











Des chercheurs ont donné à l'IA un "monologue intérieur" qui a permis d'améliorer considérablement ses performances : Quiet-STaR, les modèles de langage peuvent apprendre à réfléchir avant de parler.
Les scientifiques ont entraîné un système d'IA à réfléchir avant de parler grâce à une technique appelée Quiet-STaR. Le monologue intérieur a permis d'améliorer le raisonnement de bon sens et de doubler les performances en mathématiques.
De nouvelles recherches montrent que le fait de donner un "monologue intérieur" aux systèmes d'intelligence artificielle (IA) leur permet d'améliorer considérablement leur capacité de raisonnement. Cette méthode permet d'entraîner les systèmes d'IA à réfléchir avant de répondre à des messages, de la même manière que de nombreuses personnes réfléchissent à ce qu'elles vont dire avant de parler. Cette méthode diffère de celle utilisée par les scientifiques pour former les principaux chatbots, tels que ChatGPT, qui ne "réfléchissent" pas à ce qu'ils écrivent et n'anticipent pas les différentes possibilités pour les étapes suivantes d'une conversation.
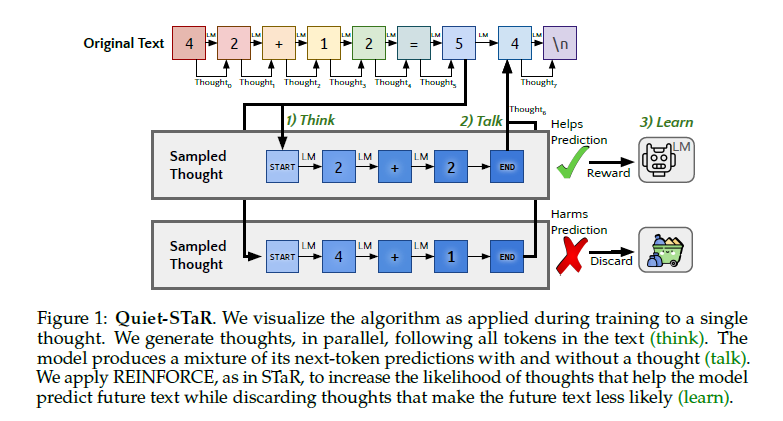
Baptisée "Quiet-STaR", la nouvelle méthode demande à un système d'IA de générer de nombreuses justifications internes en parallèle avant de répondre à une demande de conversation. Lorsque l'IA répond à des questions, elle génère un mélange de ces prédictions avec et sans justification, en imprimant la meilleure réponse - qui peut être vérifiée par un participant humain en fonction de la nature de la question. Enfin, elle apprend en écartant les justifications qui se sont révélées incorrectes. En fait, la méthode de formation donne aux agents d'IA la capacité d'anticiper les conversations futures et d'apprendre des conversations en cours.
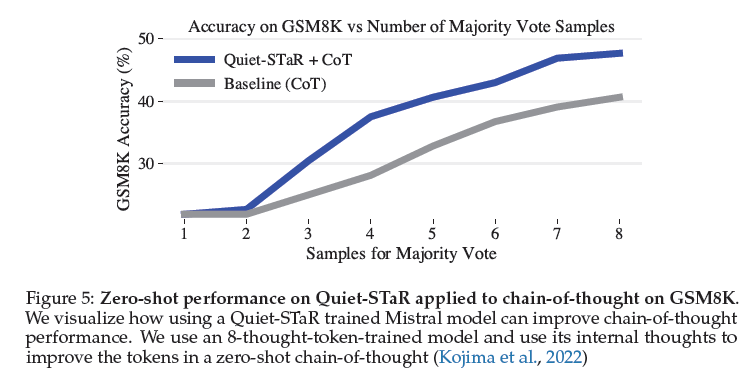
Les chercheurs ont appliqué l'algorithme Quiet-STaR à Mistral 7B, un grand modèle de langage (LLM) open-source, et ont publié les résultats le 14 mars dans la base de données de pré-impression arXiv. La version de Mistral 7B entraînée par Quiet-STaR a obtenu un score de 47,2 % à un test de raisonnement, contre 36,3 % avant tout entraînement. Elle a néanmoins échoué à un test de mathématiques scolaires, obtenant un score de 10,9 %. Mais c'est presque le double du score de départ de 5,9 % de la version vanille.
Les modèles tels que ChatGPT et Gemini sont construits à partir de réseaux neuronaux - des collections d'algorithmes d'apprentissage automatique organisés de manière à imiter la structure et les modèles d'apprentissage du cerveau humain. Cependant, les systèmes construits sur la base de cette architecture sont incapables de raisonner avec bon sens ou de contextualiser, et les chatbots d'IA n'ont pas de véritable "compréhension".
