










Bonjour à tous,
Quelques infos pratiques avant de commencer (je ne sais pas si toutes les infos seront utiles)
OS : Windows 7 (64 bits)
Processeur : Intel Core i7
RAM : 12 Go
Interface d'utilisation de PostGreSQL 9.3 : pgAdmin III
Forme d'utilisation de PostGreSQL : Utilisation en local uniquement pour du SQL
Niveau en SQL : Novice - J'ai quand même les notions de base
Question n°1 :
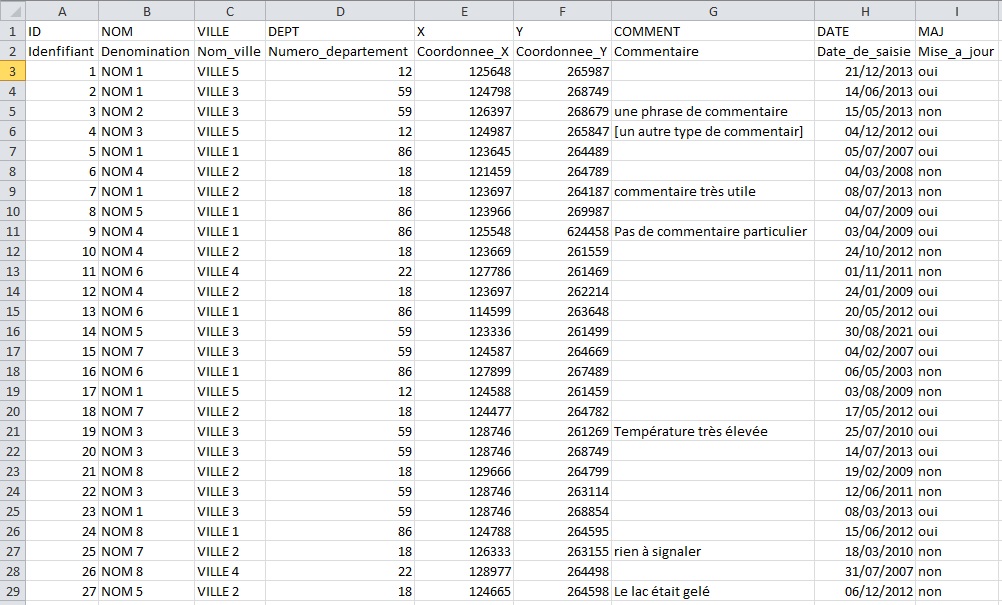
Est-il possible d'importer un fichier TXT contenant 2 lignes d'en-tête (cf. pièce-jointe ci-dessous) ?
exemple_1.txt
Je sais qu'il est possible d'importer un fichier TXT en précisant qu'il y a une ligne d'en-tête via ce type de requête par exemple :
Mais en cherchant sur le net, je n'ai pas trouvé le moyen de paramétrer l'import pour qu'il commence à partir d'une certaine ligne, la troisième ligne dans mon cas. Pensez-vous que cela soit possible ?
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
Bien sur, l'une des solutions serait de supprimer la ligne directement dans le fichier TXT, mais je dois importer des fichiers qui font parfois plus de 500 Mo. Et c'est quasiment impossible de modifier de tels fichiers via un éditeur de texte tel que Notepad...
Question n°2 :
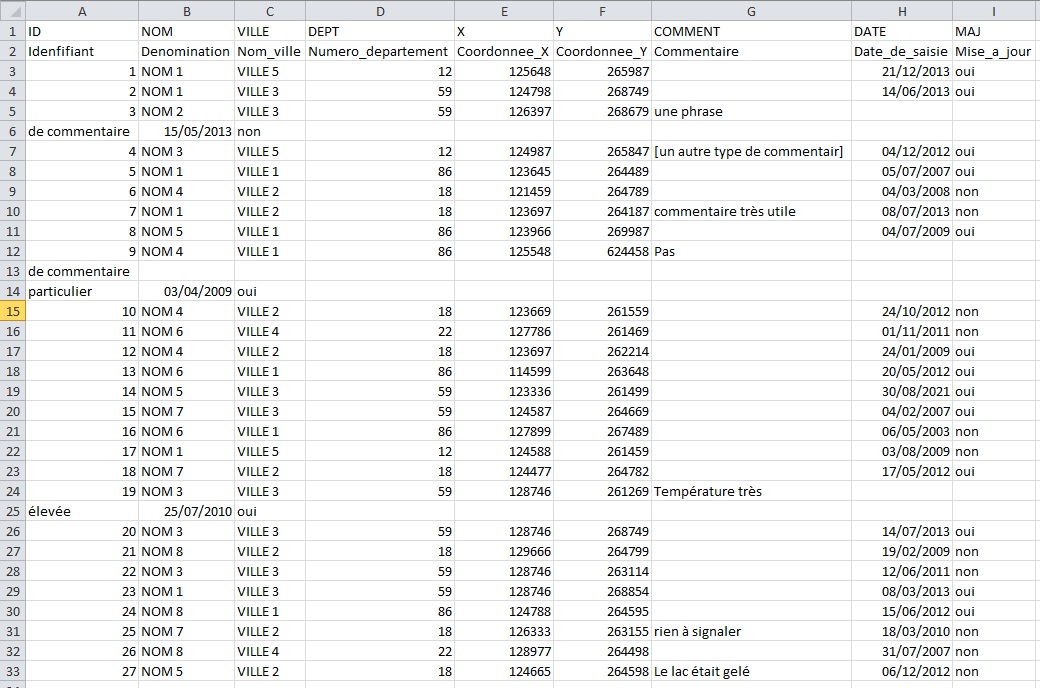
Une autre difficulté s'ajoute au problème listé ci-dessus... Je dois agréger dans une BDD "globale" tout un ensemble de BDD "locales" que l'on m'a transmis. Ce sont les fameux fichiers TXT à double en-tête. Ces BDD "locales" disposent d'une colonne "COMMENT" qui contient des commentaires libres. Le soucis, c'est que de manière assez récurrente, des sauts de ligne se sont invités dans cette colonne faisant passer le reste du commentaire ainsi que l'information des colonnes qui suivent sur une nouvelle ligne... (cf. pièce-jointe ci-dessous pour mieux comprendre ce que je veux dire)
exemple_2.txt
Dans ce cas de figure, je me demande s'il existe un moyen de "dire" à PostGreSQL de supprimer le saut de ligne lors de l'import pour les lignes qui en ont besoin.
Par exemple, l'idée serait de "dire" à PostGreSQL :
Si tu trouve autre chose qu'un nombre dans la première colonne lors de la phase d'import, supprime le saut de ligne au début de cette ligne.
Ça me paraît peu probable qu'il soit possible de faire ce genre de chose, mais si c'était possible, ça me simplifierait grandement la vie... Car comme évoqué précédemment, je dispose de fichiers TXT qui font plus de 500 Mo, et retravailler ce type de fichier est à mon avis tout simplement impossible en passant via un éditeur de texte.
L'une des solutions serait de demander à ceux qui m'ont fourni ces BDD aussi lourdes de me les retransmettre en plusieurs fichiers TXT segmentés, mais ce serait vraiment très lourd (beaucoup de personnes à contacter, relancer de nouveau un processus de validation de ma demande, devoir faire ça chaque année...).
Par conséquent, si certains d'entre vous ont des conseils à me donner ou des solutions à m'apporter, je suis preneur.
Je remercie par avance tous ceux qui prendront le temps de lire mon sujet et tous ceux qui pourront me conseiller d'une manière ou d'une autre.
 Répondre avec citation
Répondre avec citation






Partager