Stable Diffusion de Stability AI serait le modèle d'IA le plus important de tous les temps,
contrairement à GPT-3 et DALL-E 2, il apporte des applications du monde réel ouvertes pour les utilisateurs
Stability AI annonce la première étape de Stable Diffusion aux chercheurs. Les poids modèles sont hébergés par Hugging Face une fois l'accès obtenu. Stability.ai voulait construire une alternative à DALL-E 2, et ils auraient fini par faire beaucoup plus. Pour certains analystes, Stable Diffusion incarne les meilleures caractéristiques du monde de l'art de l'IA : « il s'agit sans doute du meilleur modèle d'art de l'IA open source existant. C'est tout simplement du jamais vu et cela aura des conséquences énormes », déclare lun dentre eux.
Stable Diffusion est un modèle de diffusion latente texte-image. Grâce à un généreux don de calcul de Stability AI et au soutien de LAION, les chercheurs ont pu entraîner un modèle de diffusion latente sur des images 512x512 provenant d'un sous-ensemble de la base de données LAION-5B. Similaire à Imagen de Google, ce modèle utilise un encodeur de texte CLIP ViT-L/14 gelé pour conditionner le modèle à des invites textuelles. Avec son UNet de 860M et son encodeur de texte de 123M, le modèle est relativement léger et fonctionne sur un GPU avec au moins 10 Go de VRAM.
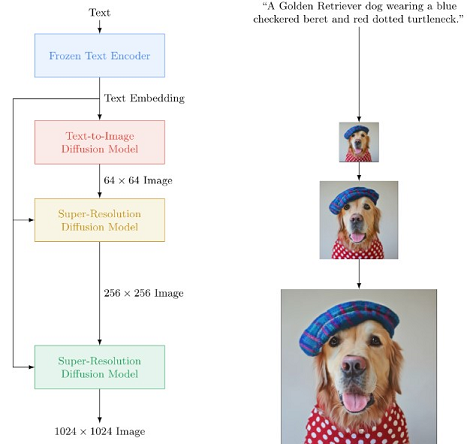
Notons quImagen de Google est un modèle de diffusion texte-image avec un degré de photoréalisme sans précédent et un niveau profond de compréhension du langage. Imagen s'appuie sur la puissance des grands modèles de langage transformateurs pour la compréhension du texte et s'appuie sur la force des modèles de diffusion pour la génération d'images haute-fidélité.
Sa principale découverte est que les grands modèles de langage génériques (par exemple T5), pré-entraînés sur des corpus de texte uniquement, sont étonnamment efficaces pour coder le texte pour la synthèse d'images : l'augmentation de la taille du modèle de langage dans Imagen améliore à la fois la fidélité de l'échantillon et l'alignement image-texte beaucoup plus que l'augmentation de la taille du modèle de diffusion d'image.
Imagen obtient un nouveau score FID de pointe de 7,27 sur le jeu de données COCO, sans jamais s'entraîner sur COCO, et les évaluateurs humains trouvent que les échantillons d'Imagen sont équivalents aux données COCO elles-mêmes en matière d'alignement image-texte. Avec Stable Diffusion, les poids sont disponibles par l'intermédiaire de l'organisation CompVis à Hugging Face sous une licence qui contient des restrictions spécifiques basées sur l'utilisation afin d'éviter une mauvaise utilisation et des dommages comme indiqué par le modèle de carte, mais reste autrement permissif.
Imagen utilise un énorme encodeur T5-XXL congelé pour encoder le texte d'entrée dans des incrustations. Un modèle de diffusion conditionnel mappe l'incorporation du texte dans une image 64×64. Imagen utilise ensuite des modèles de diffusion à super-résolution conditionnelle au texte pour upsampler l'image 64×64→256×256 et 256×256→1024×1024.
Poids
Les points de contrôle suivants sont fournis actuellement :
- sd-v1-1.ckpt : 237k pas à la résolution 256x256 sur laion2B-fr. 194k pas à la résolution 512x512 sur laion-high-resolution (170M exemples de LAION-5B avec résolution >= 1024x1024) ;
- sd-v1-2.ckpt : Repris de sd-v1-1.ckpt. 515k étapes à la résolution 512x512 sur laion-aesthetics v2 5+ (un sous-ensemble de laion2B-fr avec un score esthétique estimé > 5.0, et filtré en plus sur les images avec une taille originale >= 512x512, et une probabilité de filigrane estimée < 0.5. L'estimation du filigrane provient des métadonnées de LAION-5B, le score esthétique est estimé à l'aide du LAION-Aesthetics Predictor V2) ;
- sd-v1-3.ckpt : Reprise de sd-v1-2.ckpt. 195k pas à la résolution 512x512 sur « laion-aesthetics v2 5+ » et abandon de 10 % du conditionnement du texte pour améliorer l'échantillonnage de guidage sans classificateur ;
- sd-v1-4.ckpt : Reprise de sd-v1-2.ckpt. 225k pas à la résolution 512x512 sur « laion-aesthetics v2 5+ » et 10% d'abandon du conditionnement du texte pour améliorer l'échantillonnage du guidage sans classificateur.
