









Bonjour à tous,
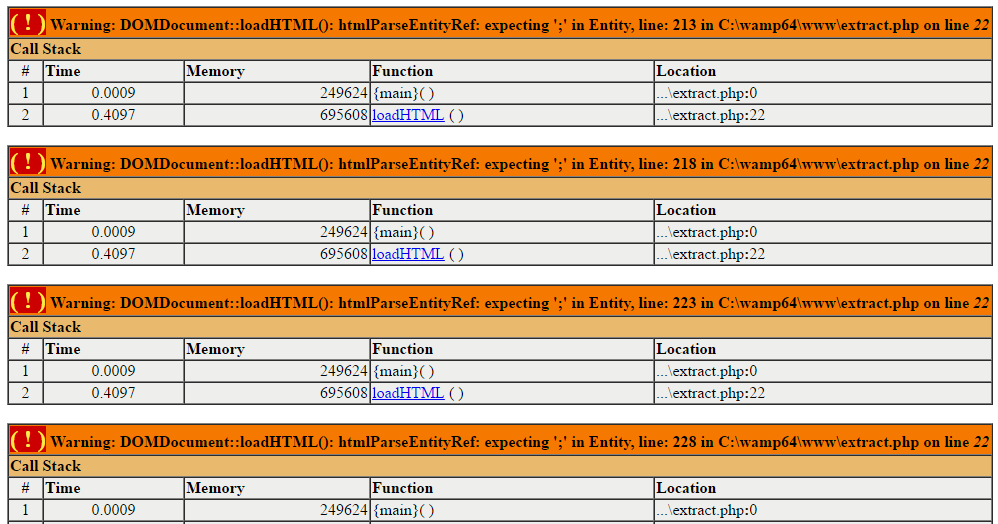
J'aimerai récupérer des infos sur le web afin de remplir une Bdd, voici ce que j'ai récupérer comme script sur le forum, mais j'ai une erreur:
Voici le code que j'utilise
Merci à vous pour vos éclaircissements
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
Seb
 Répondre avec citation
Répondre avec citation




Partager