














Une nouvelle étude montre la montée en puissance du NoSQL
Avec de plus en plus d'entreprises qui se tournent vers le cloud public
La NoSQL désigne une famille de systèmes de gestion de bases de données (SGBD) qui sécarte du paradigme classique des bases relationnelles. À partir des années 2000, les grandes entreprises du web ont été amenées à traiter des volumes de données très importants, une tâche non adaptée au modèle relationnel qui souffre de plusieurs limitations liées au fait quil a été conçu pour fonctionner sur des ordinateurs uniques. Afin de répondre à ces limites, ces entreprises ont commencé à développer de nouvelles solutions de gestion de bases de données pouvant fonctionner sur des architectures matérielles distribuées et permettant de traiter des volumes de données importants. Ces nouveaux systèmes NoSQL sont dotés de performances qui restent bonnes avec la montée en charge (scalabilité) en multipliant simplement le nombre de serveurs, solution raisonnable avec la baisse de coûts.
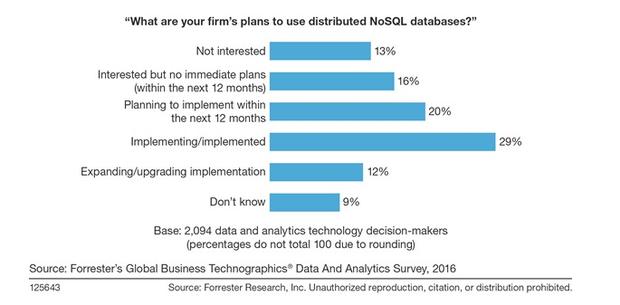
Aujourdhui, les bases de données NoSQL sont devenues incontournables, avec de plus en plus dentreprises qui se tournent vers ces solutions. Selon le rapport Forrester Wave for Big Data NoSQL, Q3 2016, « le NoSQL nest plus une option, cest une nécessité pour les applications de nouvelle génération ». Les décideurs (de plusieurs pays, dont la France) ont réalisé le potentiel que présente le NoSQL. Lenquête de Forrester a révélé que 29 % des interrogés ont déclaré avoir déjà implémenté ou sont en train dimplémenter la technologie NoSQL; 12 % sont en train délargir ou mettre à niveau leurs implémentations. Les entreprises sont attirées par le modèle NoSQL qui permet le traitement dénormes quantités de données, la structuration relationnelle faible et la capacité daccès très rapide, quitte à multiplier les serveurs.
61 % des entreprises interrogées par Forrester ont déjà implémenté une base de données NoSQL ou prévoient de le faire à court terme
Il nest plus question aujourdhui de savoir si les entreprises vont adopter le NoSQL, 61 % des entreprises interrogées par Forrester ont déjà implémenté une base de données NoSQL ou prévoient de le faire à court terme. Aujourdhui, on se demande plutôt si les entreprises vont se contenter de leurs propres serveurs ou se tourner vers le cloud public.
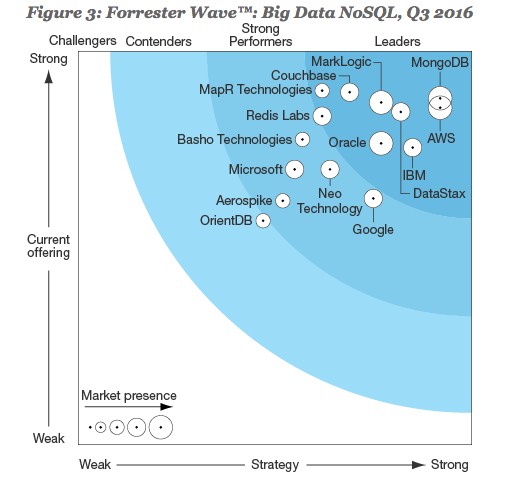
Classement des différentes SGBD NoSQL sur le marché
Pour le classement des bases de données NoSQL, MongoDB reste le leader et la solution open source la plus populaire. Cette base de données NoSQL orientée-document tire sa popularité de sa facilité et sa capacité de supporter la montée en charge des applications les plus exigeantes. La solution NoSQL Cloud propriétaire DynamoDb est aussi bien classée. Utilisable essentiellement via AWS, cette solution est exploitée par les entreprises pour un large éventail de tâches, comme les campagnes de publicité, les applications de médias sociaux et la collecte et lanalyse de données Bien que Microsoft a eu un certain retard sur ce marché, sa solution Azure DocumentDB a connu une forte croissance depuis son lancement.
Selon les chiffres avancés par le cabinet détudes Gartner, le nombre de machines virtuelles (VMs) du cloud public a été multiplié par 20 en trois ans (entre 2011 et 2014 ) alors que les VM du cloud privé ont été multipliées par 3, une performance liée au fait que le cloud public permet une scalabilité horizontale adaptée aux nouveaux besoins du marché. Le cloud public favorise une agilité accrue qui permet aux entreprises de se concentrer sur lamélioration de leurs services et laisser aux opérateurs du cloud la tâche de gérer leur infrastructure. Selon Gartner, dici 2020, 10 % de part du marché de systèmes de bases de données va être conquise par des solutions de cloud public, ce qui ne peut que renforcer le statut du NoSQL comme la solution de choix pour les applications de nouvelle génération.
Source : Forrester - Gartner
Et vous ?
Qu'en pensez-vous ?
Voir aussi :
 Répondre avec citation
Répondre avec citation
Partager