1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
| formatListe = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', 'à', 'â', 'á', 'å', 'ä', 'ã', 'a', 'æ', 'œ', 'ç', 'c', 'c', 'c', 'd', 'ð', 'è', 'é', 'ê', 'ë', 'e', 'e', 'g', 'g', 'h', 'î', 'ì', 'í', 'ï', 'i', 'j', 'l', 'ñ', 'n', 'n', 'ò', 'ö', 'ô', 'ó', 'õ', 'ø', 'r', 's', 's', 's', 'š', 'ß', 't', 'þ', 'ù', 'ú', 'û', 'u', 'ü', 'u', 'ý', 'z', 'z', 'ž']
pourcentagesLettres = {'Anglais': [8.167, 1.492, 2.782, 4.253, 12.702, 2.228, 2.015, 6.094, 6.966, 0.153, 0.772, 4.025, 2.406, 6.749, 7.507, 1.929, 0.095, 5.987, 6.327, 9.056, 2.758, 0.978, 2.360, 0.150, 1.974, 0.074, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'Français': [7.636, 0.901, 3.260, 3.669, 14.715, 1.066, 0.866, 0.737, 7.529, 0.613, 0.074, 5.456, 2.968, 7.095, 5.796, 2.521, 1.362, 6.693, 7.948, 7.244, 6.311, 1.838, 0.049, 0.427, 0.128, 0.326, 0.486, 0.051, 0, 0, 0, 0, 0, 0, 0.018, 0.085, 0, 0, 0, 0, 0, 0.271, 1.504, 0.218, 0.008, 0, 0, 0, 0, 0, 0.045, 0, 0, 0.005, 0, 0, 0, 0, 0, 0, 0, 0, 0.023, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0.058, 0, 0.060, 0, 0, 0, 0, 0, 0, 0],
'Allemand': [6.516, 1.886, 2.732, 5.076, 16.396, 1.656, 3.009, 4.577, 6.550, 0.268, 1.417, 3.437, 2.534, 9.776, 2.594, 0.670, 0.018, 7.003, 7.270, 6.154, 4.166, 0.846, 1.921, 0.034, 0.039, 1.134, 0, 0, 0, 0, 0.578, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0.443, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0.307, 0, 0, 0, 0, 0, 0, 0.995, 0, 0, 0, 0, 0],
'Espagnol': [11.525, 2.215, 4.019, 5.010, 12.181, 0.692, 1.768, 0.703, 6.247, 0.493, 0.011, 4.967, 3.157, 6.712, 8.683, 2.510, 0.877, 6.871, 7.977, 4.632, 2.927, 1.138, 0.017, 0.215, 1.008, 0.467, 0, 0, 0.502, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0.433, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0.725, 0, 0, 0, 0, 0.311, 0, 0, 0, 0, 0, 0.827, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0.168, 0, 0, 0.012, 0, 0, 0, 0, 0],
'Portuguais': [14.634, 1.043, 3.882, 4.992, 12.570, 1.023, 1.303, 0.781, 6.186, 0.397, 0.015, 2.779, 4.738, 4.446, 9.735, 2.523, 1.204, 6.530, 6.805, 4.336, 3.639, 1.575, 0.037, 0.253, 0.006, 0.470, 0.072, 0.562, 0.118, 0, 0, 0.733, 0, 0, 0, 0.530, 0, 0, 0, 0, 0, 0, 0.337, 0.450, 0, 0, 0, 0, 0, 0, 0, 0, 0.132, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0.635, 0.296, 0.040, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0.207, 0, 0, 0.026, 0, 0, 0, 0, 0],
'Espéranto': [12.117, 0.980, 0.776, 3.044, 8.995, 1.037, 1.171, 0.384, 10.012, 3.501, 4.163, 6.104, 2.994, 7.955, 8.779, 2.755, 0, 5.914, 6.092, 5.276, 3.183, 1.904, 0, 0, 0, 0.494, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0.657, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0.691, 0, 0.022, 0, 0, 0, 0, 0, 0.055, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0.385, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0.520, 0, 0, 0, 0, 0, 0],
'Italien': [11.745, 0.927, 4.501, 3.736, 11.792, 1.153, 1.644, 0.636, 10.143, 0.011, 0.009, 6.510, 2.512, 6.883, 9.832, 3.056, 0.505, 6.367, 4.981, 5.623, 3.011, 2.097, 0.033, 0.003, 0.020, 1.181, 0.635, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0.263, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0.030, 0.030, 0, 0, 0, 0, 0, 0, 0, 0.002, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, (0.166), 0.166, 0, 0, 0, 0, 0, 0, 0, 0],
