








Bonjour,
Après avoir revus certaines requêtes, je me suis rendu comptes que j'ai besoin de rajouter des index sur certaines tables et j'ai donc décider d'en profiter pour faire un peu de réorganisation.
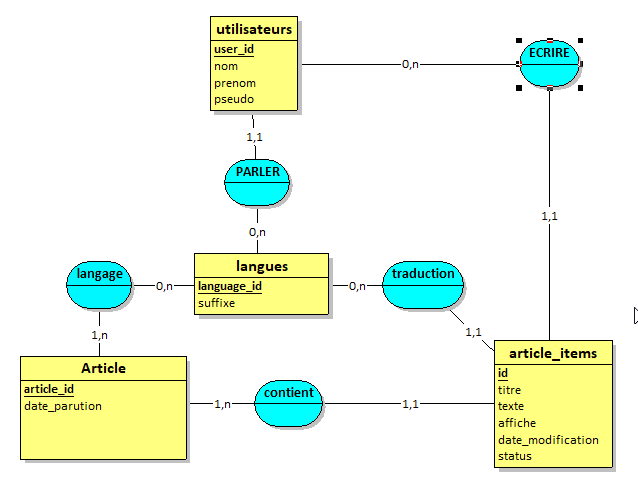
voici 2 tables pour stocker des articles pour un site internet multi langues.
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
la 1ere table permet d'identifier chaque article
la 2eme contient chaque version de l'article
J'ai déjà corrigé la 1ere table et je n'ai pas besoin d'index supplémentaire.
Sur la 2eme c'est un peu plus compliqué.
Je sais déjà que je peux supprimer la colonne 'id' car elle est finalement inutilisé.
j'utilise principalement 'article_id' et 'language_id' pour définir l'article.
En mode affichage (pour le site), seul les versions avec 'status' = 0 sont utilisées
En mode édition (pour l'admin)
des versions supplémentaires sont définis grâce au colonnes suivantes:
'user_id' + 'status' qui marche de paires
Et enfin j'utilise aussi 'modified' qui me permet de trier par date ou de limiter le nombre de mes résultats dans sur le site ou dans l'admin.
Après une première réflexion, je me demande si je ne devrait pas séparer cette table en 3 en séparant les versions selon le status
1 table avec les articles validés et affichables
1 table avec les articles brouillons a valider
1 table pour archiver les anciennes version de chaque articles.
On m'avait dis dans d'autres post que dans une base bien conçu, on ne devait pas avoir plus de 1 ou 2 clés primaires.
Ici j'ai 2 colonnes essentielles qui sont candidates:
'article_id'
'language_id'
mais ensuite j'ai ces autres colonnes qui me sont utiles pour cibler plus précisément et dont je ne sais pas quel traitement leur appliquer:
`user_id`
`status`
`modified`
Est ce qu'il vaudrai mieux définir une ou des tables de liaisons supplémentaires, et si oui lesquels?
Merci de vos conseils
 Répondre avec citation
Répondre avec citation












 Mais bon...
Mais bon...


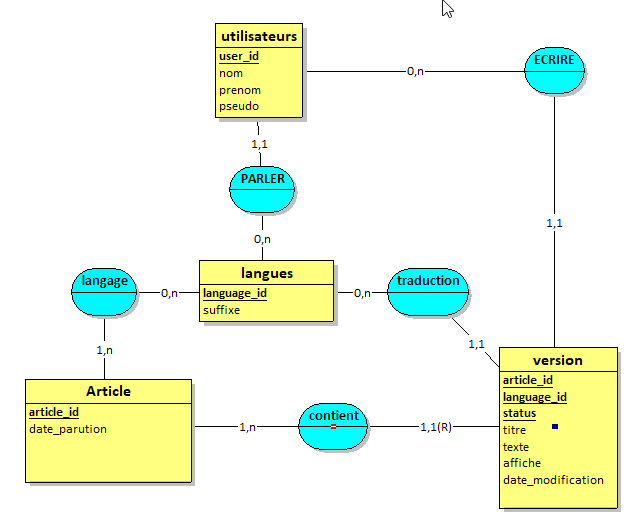
 quels sont ses attributs ? pour l'instant, ça reste une coquille vide. Et rien n'empêche que deux versions attribuées à un même article parlent de choses complètement différentes (une version concerne une recette de cuisine, l'autre une thèse sur la physique quantique par exemple...).
quels sont ses attributs ? pour l'instant, ça reste une coquille vide. Et rien n'empêche que deux versions attribuées à un même article parlent de choses complètement différentes (une version concerne une recette de cuisine, l'autre une thèse sur la physique quantique par exemple...).
Partager