










Bonsoir,
J'avais demandé de l'aide sur ce site il y a déjà quelques années, avec de très bons retours et une bonne expérience. Je retente donc ma chance
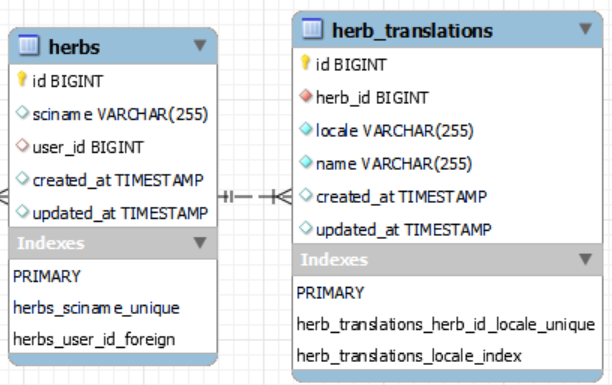
Imaginez une table herbs contenant environ 300.000 enregistrements et ne seconde table herb_translations, contenant environ 1.000.000 enregistrements :
Désormais pour les requêtes...
Sélectionner les 20 premières herbes, triées par le nom de manière alphabétique, contenant une traduction FR :
Aucun problème, cela passe à 100% via les INDEX.
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
Le problème : sélectionner les 20 premières herbes, triées par le nom de manière alphabétique, contenant une traduction FR, ET SI NON, renverra null pour le nom :
Ici cela ne fonctionne plus, c'est beaucoup beaucoup trop long, car il passe par filesort et non plus les index. Ce qui est normal sur papier mais pose problème, car je dois bien souvent afficher par ordre alphabétique dans une langue (et avoir la plante même s'il n'y a pas de traduction dans la langue demandée).
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
Quelqu'un aurait une idée, une parade, quelque chose ?
Merci d'avance pour vos avis éclairés,
Belle fin de journée à tous.
 Répondre avec citation
Répondre avec citation
Partager