













Bonsoir,
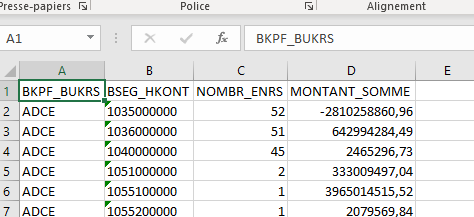
J'essaie d'obtenir cela:
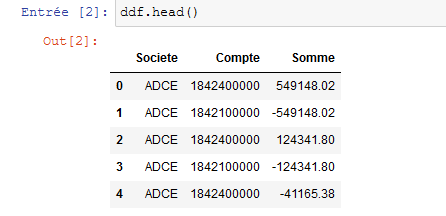
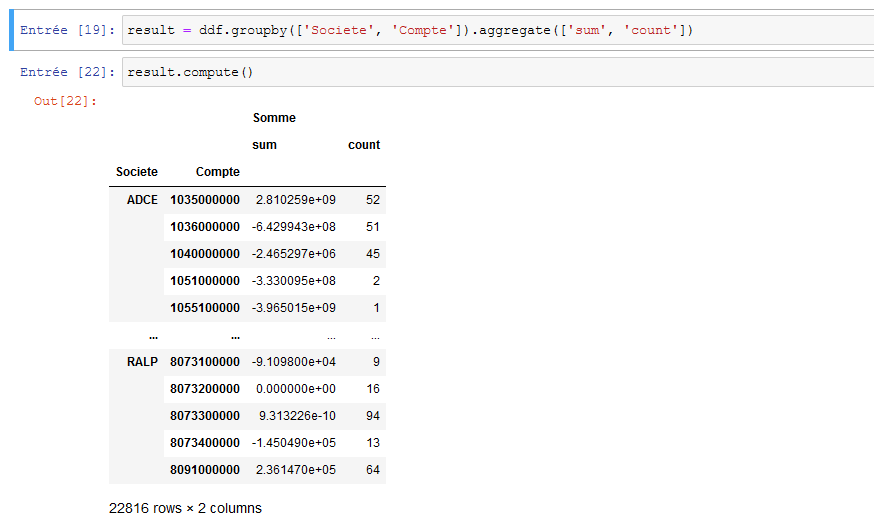
un regroupement par société et numéro de compte à partir de python sans succès
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
J'ai essayé de nombreuses possibilités sans aucune réussite.
Merci pour votre aide
Eric

 Répondre avec citation
Répondre avec citation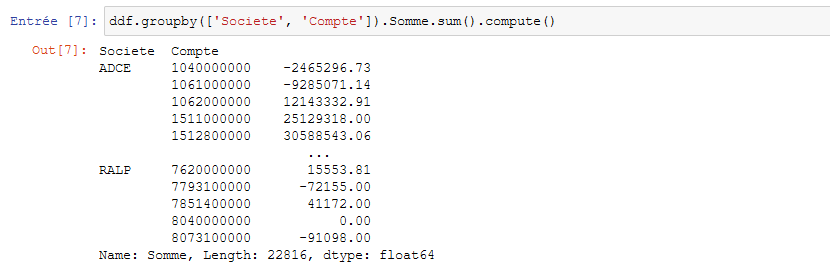

Partager