1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
| Tab=read.table("Test2.csv",sep=";",h=F)
#Somme des valeurs de chaque pixel pour une Grande Unité (GU)
#Donne les effectifs par GU (de 1 a 12)
library(doBy) #Appel de la librairie pour réaliser le summaryBy
Someff<-summaryBy(V2~V1,data=Tab,FUN=sum)
#changement des noms des colonnes de Someff
names(Someff)<- c("V1","V2.eff")
#Effectif total (toutes GU)
Efftot <- colSums(Tab["V2"])
#Nombre de cases non vides par GU
Pixnv<-data.frame(Someff["V1"],"V2"=(25-table(Tab)[,1]))
names(Pixnv)<- c("V1","V2.NV")
#Séparation de chaque Grande unité (liste)
Tab.split <- split(Tab,as.factor(Tab$V1))
#Nombre d'élements à tirer
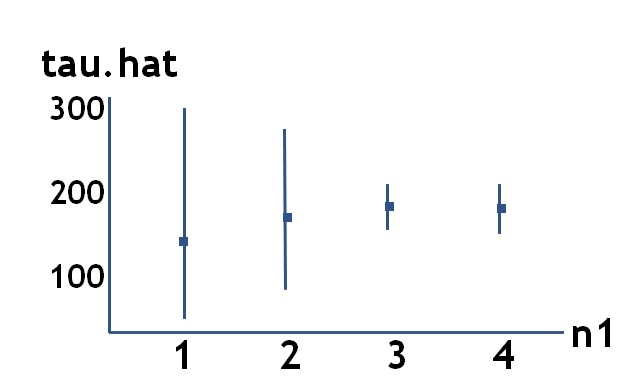
n1=3
#Tirage aléatoire parmi chaque GU
Tab.sample <- lapply(Tab.split,function(x) x<-x[sample(1:nrow(x),n1,replace=F),])
#Transformation en dataframe des listes obtenues après tirage aléatoire
Tab.sample.df<-do.call(rbind.data.frame, Tab.sample) #Obtention data frame avec les 3 valeurs tirées par GU
#Affichage du nombre de valeur supérieures à "0" par GU
Tabs.df<-summaryBy(V2~V1,data=Tab.sample.df,FUN=function(x) (sum(x > 0)))
#Changement des noms des colonnes du data frame
names(Tabs.df)<- c("V1.1","V2.1")
attach(Tabs.df)
#Compilation des data frame m et Som (via noms des GU)
#nouveau data frame avec somme des effectifs par GU et nombre valeurs
#positives avec tirage aléatoire de n1 valeurs
T1<-merge(Tabs.df, Someff , by.x = "V1.1", by.y = "V1")
#Compilation du data frame créé et data frame nombre pixels non vides par GU
#GU // Somme eff // Nombre de valeurs >0 parmi n1 // Nombre pixels non vides
Tab.merge<- merge(T1,Pixnv,by.x = "V1.1", by.y = "V1")
#Création data frame avec valeur de y (eff par GU)
d2<-data.frame(Someff["V1"],ifelse(Tab.merge[,2]>0, Tab.merge[,3], 0))
names(d2)<- c("V1","y")
#Création data frame avec valeur de mh (eff par GU)
d3<-data.frame(Someff["V1"],ifelse(Tab.merge[,2]>0, Tab.merge[,4], 0))
names(d3)<- c("V1","mh")
#Transformation des data frame en vecteur
d2.1<- as.vector(d2[,"y"])
d3.1<- as.vector(d3[,"mh"])
#Sélection des valeurs supérieures à 0
y <- d2.1[as.logical(lapply(d2.1,function(x) sum(x>0) > 0 ))]
mh <- d3.1[as.logical(lapply(d3.1,function(x) sum(x>0) > 0 ))]
#Formule de la Variable v
v<-sum(ifelse(Tab.merge["V2.1"]>0,1,0))
#Formule générale
N <- 12 #Nombre de GU
Nh <-25 #Nombre de mailles par strate
nh <- n1 #Nombre de mailles secondaires par strate
M <- v * Nh + (N-v) * nh #nombre de mailles échantillonnées
pik <- 1 - choose(Nh-mh,3)/choose(Nh,nh)
tauhat <- sum(y/pik) #estimation de la population totale (HT)
var.tauhat <- sum(((1-pik)*y^2)/(pik^2))
c(tauhat,sqrt(var.tauhat)) # Estimation du total et Ecart type
IC95<- c(tauhat-((1.96*sqrt(var.tauhat))/sqrt(M)), tauhat+((1.96*sqrt(var.tauhat))/sqrt(M))) |












 Répondre avec citation
Répondre avec citation

Partager