Les évaluations avec différentes échelles de contrôle sans classificateur (1.5, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0) et 50 étapes d'échantillonnage PLMS montrent les améliorations relatives des points de contrôle :
Contrairement à DALL-E mini et Disco Diffusion, qui sont des logiciels ouverts comparables, Stable Diffusion peut créer d'incroyables uvres d'art photoréalistes et artistiques qui n'ont rien à envier aux modèles d'OpenAI ou de Google. Certains affirment même qu'il s'agit du nouvel état de l'art parmi les « moteurs de recherche génératifs », comme Mostaque aime les appeler.
Bien que l'utilisation commerciale soit autorisée selon les termes de la licence, Stability AI ne recommande pas l'utilisation des poids fournis pour des services ou des produits sans mécanismes et considérations de sécurité supplémentaires, car il existe des limitations et des biais connus des poids, et la recherche sur le déploiement sûr et éthique des modèles généraux de conversion texte-image est un effort continu. « Les poids sont des artefacts de recherche et doivent être traités comme tels », déclare Stability AI.
Le modèle lui-même s'appuie sur le travail de l'équipe de CompVis et de Runway dans leur modèle de diffusion latente largement utilisé, de Robin Rombach du groupe de recherche Machine Vision & Learning de LMU Munich (anciennement CompVis lab à l'Université de Heidelberg), combiné aux idées des modèles de diffusion conditionnelle de de léquipe d'IA générative de Stability AI, Dall-E 2 d'Open AI, Imagen de Google Brain et bien d'autres.
La diffusion stable est un modèle texte-image qui permettra à des milliards de personnes de créer des uvres d'art étonnantes en quelques secondes. Il s'agit d'une percée en termes de vitesse et de qualité, ce qui signifie qu'il peut fonctionner sur des GPU grand public. Un moyen simple de télécharger et d'échantillonner la diffusion stable est d'utiliser la bibliothèque de diffuseurs :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| # make sure you're logged in with `huggingface-cli login`
from torch import autocast
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
use_auth_token=True
).to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
with autocast("cuda"):
image = pipe(prompt)["sample"][0]
image.save("astronaut_rides_horse.png") |
Stable Diffusion plus qu'un DALL-E 2 open-source
Le groupe de recherche en intelligence artificielle OpenAI a créé une nouvelle version de DALL-E, son programme de génération de texte en image. DALL-E 2 est une version à plus haute résolution et à plus faible latence du système original, qui produit des images représentant les descriptions écrites par les utilisateurs. Il comprend également de nouvelles fonctionnalités, comme l'édition d'une image existante. Comme pour les travaux précédents d'OpenAI, l'outil n'est pas directement mis à la disposition du public. Mais les chercheurs peuvent s'inscrire en ligne pour avoir un aperçu du système, et OpenAI espère le rendre disponible ultérieurement pour une utilisation dans des applications tierces.
Nommé d'après l'artiste surréaliste Salvador Dali et le personnage robot de Pixar, Wall-E, le prédécesseur du modèle, DALL-E, a été lancé l'année dernière. Ce logiciel est capable de créer des images dans différents styles artistiques lorsqu'il est guidé par des entrées de texte : il génère des images à partir de ce que vous lui décrivez. Vous demandez un cur anatomiquement réaliste, ou un dessin animé d'un bébé radis chinois en tutu promenant un chien, et il fera de son mieux pour créer une image qui y correspond.
Stability.ai serait né pour créer non pas seulement des modèles de recherche qui n'arrivent jamais dans les mains de la majorité, mais des outils avec des applications du monde réel ouvertes pour les utilisateurs. C'est un changement par rapport à d'autres entreprises technologiques comme OpenAI, qui garde jalousement les secrets de ses meilleurs systèmes (GPT-3 et DALL-E 2), ou Google qui n'a jamais eu l'intention de publier ses propres systèmes (PaLM, LaMDA, Imagen ou Parti) en tant que bêtas privés.
Emad Mostaque a appris des erreurs d'OpenAI. Le succès absolument viral de Craiyon, malgré sa qualité inférieure, a mis en évidence les lacunes de DALL-E en tant que bêta fermée. Les gens ne veulent pas voir comment les autres créent des uvres d'art impressionnantes. Ils veulent le faire eux-mêmes. Stability.ai est allé encore plus loin, car cette version publique n'est pas seulement destinée à partager les poids et le code du modèle - qui, bien qu'ils soient essentiels au progrès de la science et de la technologie, n'intéressent pas la plupart des gens. La société a également facilité la création d'un site Web prêt à l'emploi, sans code, pour ceux d'entre nous qui ne veulent pas ou ne savent pas coder.
Comme DALL-E 2, il utilise un modèle d'abonnement payant qui permettra d'obtenir 1 000 images pour 10 £ (OpenAI recharge 15 crédits chaque mois, mais pour en obtenir davantage, lutilisateur doit acheter des paquets de 115 pour 15 dollars). DALL-E coûte 0,03 dollar/image alors que Stable Diffusion coûte 0,01 livre sterling/image.
