Au lieu d'utiliser un opérateur OR, tu peux tout simplement rendre le dernier groupe (et son tiret) optionel, en écrivant
(?:-([0-9]+\.[0-9]{1,2}))?.
Maintenant, afin d'obtenir une expression robuste et rapide, il faut être le plus explicite possible en évitant d'utiliser des
.*? ou des
.* qui sont beaucoup trop permissifs
(aucune contrainte de caractères, mise à part une nouvelle ligne, aucune contrainte de taille, ni même d'existence), et qui peuvent demander un travail considérable au moteur de regex si la correspondance n'est pas évidente
(car dans ce cas le moteur de regex va ajouter ou retirer des caractères à ces sous-patterns pour essayer d'autre possibilités d'obtenir une correspondance).
Donc l'idéal est de fournir un véritable couloir au moteur de regex de manière à ce qu'il ait le moins possible de questions à se poser.
Je suppose que chacune des phrases que tu as données en exemple correspond à une ligne complète.
(Si ce n'est pas le cas, n'hésites pas à le dire.)
Pour exploiter le fait qu'une phrase occupe toute une ligne on va utiliser les ancres
^ et
$. Par défaut, ces ancres marquent le début et la fin d'une chaîne, mais si on utilise le modificateur
(?m), alors ces ancres marquent le début et la fin d'une ligne. Ça n'a l'air de rien comme ça, mais ça réduit de beaucoup le travail, notamment en évitant de chercher une correspondance ailleurs qu'au début d'une ligne.
Il faut remplacer maintenant les
.*? par quelque chose de plus explicite.
Pour le deuxième groupe
(E[0-9]+.*?) c'est assez facile car, d'après les exemples, on sait qu'il peut y avoir un espace suivi d'autres chiffres. On peut donc le réécrire comme ça:
(E[0-9]+(?: [0-9]+)?).
On place l'espace et les autres chiffres dans un groupe non-capturant (?:...) que l'on rend optionnel avec le quantificateur ?.
C'est un peu plus difficile de remplacer le 3e groupe
(.*?). Ici, on va exploiter le fait que celui-ci se termine soit avant le tiret et le nombre décimal (quand ils sont présents), soit à la fin de la ligne.
La solution est d'utiliser la classe de caractères
[^-\n] qui autorise tous les caractères sauf les tirets et les nouvelles lignes
(ça évite de déborder sur les lignes suivantes). Ça fonctionne très bien avec les deux premiers exemples, par contre ça ne marche pas avec le troisième qui contient justement un tiret. Ce n'est pas grave, il suffit d'autoriser les tirets pour cette partie en écrivant
([^-\n]+(?:-[^-\n]+)*) (C'est exactement le même principe que pour le groupe 2 avec les chiffres et l'espace, sauf qu'on autorise plusieurs répétitions).
Mais il y a de nouveau un problème car les quantificateurs étant gourmands par défaut, la sous-pattern
(?:-[^-\n]+)* va écrabouiller le dernier groupe optionel
(?:-([0-9]+\.[0-9]{1,2}))?. Il faut donc utiliser un quantificateur non-gourmand:
([^-\n]+(?:-[^-\n]+)*?) ce qui fait qu'à chaque tiret rencontré le dernier groupe est testé en premier avant de répéter
(?:-[^-\n]+).
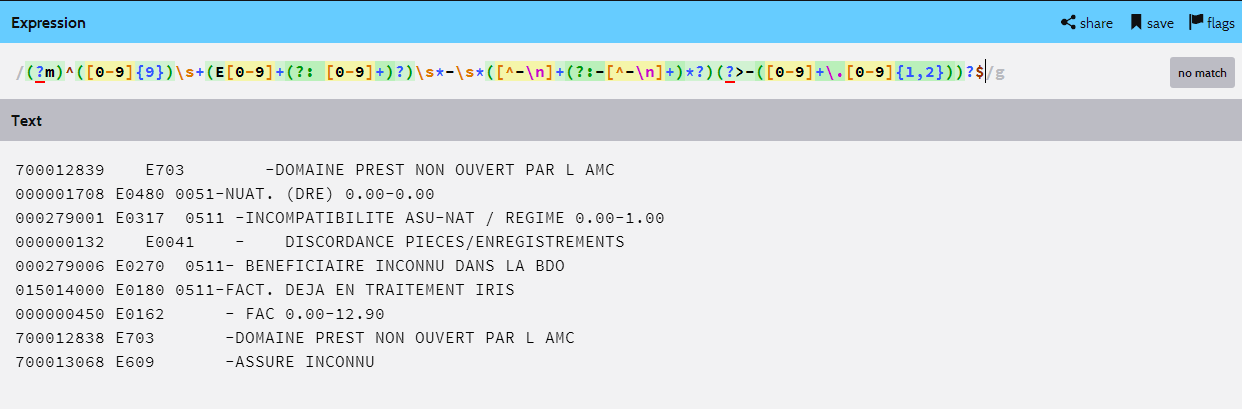
(?m)^([0-9]{9})\s+(E[0-9]+(?: [0-9]+)?)\s*-\s*([^-\n]+(?:-[^-\n]+)*?)(?>-([0-9]+\.[0-9]{1,2}))?$













 Répondre avec citation
Répondre avec citation










Partager