son tour. La lecture suivante sera celle de la page de données P1. La consultation de lid map permettra de retrouver les données du membre '3500'.
Les inserts continuant, de nouvelles feuilles vont être crées et le nombre dentrées dans la racine croîtra en conséquence. Arrivera un moment où à son tour elle sera pleine :
Cest alors que DB2 effectue un split de cette racine, en en répartissant lensemble des éléments dans deux pages, pour moitié entre chacune d'elles. Mais comme par définition la racine ne comporte quune page, ces deux pages deviennent des nuds intermédiaires et une nouvelle racine est créée, nadressant plus cette fois-ci les feuilles, mais ces nuds intermédiaires. Je résume la situation dans le dessin ci-dessous, extrait dun cours que jai monté il y a vingt ans (DB2 V2) et que jai retouché pour les besoins de la cause :
.jpg)
A chaque fois que la racine sera pleine, il y aura split et création dun nouveau niveau intermédiaire.
Quelques estimations
Revenons-en aux bovins. Lattribut ID_FEMELLE composant la clé primaire est du type Integer. Je me sers à nouveau de DB2 Estimator pour tout savoir sur lindex FEMELLE_PK_X ayant pour clé ID_FEMELLE. Pour 67 000 000 de têtes, les chiffres sont les suivants :
La taille de la clé est de 4 octets.
La taille de chaque page est de 4 KB. Comme dans le cas du table space, jai prévu un free space de 20% par page et une page complètement libre après chaque paquet de 15 pages.
=>
Nombre de niveaux dindex : 4.
Racine : 1 page.
Niveau intermédiaire 1 : 3 pages.
Niveau intermédiaire 2 : 689 pages.
Niveau feuille : 228 669 pages.
Je fais observer à cette occasion que, vu le grand nombre de lignes de la table, il est souhaitable de partitionner le table space en sous-table spaces, correspondant chacun à une fourchette de clés. Le but est de pouvoir effectuer les tâches de service (sauvegardes, restaurations, réorganisations, chargements incrémentaux) non pas pour un table space gigantesque, mais pour des partitions de taille beaucoup plus réduite. De même, cela permet de paralléliser les traitements de masse. Tout ceci est évidemment transparent pour la table, autrement dit les applications ne sont pas affectées (sinon que leurs performances ne peuvent qu'être améliorées).
Incidemment, si lon partitionne le table space utilisé pour la table FEMELLE et que le critère de partitionnement est lattribut ID_FEMELLE, DB2 Estimator nous apprend que lon gagne un niveau dindex :
Pour 10 partitions :
Nombre de niveaux dindex : 3.
Racine : 1 page.
Niveau intermédiaire : 76 pages.
Niveau feuille : 24 908 pages.
Pour 80 partitions :
Nombre de niveaux dindex : 3.
Racine : 1 page.
Niveau intermédiaire : 10 pages.
Niveau feuille : 3 114 pages.
Concernant lindex FEMELLE_NOM_X ayant pour clé lattribut FEMELLE_NOM (de type VARCHAR(32)) :
Intuitivement, cet index est bien plus volumineux que le précédent (du moins dans sa version non partitionnée). En effet, DB2 (V8) considère que cette clé mesure exactement 32 octets. Paradoxalement, cest le contraire qui aura toutes les chances de se produire...
Il faut en effet tenir compte dun paramètre important, à savoir en moyenne combien de vaches portent le même nom. Supposons quun 'COUNT (DISTINCT FEMELLE_NOM)' nous apprenne quil y a 6 700 000 noms distincts. Ce ne sont pas 67 000 000 valeurs de clés qui seront stockées dans lindex, mais dix fois moins : chaque valeur ne figure quune fois, accompagnée des RID (4 octets chacun) de chaque homonyme. Dans ces conditions, DB2 Estimator annonce :
Nombre de niveaux dindex : 4.
Racine : 1 page.
Niveau intermédiaire 1 : 28 pages.
Niveau intermédiaire 2 : 2 346 pages.
Niveau feuille : 199 405 pages, contre 228 669 pages ci-dessus.
Si le nombre de noms distincts est de 500 000, soit en moyenne 130 bêtes portant le même nom, les chiffres sont les suivants :
Racine : 1 page.
Niveau intermédiaire 1 : 19 pages.
Niveau intermédiaire 2 : 1 534 pages.
Niveau feuille : 130 351 pages.
Mais le nombre de niveaux dindex reste égal à 4.
A noter que DB2 for z/OS V9 autorise la compression des clés dans les index, mais malheureusement DB2 Estimator ne va pas au-delà de la V8, ce qui pour lobservation est gênant, mais bon...








 Répondre avec citation
Répondre avec citation


















Partager