En outre, il est également possible dutiliser la diffusion stable à grande échelle par le biais de l'API le coût évolue linéairement, de sorte que lutilisateur obtient 100 000 générations pour 1 000 Livre sterling. De plus, contrairement à DALL-E 2, il est possible de contrôler les paramètres pour influencer les résultats et conserver une plus grande maîtrise de ceux-ci. Stability.ai a tout fait pour faciliter l'accès au modèle.
OpenAI a été le premier et a dû aller plus lentement pour évaluer les risques potentiels et les biais inhérents au modèle, mais ils n'avaient pas besoin de garder le modèle en bêta fermé pendant si longtemps ou d'établir un modèle commercial d'abonnement limitant autant la créativité. Midjourney et Stable Diffusion l'ont tous deux prouvé.
Mais la technologie open source a ses propres limites. Pour certains analystes, l'ouverture doit passer avant la confidentialité et le contrôle strict, mais pas avant la sécurité. Stability.ai a pris ce fait très au sérieux en collaborant avec les équipes éthiques et juridiques de Hugging Face pour publier le modèle sous la licence Creative ML openRAIL-M similaire à la licence du modèle BLOOM de BigScience.
Comme l'explique la société dans l'annonce, il s'agit d'une « licence permissive qui permet une utilisation commerciale et non commerciale » et qui met l'accent sur l'utilisation ouverte et responsable du modèle en aval. Elle prévoit également que les uvres dérivées soient soumises, au minimum, aux mêmes restrictions fondées sur l'utilisateur.
La licence CreativeML OpenRAIL M est une licence Open RAIL M, adaptée du travail que BigScience et l'initiative RAIL mènent conjointement dans le domaine des licences d'IA responsables. Voici, ci-dessous, un script d'échantillonnage de référence, qui comprend :
- un module de contrôle de sécurité, pour réduire la probabilité de sorties explicites ;
- un filigrane invisible des sorties, pour aider les spectateurs à identifier les images comme étant générées par une machine.
Après avoir obtenu les poids stables-diffusion-v1-*-originaux, on les relie
1
2
| mkdir -p models/ldm/stable-diffusion-v1/
ln -s <path/to/model.ckpt> models/ldm/stable-diffusion-v1/model.ckpt |
et échantillonner avec
python scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --plms
Tous les arguments supportés sont accessible via la commande :
python scripts/txt2img.py –help
usage: txt2img.py [-h] [--prompt [PROMPT]] [--outdir [OUTDIR]] [--skip_grid] [--skip_save] [--ddim_steps DDIM_STEPS] [--plms] [--laion400m] [--fixed_code] [--ddim_eta DDIM_ETA]
[--n_iter N_ITER] [--H H] [--W W] [--C C] [--f F] [--n_samples N_SAMPLES] [--n_rows N_ROWS] [--scale SCALE] [--from-file FROM_FILE] [--config CONFIG] [--ckpt CKPT]
[--seed SEED] [--precision {full,autocast}]
optional arguments:
-h, --help show this help message and exit
--prompt [PROMPT] the prompt to render
--outdir [OUTDIR] dir to write results to
--skip_grid do not save a grid, only individual samples. Helpful when evaluating lots of samples
--skip_save do not save individual samples. For speed measurements.
--ddim_steps DDIM_STEPS
number of ddim sampling steps
--plms use plms sampling
--laion400m uses the LAION400M model
--fixed_code if enabled, uses the same starting code across samples
--ddim_eta DDIM_ETA ddim eta (eta=0.0 corresponds to deterministic sampling
--n_iter N_ITER sample this often
--H H image height, in pixel space
--W W image width, in pixel space
--C C latent channels
--f F downsampling factor
--n_samples N_SAMPLES
how many samples to produce for each given prompt. A.k.a. batch size
--n_rows N_ROWS rows in the grid (default: n_samples)
--scale SCALE unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty))
--from-file FROM_FILE
if specified, load prompts from this file
--config CONFIG path to config which constructs model
--ckpt CKPT path to checkpoint of model
--seed SEED the seed (for reproducible sampling)
--precision {full,autocast}
evaluate at this precision
Source : Stability AI
Et vous ?
 Que pensez-vous de Stable Diffusion ?
Que pensez-vous de Stable Diffusion ?
Voyez-vous en ce modèle la capacité de détrôner les modèles d'Open AI GPT-3 et DALL-E 2 ?
Voir aussi :
Le générateur d'images de l'IA DALL-E d'OpenAI peut désormais modifier des photos, les chercheurs peuvent s'inscrire pour le tester
DALL-E Mini serait la machine à mèmes IA préférée d'Internet, l'application de génération d'images permet de comprendre comment l'IA peut déformer la réalité
Dall-E 2 permet de générer des images à partir de quelques mots, mais le produit est-il votre ? Votre illustration numérique générée par l'IA pourrait ne pas être protégée par le droit d'auteur
Google dévoile son IA génératrice d'images par le texte baptisée Imagen et affirme qu'elle est meilleure que DALL-E 2 d'OpenAI















 Répondre avec citation
Répondre avec citation

Partager