








Bonjour
J'avais du temps à perdre les jours pluvieux, aussi j'ai décidé de m'intéresser depuis quelques semaines aux algorithmes induits par l'intelligence artificielle : analyse sémantique, systèmes multi-agents et réseaux de neurone. Il y a dans tout cela beaucoup de choses qui pourraient améliorer la façon dont sont traitées les données dans les systèmes que j'ai développé ici ou là. La théorie ça m'inspire
bref, je me suis amusé à étudier plus particulièrement les réseaux de neurones et à implémenter quelques applications à partir d'un perceptron simple. Jusque là tout va bien : traiter des données linéairement séparables par un hyperplan, c'est assez facile et ça marche bien. Même avec des matrices de très grande taille, je parviens à parfaitement entrainer mon perceptron y compris en ajoutant du bruit aux exemples que je lui soumets.
Je me suis ensuite attaqué au problème plus complexe des réseaux de neurones multi-couches. J'ai développé un programme qui permet d'implémenter des réseaux avec une topologie variable : un nombre illimité de couches et autant de neurones par couche que l'on veut. Il peut utiliser n'importe quelle type de fonction d'activation, seuil, sigmoïde, tangeante hyperbolique, ... et les fonctions d'activations peuvent même varier entre les couches (utiliser heaviside sur la couche de sortie par exemple). La rétro-propagation de l'erreur se fait par descente du gradient stochastique. J'ai développé ça en ruby (sorte de python); le code est moins rapide que java ou C mais plus facile à mettre en oeuvre. Le temps de calcul pour 30000 itérations sur une topologie [10,20,25,1] et 25 variables par neurone en entrées sur la première couche, est d'environ 2 minutes... dans l'absolu, je dirais que ça marche.
J'en viens à ma question: Même si le réseau semble pouvoir être entraîné sur quelques figures simples (des lettres de l'alphabet par exemple); j'ai l'impression qu'il diverge beaucoup ou plutôt qu'il ne converge pas suffisamment. Quelque soit le pas d'apprentissage que j'utilise (je l'ai même rendu variable de sorte qu'il diminue avec les itérations et évite au système d'osciller si on part avec un pas trop grand) je n'obtiens pas les résultats escomptés. Je ne parviens pas à entrainer le perceptron sur une fonction booléenne de type "et" ou "ou", encore moins sur le "ou exclusif" alors que cela devrait théoriquement marcher avec seulement deux neurones (et que pour les deux premières, ça fonctionne sur mon perceptron simple).
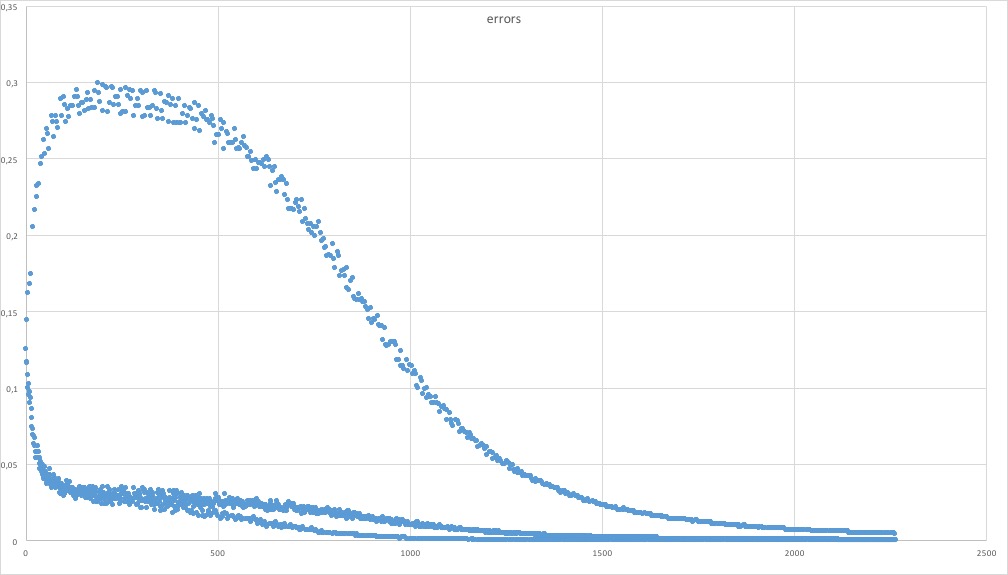
Lorsque je trace la courbe représentative des erreurs quadratiques en sortie, sur la fonction "or", ça ne converge vraiment qu'au dessus de 1500 itérations ce qui me parait énorme pour l'apprentissage de 4 valeurs qui nécessitent un ou deux tours sur un perceptron simple
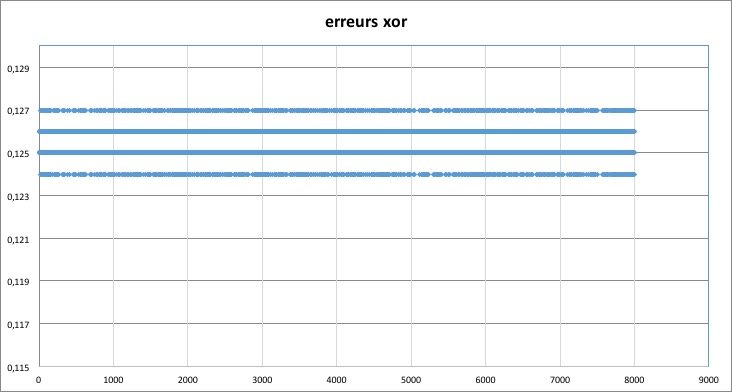
Pour la fonction xor, c'est pire; j'ai une erreur constante qui oscille entre 0.124 et 0.125 (j'arrondis à 10-3) mais ne diminue pas.
Je suis un peu coincé car je ne dispose pas de jeu de données avec lesquelles je puisse comparer mes résultats.
dans les deux exemples cités (xor et or) j'utilise une fonction d'activation sigmoïde, y compris sur le neurone de sortie.
J'ai également essayé avec une fonction heaviside(seuil) en sortie; ce n'est guère mieux et ça me pose un problème "éthique". En effet si mon calcul d'écart repose, sur la couche de sortie, sur une telle fonction, je rétro-propage systématiquement des valeurs +1 ou -1 ce qui me semble en contradiction avec la "finesse" d'une fonction sigmoïde.
une dernière chose me laisse perplexe. Il s'agit de la formule du calcul de l'écart du (ou des) neurone(s) de la couche de sortie. La littérature (à l'instar de mes données) diverge un peu sur ce point : doit-on ou non prendre en compte la dérivée de la fonction d'activation par rapport à la valeur de sortie ?
quel est le bon écart à rétro-propager sur les couches cachées :
delta =g'(o)*(o-t), sachant que dans le cas de la sigmoïde g'(o)=o(1-o) et que t est le résultat attendu en sortie du neurone
ou
delta =o-t
...et bien sûr o=g(somme (xiwi)+biais)
Je vous remercie d'avance infiniment pour toute l'aide que vous voudrez bien m'apporter. Je suis un peu néophyte sur le sujet, un peu de lumière me sauvera peut-être.
David
 Répondre avec citation
Répondre avec citation
Partager