'Turc': [11.920, 2.844, 0.963, 4.706, 8.912, 0.461, 1.253, 1.212, 8.600, 0.034, 4.683, 5.922, 3.752, 7.487, 2.476, 0.886, 0, 6.722, 3.014, 3.314, 3.235, 0.959, 0, 0, 3.336, 1.500, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1.156, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1.125, 0, 0, 0, 0, 0, 5.114, 0, 0, 0, 0, 0, 0, 0.777, 0, 0, 0, 0, 0, 0, 1.780, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1.854, 0, 0, 0, 0, 0],
'Suédois': [9.383, 1.535, 1.486, 4.702, 10.149, 2.027, 2.862, 2.090, 5.817, 0.614, 3.140, 5.275, 3.471, 8.542, 4.482, 1.839, 0.020, 8.431, 6.590, 7.691, 1.919, 2.415, 0.142, 0.159, 0.708, 0.070, 0, 0, 0, 1.338, 1.797, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1.305, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'Polonais': [8.910, 1.470, 3.960, 3.250, 7.660, 0.300, 1.420, 1.080, 8.210, 2.280, 3.510, 2.100, 2.800, 5.520, 7.750, 3.130, 0.140, 4.690, 4.320, 3.980, 2.500, 0.040, 4.650, 0.020, 3.760, 5.640, 0, 0, 0, 0, 0, 0, 0.990, 0, 0, 0, 0, 0.400, 0, 0, 0, 0, 0, 0, 0, 1.110, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1.820, 0, 0.200, 0, 0, 0, 0, 0.850, 0, 0, 0, 0, 0, 0.660, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0.060, 0.830, 0],
'Néerlandais': [7.486, 1.584, 1.242, 5.933, 18.91, 0.805, 3.403, 2.380, 6.499, 1.46, 2.248, 3.568, 2.213, 10.032, 6.063, 1.57, 0.009, 6.411, 3.73, 6.79, 1.99, 2.85, 1.52, 0.036, 0.035, 1.39, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'Danois': [6.025, 2.000, 0.565, 5.858, 15.453, 2.406, 4.077, 1.621, 6.000, 0.730, 3.395, 5.229, 3.237, 7.240, 4.636, 1.756, 0.007, 8.956, 5.805, 6.862, 1.979, 2.332, 0.069, 0.028, 0.698, 0.034, 0, 0, 0, 1.190, 0, 0, 0, 0.872, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0.939, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'Islandais': [10.110, 1.043, 0, 1.575, 6.418, 3.013, 4.241, 1.871, 7.578, 1.144, 3.314, 4.532, 4.041, 7.711, 2.166, 0.789, 0, 8.581, 5.630, 4.953, 4.562, 2.437, 0, 0.046, 0.900, 0, 0, 0, 1.799, 0, 0, 0, 0, 0.867, 0, 0, 0, 0, 0, 0, 4.393, 0, 0.647, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1.570, 0, 0, 0, 0, 0, 0, 0, 0, 0.777, 0, 0.994, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1.455, 0, 0.613, 0, 0, 0, 0, 0.228, 0, 0, 0],
'Finlandais': [12.217, 0.281, 0.281, 1.043, 7.968, 0.194, 0.392, 1.851, 10.817, 2.042, 4.973, 5.761, 3.202, 8.826, 5.614, 1.842, 0.013, 2.872, 7.862, 8.750, 5.008, 2.250, 0.094, 0.031, 1.745, 0.051, 0, 0, 0, 0.003, 3.577, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0.444, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'Tchèque': [8.421, 0.822, 0.740, 3.475, 7.562, 0.084, 0.092, 1.356, 6.073, 1.433, 2.894, 3.802, 2.446, 6.468, 6.695, 1.906, 0.001, 4.799, 5.212, 5.727, 2.160, 5.344, 0.016, 0.027, 1.043, 1.599, 0, 0, 0.867, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0.462, 0.015, 0, 0, 0.633, 0, 0, 0, 1.222, 0, 0, 0, 0, 0, 1.643, 0, 0, 0, 0, 0, 0, 0.007, 0, 0, 0, 0.024, 0, 0, 0.380, 0, 0, 0, 0.688, 0, 0.006, 0, 0, 0.045, 0, 0, 0, 0.204, 0.995, 0, 0, 0.721]}
def lettre_dans_mot(mot): # Trouve les lettres dans un mot
global dictlettre
