











LLM par taux d'hallucinations : GPT-4 est le modèle de langage IA qui hallucine le moins, d'après une évaluation de Vectara
qui suggère que les LLM de Google sont les moins fiables
Les modèles de langage à grande échelle (LLM) sont capables de générer du texte sur nimporte quel sujet, mais ils sont aussi susceptibles dintroduire des informations fausses ou inventées, appelées hallucinations. Pour évaluer la performance des LLM à éviter les hallucinations, une entreprise nommée Vectara a créé un modèle dévaluation des hallucinations et un classement public des LLM les plus fiables.
Passez suffisamment de temps avec ChatGPT et d'autres chatbots d'intelligence artificielle et il ne leur faudra pas longtemps pour débiter des mensonges.
Décrit comme une hallucination, une confabulation ou simplement une invention, c'est maintenant un problème pour chaque entreprise, organisation et lycéen essayant d'obtenir d'un système d'IA générative de la documentation pour un travail donné. Certains l'utilisent pour des tâches pouvant avoir des conséquences importantes, de la psychothérapie à la recherche et à la rédaction de mémoires juridiques.
Les hallucinations sont le résultat du fonctionnement de ChatGPT, qui consiste à prédire des chaînes de mots qui correspondent le mieux à la requête de lutilisateur, sans tenir compte de la logique ou des incohérences factuelles. En dautres termes, lIA peut parfois dérailler en essayant de satisfaire lutilisateur. Par exemple, ChatGPT peut affirmer que la capitale de la France est Berlin, ou que le président des États-Unis est Donald Trump, sans vérifier la véracité de ces informations.
Ce problème nest pas propre à ChatGPT, mais affecte tous les modèles de langage de grande taille (LLM), qui sont entraînés sur dénormes quantités de données textuelles provenant du web. Ces données peuvent être incomplètes, biaisées, obsolètes ou erronées, ce qui limite la fiabilité des LLM. De plus, les LLM ne comprennent pas vraiment le sens des mots quils produisent, mais se basent sur des statistiques et des probabilités pour générer du texte.
« Je ne pense pas qu'il existe aujourd'hui un modèle qui ne souffre pas d'hallucinations », a déclaré Daniela Amodei, co-fondatrice et présidente d'Anthropic, fabricant du chatbot Claude 2. « Ils sont vraiment conçus en quelque sorte pour prédire le mot suivant », a continué Amodei. « Et donc il y aura un certain rythme auquel le modèle le fera de manière inexacte ».
Mais quel LLM en souffre le plus ?
C'est la question à laquelle a tenté de répondre Vectara, qui a créé un modèle dévaluation des hallucinations et établit un classement public des LLM les plus fiable.
Le modèle dévaluation des hallucinations de Vectara est basé sur des données provenant de la recherche sur la cohérence factuelle des modèles de résumé automatique. Il sagit dun modèle compétitif avec les meilleurs modèles de létat de lart, qui peut détecter les hallucinations dans les sorties des LLM, en les comparant avec le document source. Le modèle est disponible en open source sur hugging face.
Au sujet de la méthodologie, Vectara explique :
Pour établir le classement, Vectara a envoyé 1000 documents courts à chaque LLM via leurs API publiques et leur a demandé de résumer chaque document, en utilisant uniquement les faits présentés dans le document. Parmi ces 1000 documents, seuls 831 documents ont été résumés par tous les modèles, les documents restants ayant été rejetés par au moins un modèle en raison de restrictions de contenu. En utilisant ces 831 documents, Vectara a ensuite calculé le taux de précision (pas dhallucinations) et le taux dhallucination (100 - précision) pour chaque modèle. Le taux auquel chaque modèle refuse de répondre à la consigne est détaillé dans la colonne Taux de réponse. Aucun des contenus envoyés aux modèles ne contenait de contenu illicite ou non adapté au travail, mais la présence de mots déclencheurs était suffisante pour activer certains des filtres de contenu. Les documents provenaient principalement du corpus CNN / Daily Mail.Ce modèle a été formé à l'aide de la classe SentenceTransformers Cross-Encoder. Le modèle génère une probabilité de 0 à 1, 0 étant une hallucination et 1 étant factuellement cohérent. Les prédictions peuvent être seuillées à 0,5 pour prédire si un document est cohérent avec sa source.
Données d'entraînement
Ce modèle est basé sur Microsoft/Deberta-v3-base et est initialement formé sur les données NLI pour déterminer l'implication textuelle, avant d'être affiné davantage sur des ensembles de données de synthèse avec des échantillons annotés pour une cohérence factuelle, notamment FEVER, Vitamin C et PAWS.
Pourquoi un résumé d'un document plutôt qu'un test sur des exactitudes factuelles plus générales ?
L'entreprise explique que cela lui permet de comparer la réponse du modèle aux informations fournies.
