














Bonjour ç tous,
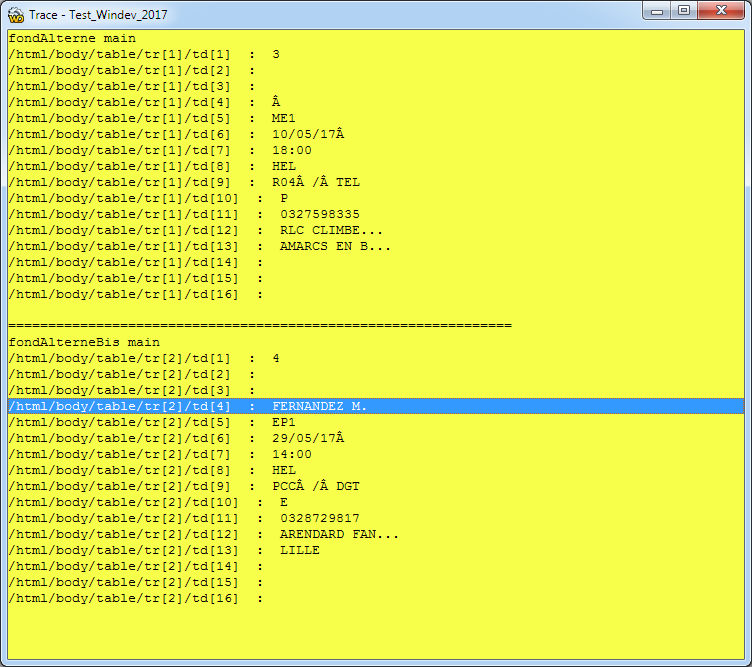
Je voudrais savoir par quoi je dois commencer afin de réaliser une petite app qui sert à extraire des données existent sur une table dans une page web .html.
J'ai cherché un peu j'ai trouvé des trucs lié au XML et non pas au HTML.
Plan :
- Parcourir les lignes du fichier .html
- Chercher la table et stocker les <TR> <TD> .. dans une table puis l'extraire dans un fichier XL.
Merci d'avance.
 Répondre avec citation
Répondre avec citation
















Partager