
















Polars, la bibliothèque de frameworks de données pour Python, évolue de la version 0.19.0 à 0.20,
elle utilise Rust pour le moteur de requête et apporte le type de données Enum
Polars est une bibliothèque de frameworks de données conçue pour offrir des performances optimales dans le traitement des données. Son moteur de requête multithread, écrit en Rust, favorise un parallélisme efficace, tandis que son traitement vectoriel et en colonnes assure des algorithmes cohérents avec le cache et des performances élevées sur les processeurs modernes. La conception intuitive de ses expressions facilite l'écriture de code lisible et performant, rendant l'utilisation de Polars accessible aux utilisateurs familiarisés avec la manipulation de données.
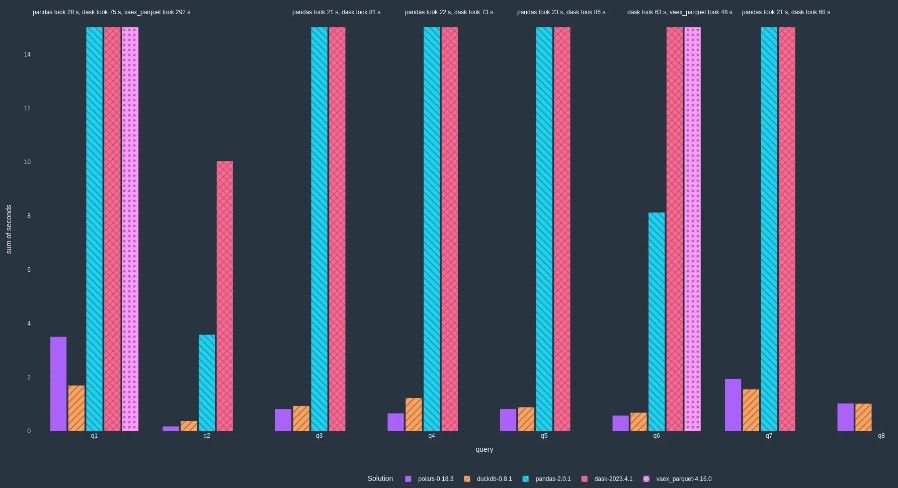
Polars présente des caractéristiques attrayantes, telles que sa conception axée sur la performance, son traitement multithread et sa facilité d'utilisation. Le choix d'utiliser Rust pour le moteur de requête contribue à la robustesse du système. La comparaison avec d'autres solutions sur le benchmark TPCH met en avant ses avantages significatifs en termes de rapidité d'exécution, surpassant même des bibliothèques populaires comme pandas. Cependant, il serait intéressant de surveiller l'évolution de Polars au fil du temps, notamment en termes de croissance de la communauté et d'ajout de nouvelles fonctionnalités.
Toutefois, une évaluation plus poussée pourrait mettre en lumière certaines lacunes potentielles. Tout d'abord, bien que Polars se targue de sa rapidité sur le benchmark TPCH, il est important de noter que les performances peuvent varier en fonction du contexte d'utilisation réel et des types de données spécifiques. Les résultats d'un benchmark isolé ne sont pas toujours représentatifs de toutes les situations.
De plus, bien que l'accent soit mis sur la facilité d'utilisation, la courbe d'apprentissage peut donc être plus abrupte pour ceux qui ne sont pas déjà familiarisés avec la manipulation de données. Un autre aspect à considérer est la taille de la communauté des développeurs. Une communauté plus restreinte peut entraîner des retards dans les mises à jour, des problèmes de support technique et un manque de diversité dans le développement de nouvelles fonctionnalités. Il serait donc crucial de suivre l'évolution de la communauté autour de Polars pour garantir une croissance soutenue.
Les utilisateurs potentiels devraient évaluer attentivement leurs besoins spécifiques et surveiller de près l'évolution continue de Polars avant de choisir cette bibliothèque pour des applications critiques.
Polars a été comparé à plusieurs autres solutions sur l'échelle de référence TPCH facteur 10. Les benchmarks ont été exécutés sur un gcp n2-highmem-16. Il s'agit encore d'un travail en cours et d'autres requêtes/bibliothèques seront bientôt disponibles. Le benchmark TPCH initial est conçu pour les bases de données SQL et ne permet aucune modification du SQL associé à cette question spécifique. Les interfaces SQL sont évaluées par rapport aux interfaces DataFrame, nécessitant ainsi des ajustements mineurs des règles initiales. Il est nécessaire de traduire les requêtes SQL de manière sémantique en requêtes idiomatiques adaptées à l'outil hôte. Pour accomplir cette tâche, l'équipe de Polars a observé et suivi scrupuleusement les règles énoncées ci-dessous :
- il n'est pas permis d'insérer de nouvelles opérations, par exemple pas d'élagage d'une table avant une jointure ;
- chaque solution doit fournir une requête par question, indépendamment de la source de données et solution doit appeler sa propre API ;
- elle est autorisée à déclarer le type de jointures, car cela correspond au raisonnement sémantique des API DataFrame ;
- une solution doit choisir un seul moteur/mode pour toutes les requêtes. Il est permis de proposer différentes solutions du même fournisseur, par exemple (sparks-sql, pyspark, polars-sql, polars-default, polars-streaming). Cependant, ces solutions doivent exécuter toutes les requêtes, en montrant leurs forces et leurs faiblesses, pas de "cherry picking".