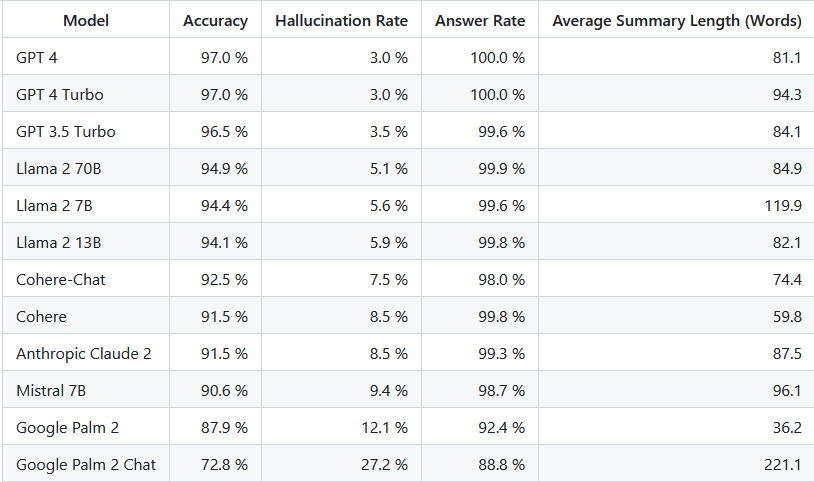
GPT-4 domine le classement des LLM qui hallucinent le moinsEn d'autres termes, le résumé fourni est-il « factuellement cohérent » avec le document source. Il est impossible de déterminer les hallucinations pour une question ponctuelle, car on ne sait pas précisément sur quelles données chaque LLM est formé. De plus, disposer d'un modèle capable de déterminer si une réponse a été hallucinée sans source de référence nécessite de résoudre le problème des hallucinations et vraisemblablement de former un modèle aussi grand ou plus grand que ces LLM évalués. Nous avons donc plutôt choisi dexaminer le taux dhallucinations dans le cadre de la tâche de synthèse, car il sagit dun bon analogue pour déterminer la véracité globale des modèles. De plus, les LLM sont de plus en plus utilisés dans les pipelines RAG (Retrieval Augmented Generation) pour répondre aux requêtes des utilisateurs, comme dans Bing Chat et l'intégration du chat de Google. Dans un système RAG, le modèle est déployé comme résumé des résultats de recherche, ce classement est donc également un bon indicateur de la précision des modèles lorsqu'ils sont utilisés dans les systèmes RAG.
Au sujet de GPT-4 Turbo, l'entreprise explique :
Nous pouvons voir que les modèles GPT sont les plus précis, suivis par les modèles Llama et Cohere. Les modèles Google Palm et Google Palm-Chat sont les moins précis et ceux qui sont les plus sujets aux hallucinations. Les modèles qui produisent des résumés plus longs ont tendance à avoir un taux dhallucination plus élevé que les modèles qui produisent des résumés plus courts.Bien que les chiffres ci-dessus montrent qu'il est comparable à GPT4, cela est dû au fait que nous avons filtré certains documents que certains modèles refusent de résumer. Lorsque l'on compare à GPT 4 sur tous les résumés (les deux modèles GPT4 résument tous les documents), le modèle turbo est environ 0,3*% moins bon que GPT4, mais toujours meilleur que GPT 3.5 Turbo.
Ce classement est intéressant car il montre la capacité des LLM à produire des textes fidèles aux sources dinformation. Il peut être utile pour les utilisateurs qui veulent utiliser les LLM pour des tâches de résumé automatique ou de génération de contenu. Il peut aussi être un moyen dinciter les développeurs de LLM à améliorer la qualité de leurs modèles et à réduire les hallucinations.
Les entreprises tentent d'endiguer le problème
Les développeurs de ChatGPT et dautres LLM affirment quils travaillent à rendre leurs systèmes plus véridiques. Ils utilisent différentes techniques pour détecter et corriger les hallucinations, comme lintroduction de sources externes de connaissances, la vérification croisée des faits ou lutilisation de signaux de rétroaction des utilisateurs. Cependant, ces solutions ne sont pas parfaites et peuvent introduire dautres problèmes, comme la complexité, le coût ou la manipulation.
Certains experts en technologie sont sceptiques quant à la possibilité déliminer complètement les hallucinations des LLM. Ils soutiennent que cest une conséquence inévitable du décalage entre la technologie et les cas dutilisation proposés. « Ce n'est pas réparable », a déclaré Emily Bender, professeur de linguistique et directrice du laboratoire de linguistique informatique de l'Université de Washington. « C'est inhérent à l'inadéquation entre la technologie et les cas d'utilisation proposés ».
Ces experts mettent en garde contre les risques potentiels des hallucinations pour la sécurité, léthique ou la crédibilité des applications basées sur les LLM, comme les chatbots, la rédaction darticles, la génération de code ou le conseil médical.
Dautres experts sont plus optimistes et considèrent les hallucinations comme une opportunité dinnovation et de créativité. Ils affirment que les LLM peuvent produire des idées nouvelles et originales qui peuvent inspirer ou divertir les utilisateurs.
Cependant, beaucoup dépend de la fiabilité de la technologie d'IA générative. Le McKinsey Global Institute prévoit qu'il ajoutera l'équivalent de 2,6 billions (1 billion étant 1 000 milliards) de dollars à 4,4 billions de dollars à l'économie mondiale. Les chatbots ne sont qu'une partie de cette frénésie, qui comprend également une technologie capable de générer de nouvelles images, vidéos, musiques et codes informatiques. Presque tous les outils incluent une composante linguistique.
Google propose déjà un produit d'IA pour la rédaction d'actualités aux agences de presse, pour lesquelles la précision est primordiale. L'Associated Press explore également l'utilisation de la technologie dans le cadre d'un partenariat avec OpenAI, qui paie pour utiliser une partie des archives de texte d'AP pour améliorer ses systèmes d'IA.
Sources : résultats, modèle d'évaluation
Et vous ?
Que pensez-vous de la méthodologie de l'entreprise pour déterminer les LLM qui sont le plus sujets à des hallucinations ? La trouvez-vous crédible ?
Quelles sont les applications pratiques des modèles de langage qui évitent les hallucinations ? Quels sont les domaines où la précision est primordiale ?
Voir aussi :
 Répondre avec citation
Répondre avec citation
Partager