









Bonjour,
Tout d'abord j'éspère ne pas m'être trompé en choisissant cette rubrique du forum pour ma question, si ce n'est pas le cas signalez le moi, je pourrai déplacer la discussion.
Voila mon problème est le suivant :
J'ai tout d'abord des données issues de simulation dont voici un court extrait :
1 1.63 0.52 9.26 314.03 0.90 0.14 7.25
1 1.58 0.53 8.72 268.09 0.91 0.15 7.13
1 1.53 0.55 8.21 229.63 0.91 0.16 7.03
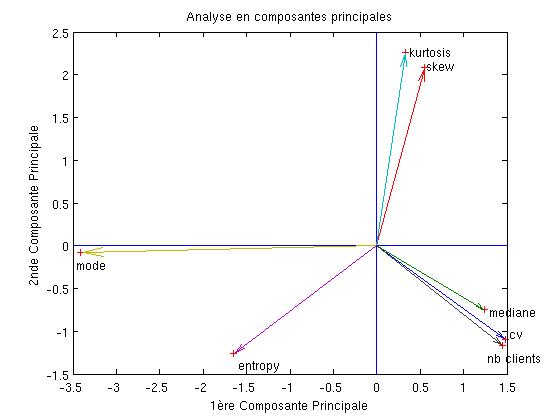
Les 7 premières colonnes sont des valeurs en entrée du système, la 8ème une sortie. Les 7 premieres sont assez liées car elles sont des caractèrisiques d'une variable aléatoire (respectivement moyenne, coefficient de variation, médiane, skewness, kurtosis, entropie et mode pour être précis).
Mon objectif est de conclure sur l'influence de chaque colonne sur le résultat final qui correspond au nombre moyen de clients dans le système.
Pour l'instant j'ai deux pistes :
1- Analyse PCA à partir de la matrice de corrélation entre l'ensemble des paramètres
- Je pense que c'est peu représentatif car cela nécessite une corrélation linéaire entre les paramètres et ce n'est pas le cas
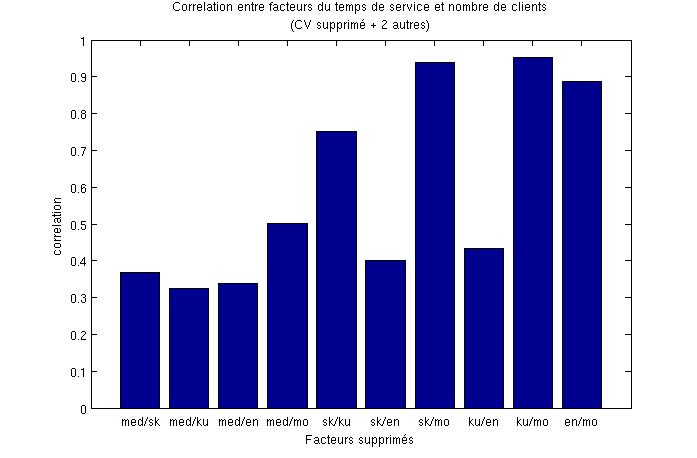
2- Analyse PCA en prenant des petits groupes de paramètres, réduction sur une seule composantes puis corrélation avec le nombre de clients moyen (Pearson, Spearman, exponentielle et puissance puis je prend le maximum des quatres)
Le graphe suivant montre la correlation en supprimant pour chaque valeur 3 paramètres (le CV + 2 autres) :
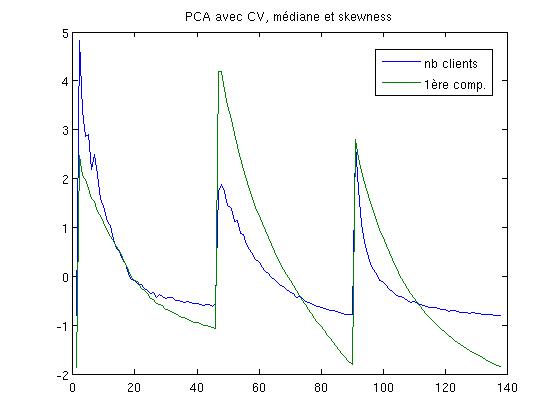
Ici un exemple des valeurs résultats avant calcul de la corrélation :
Ces deux pistes ne sont pas forcément les bonnes, j'aimerais donc savoir si je peux conclure quelque chose en suivant cette voie, et si éventuellement quelqu'un aurait une idée pour analyser ce type de valeur.
J'éspère avoir été court et à la fois assez claire, merci pour votre lecture et vos réponses.
Vincent
 Répondre avec citation
Répondre avec citation









Partager