Type de données Enum
La version 0.20.0 introduit le type de données Enum, une nouvelle façon de traiter les données catégorielles. Il garantit un encodage cohérent entre les colonnes ou les ensembles de données, ce qui rend les opérations telles que l'ajout ou la fusion plus efficaces sans nécessiter de réencodage ou de recherches supplémentaires dans le cache.
Ce type de données est différent du type Categorical, qui peut entraîner des coûts de performance dus à l'inférence des catégories. Toutefois, il est important de noter que le type Enum ne permet d'utiliser que des catégories prédéfinies et que toute valeur non spécifiée entraînera des erreurs. Enum est une option fiable pour les ensembles de données dont les valeurs catégorielles sont connues, ce qui améliore les performances lors de la manipulation des données. Exemples d'utilisation du nouveau type Enum :
Example 1
Example 2
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
Polar Plugins
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
Les plugins d'expression ont fait leur entrée. Ils vous permettent de compiler une UDF (fonction définie par l'utilisateur) en Rust et de l'enregistrer en tant qu'expression dans le binaire principal de Python Polars. Le binaire principal de Python Polars appellera la fonction via FFI. Cela signifie que vous aurez les performances de Rust et tout le parallélisme du moteur Polars car il n'y a pas de verrouillage GIL.
Un autre avantage est que vous pouvez utiliser toutes les caisses disponibles dans le paysage Rust pour accélérer votre logique d'entreprise.
Accélérations algorithmiques
Polars apporte de nombreuses améliorations liées aux performances. Voici, ci-dessous, le script pour exécuter le benchmark :
Polars vise à créer une API cohérente, expressive et lisible. Cependant, cela peut être en contradiction avec l'écriture d'un code interactif rapide - par exemple, lors de l'exploration de données dans un carnet de notes.
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
L'équipe de développement de Polars a récemment annoncé la transition de la version 0.19.0 à la version 0.20, introduisant le type de données Enum. Bien que Polars soit vanté comme une bibliothèque de frameworks de données offrant des performances optimales, plusieurs points critiques méritent d'être examinés de plus près.
Entre promesses et réalités : un regard prudent sur Polars
Bien que le moteur de requête multithread de Polars, rédigé en Rust, soit loué pour son parallélisme efficace et que son traitement vectoriel en colonnes garantisse des performances élevées, il est important de souligner que les résultats obtenus sur le benchmark TPCH ne sont pas nécessairement représentatifs de toutes les situations réelles. Les performances peuvent varier en fonction du contexte d'utilisation et des types de données spécifiques, remettant en question la fiabilité de l'évaluation basée sur un benchmark isolé.
Malgré la conception intuitive de Polars qui facilite l'écriture de code lisible et performant, la courbe d'apprentissage peut s'avérer abrupte pour les utilisateurs non familiers avec la manipulation de données. Cette caractéristique pourrait poser des obstacles à l'adoption de Polars pour ceux cherchant une solution conviviale et rapide pour l'exploration de données dans un carnet de notes, où l'aspect interactif est essentiel.
Un autre point de préoccupation réside dans la taille de la communauté des développeurs autour de Polars. Une communauté plus limitée pourrait entraîner des retards dans les mises à jour, des problèmes de support technique et un manque de diversité dans le développement de nouvelles fonctionnalités. La croissance continue de la communauté devrait donc être surveillée attentivement pour assurer la pérennité du projet.
Source : Polars
Et vous ?
Quel est votre avis sur le sujet ?
Voir aussi :

 Répondre avec citation
Répondre avec citation




Partager