









Bonsoir,
J'ouvre cette discussion car j'ai un problème de ralentissement lors de l'exécution et la récupération des données d'une requête sur le serveur.
Nous avons notre propre serveur OVH, avec HFSQL C/S.
Je bosse sur une CRM et une fonctionnalité permet de rechercher une liste de contact selon un critère choisi par l'utilisateur. La liste de contact s'affiche dans une table où j'affiche quelques données de base des contacts (Nom, prénom etc.), le numéro de téléphone fixe par défaut, le numéro de mobile par défaut, l'email par défaut et la société.
Les données de base se trouvent dans la table Contact.
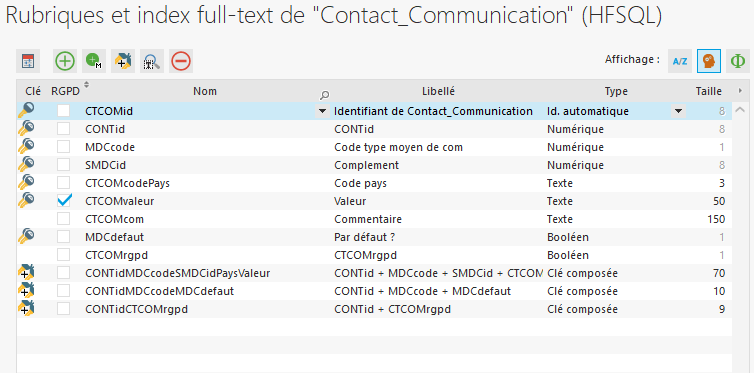
Les données téléphone fixe, téléphone mobile et email se trouve dans une table Contact_Communication.
La table Contact_Communication est construite de la façon suivante :
CTCOMid : Clé primaire table Contact_Communication
CNTid : Clé étrangère de la table Contact.
MDCcode : Entier et clé avec doublon -> code du support de communication (1 = téléphone fixe, 2 = téléphone mobile, 3 = email)
CTCOMcodePays : Chaine, code du pays pour les numéros de téléphone.
CTCOMvaleur : Chaine. Valeur selon le support de communication choisi. (Le numéro de téléphone, l'email...)
CTCOMdefaut : Booléen et clé avec doublon -> 1 défaut par code support de communication par contact. (Donc chaque contact peut avoir un tél fixe, un tél mobile et un e-mail par défaut maximum.)
Je récupère donc les données de base du contact (table contact) et le téléphone fixe, téléphone mobile et email par défaut des contacts (Chacun étant présent dans la table Contact_Communication) via l'unique requête suivante :
Code SQL : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
La requête possède une triple jointure avec alias sur la table Contact_Communication afin de récupérer le téléphone fixe par défaut, le téléphone mobile par défaut et l'email par défaut en une seule ligne afin de les afficher chacun dans une colonne distincte de ma table des résultats de la recherche.
La requête fonctionne et est assez rapide. Pour 50 000 contacts, avec chacun un téléphone fixe, téléphone mobile et email par défaut (Donc 150 000 lignes dans la table Contact_communication) la durée de la requête ne dépasse pas 15 secondes.
Le vrai problème c'est que lorsque j'exécute la requête (sur les 50k contacts pour l'exemple) qui prend une quinzaine de seconde, les autres requêtes des autres utilisateurs sont ralenties, toutes bases confondues sur le serveur HFSQL CS OVH. C'est à dire que si un autre utilisateur exécute la même requête pendant que la mienne est en cours, même sur une base différente (mais du même serveur HFSQL CS), la sienne prends une dizaine de seconde de plus, les autres requêtes étant également impactées, tant que les requêtes de 15 secondes ne sont pas terminées. Une fois celles-ci terminées, plus de soucis de ralentissement.
Je ne sais pas d'où vient le problème, ma requête n'est peut-être pas la plus optimisée du monde, mais au point de faire ralentir les requêtes des autres utilisateurs, ça me parait excessif non ? C'est comme-ci le réseau était saturé pendant la récupération des données et du coup tous les autres requêtes sur le serveur, même sur des bases différentes, sont impactées.
Auriez-vous des pistes d'où pourrait venir le problème ?
La triple jointure de ma requête SQL sur la même table ? Au point de ralentir tout le serveur ? (Les rubriques CONTid, MDCcode et CTCOMdefaut de ma table Contact_Communication sont toutes en clés avec doublon, j'ai également créé une clé composé CONTid + MDCcode + CTCOMdefaut afin d'optimiser les jointures de la requête SQL mais je ne sais pas si elle est réellement utilisée...)
Ou le problème viendrait du serveur ? Ou autre ?
Merci d'avance...
Bonne soirée,
Djsven
 Répondre avec citation
Répondre avec citation










Partager