







Bonjour,
J'essaye de récupérer par le code un fichier texte produit par une API :
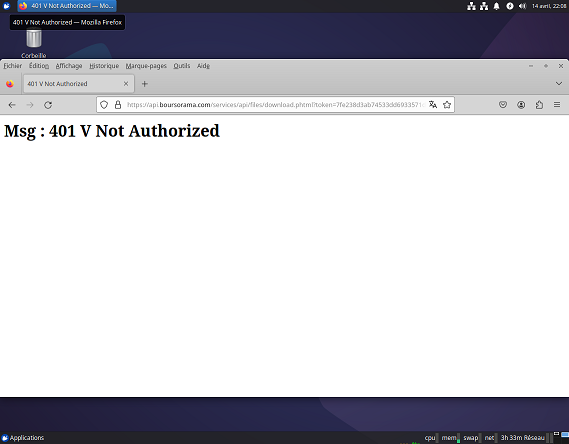
https://www.boursorama.com/bourse/ac...bol=0P0000VHMO
Si je saisis cette URL directement dans le navigateur, un fichier texte est automatiquement enregistré dans mes "téléchargements"
Si je le fais par le code, cela me génère une erreur 401.
Voici le code Python que j'ai essayé (parmi d'autres) :
J'ai essayé de spécifié des headers, et même de façon aléatoire, mais cela ne marche pas.
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
Je pense qu'il faut spécifier un cookie mais là je ne sais pas trop comment faire. J'ai cherché sur le net et j'ai trouvé des codes qui résolvent des situations pour d'autres API mais aucun tuto qui permette de les comprendre pour les adapter à mon cas présent
En utilisant l'inspecteur du navigateur, j'ai trouvé que cette requête web utilise un cookie dans les request headers mais je ne suis pas assez calé pour savoir comment lui générer ce cookie par le code. J'ai bien tattoné avec ceci mais le cookie_dict renvoie une chaine nulle
Bref, si vous pouvez m'aider à trouver la solution, voire mieux, m'orienter vers un tuto qui permette de trouver la solution adaptée à n'importe quelle API, ce serait super.
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
 Répondre avec citation
Répondre avec citation












 !==
!==  :
:  ;
;





Partager