Les tentatives passées d'amélioration des capacités de raisonnement des LLM étaient très spécifiques à un domaine et ne pouvaient pas être appliquées à différents types de modèles d'IA. L'algorithme de raisonnement autodidacte (STaR), que les chercheurs ont utilisé comme base de leurs travaux, est un exemple de ce type d'algorithme d'apprentissage, mais il est freiné par ces limitations.
Les scientifiques qui ont développé Quiet-STaR l'ont appelé ainsi parce que les principes de STaR peuvent être appliqués discrètement en arrière-plan et généralement sur plusieurs types différents de LLM, indépendamment des données de formation originales. Ils souhaitent à présent étudier comment des techniques comme les leurs peuvent réduire l'écart entre les systèmes d'IA basés sur les réseaux neuronaux et les capacités de raisonnement semblables à celles de l'homme.
Quiet-STaR : les modèles de langage peuvent apprendre à réfléchir avant de parler
Lorsque l'on écrit ou que l'on parle, il arrive que l'on s'arrête pour réfléchir. Bien que les ouvrages axés sur le raisonnement aient souvent présenté le raisonnement comme une méthode permettant de répondre à des questions ou d'accomplir des tâches agentiques, le raisonnement est implicite dans la quasi-totalité des textes écrits. Cela s'applique par exemple aux étapes non énoncées entre les lignes d'une preuve ou à la théorie de l'esprit sous-jacente à une conversation.
Dans le raisonneur autodidacte, on apprend à raisonner utilement en déduisant des raisonnements à partir de quelques exemples de réponses à des questions et en tirant des enseignements de ceux qui conduisent à une réponse correcte. Il s'agit d'un cadre très contraint - idéalement, un modèle de langage pourrait apprendre à déduire des justifications non formulées dans un texte arbitraire.
Les chercheurs résument l'étude en écrivant :
Il est encourageant de constater que les justifications générées aident de manière disproportionnée à modéliser les jetons difficiles à prédire et améliorent la capacité du LM à répondre directement aux questions difficiles. En particulier, après un pré-entraînement continu d'un LM sur un corpus de texte Internet avec Quiet-STaR, les chercheurs ont constaté des améliorations sur GSM8K (5,9%→10,9%) et CommonsenseQA (36,3%→47,2%) et ont observé une amélioration de la perplexité des mots-clés difficiles dans le texte naturel. De manière cruciale, ces améliorations ne requièrent aucun ajustement sur ces tâches.Nous présentons Quiet-STaR, une généralisation de STaR dans laquelle les LM apprennent à générer des justifications à chaque jeton pour expliquer le texte futur, améliorant ainsi leurs prédictions. Nous relevons des défis majeurs, notamment 1) le coût informatique de la génération de continuations, 2) le fait que le LM ne sache pas initialement comment générer ou utiliser des pensées internes, et 3) la nécessité de prédire au-delà des prochains tokens individuels. Pour résoudre ces problèmes, nous proposons un algorithme d'échantillonnage parallèle par jeton, utilisant des jetons apprenables indiquant le début et la fin d'une pensée, ainsi qu'une technique étendue de forçage de l'enseignant.
Conclusion
Quiet-STaR représente une étape vers des modèles de langage capables d'apprendre à raisonner de manière générale et évolutive. En s'entraînant sur le riche spectre des tâches de raisonnement implicites dans divers textes web, plutôt que de se spécialiser étroitement pour des ensembles de données particuliers, Quiet-STaR ouvre la voie à des modèles de langage plus robustes et adaptables.
Les résultats de cette étude démontrent la promesse de cette approche, Quiet-STaR améliorant les performances de raisonnement en aval tout en générant des raisonnements qualitativement significatifs. Cela pourrait ouvrir également la voie à de nombreuses orientations futures potentielles - par exemple, on pourrait chercher à regrouper les pensées afin d'améliorer encore les prédictions pour les éléments futurs.
En outre, si le modèle de langage peut prédire quand la pensée sera utile, par exemple en plaçant la tête de mélange avant la prédiction, alors le poids de mélange prédit pourrait être utilisé pour allouer dynamiquement le calcul pendant la génération. Les travaux futurs peuvent s'appuyer sur ces idées pour combler le fossé entre le modèle de langage et les capacités de raisonnement semblables à celles de l'homme.
Source : "Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking"
Et vous ?
Pensez-vous que les résultats de cette étude sont crédibles ou pertinents ?
Voir aussi :
 Répondre avec citation
Répondre avec citation
Partager