dictlettre = {}
for lettre in mot: # Pour chaque lettres dans le mot
if lettre in dictlettre: # Si la lettre est déjà dans le dictio
dictlettre[lettre] += 1 # Indenter 1 le nombre de lettre trouver
else: # Sinon
dictlettre[lettre] = 1 # Ajouter la lettre au dictio et mettre à 1 la valeur trouver
return(dictlettre) # retourne le dictionnaire de lettre
def mot_dans_txt(txt): # Trouve les mots dans un texte
global dictmot
dictmot = {}
ponctu = ["-", ",", ":", "'", "’", ".", "!", "?", "(", ")", "/", "\n", "\\"] # Liste des ponctuations a supprimer lors de la séparation des mots
for i in ponctu: # Pour tout les éléments de la ponctuation
txt = txt.replace(i, " ") # Supprimer cet élément
txt = txt.lower() # Convertit les majuscules en minuscules
txt = txt.split() # sépare les mots entre les espaces
for mot in txt: # pour chaque mot dans le texte
if mot in dictmot: # Si le mot est déjà dans le dictio
dictmot[mot] +=1 # indenter 1 le nombre de mot trouver
else: # sinon
dictmot[mot] = 1 # ajouter le mot au dictio et mettre à 1 la valeur trouver
return(dictmot) # retourne le dictionnaire de mots
def lettre_dans_txt(txt): # repertorie l'ensemble des lettres d'un texte
global dictlettres
dictlettres = {}
for mot in mot_dans_txt(txt): # pour chaque mot trouvé dans le dictionnaire
for lettre in lettre_dans_mot(mot): # pour chaque lettre trouvé dans le dictionnaire
if lettre in dictlettres: # Si la lettre est déjà dans le dictio
dictlettres[lettre] += 1 # Indenter 1 le nombre de lettre trouver
else: # Sinon
dictlettres[lettre] = 1 # Ajouter la lettre au dictio et mettre à 1 la valeur trouver
return(dictlettres)
"""THE PROBLEM IS HERE ============================================================"""
def trouveLangue(txt): # Essaye de déterminer la langue par le nombre de lettres et en fonction des accents
resultatsPourcentage = {'Anglais': 0, 'Français': 0, 'Allemand': 0, 'Espagnol': 0, 'Portuguais': 0, 'Espéranto': 0, 'Italien': 0, 'Turc': 0, 'Suédois': 0, 'Polonais': 0, 'Néerlandais': 0, 'Danois': 0, 'Islandais': 0, 'Finlandais': 0, 'Tchèque': 0}
"""============================================================"""
print(resultatsPourcentage)
def startIt():
global texte
choice = str(input("""* Bienvenue dans le script trouveLangue, un programme qui vous permet de déterminer la langue de votre texte parmis celles ci :
- Anglais
- Français
- Allemand
- Espagnol
- Portuguais
- Espéranto
- Italien
- Turc
- Suédois
- Polonais
- Néerlandais
- Danois
- Islandais
- Finlandais
- Tchèque
Voulez entrer votre texte via Python où l'importer via un fichier texte ?
[1] Entrée manuelle
[2] Importer un fichier\n"""))
if choice == '1': # Choix 1 écrire le texte dans python
texte = str(input("Entrez votre texte :\n====================\n"))
print(texte)
elif choice == '2': # Choix 2 importer un fichier possédant un texte
file = str(input("Entrez le nom du fichier texte contenant votre texte (avec l'extension) :\n=========================================================================\n"))
with open(file, "r", encoding='utf-8') as file:
texte = file.read()
print(texte)
trouveLangue(texte) # Début de la fonction trouveLangue
startIt() |












 Répondre avec citation
Répondre avec citation















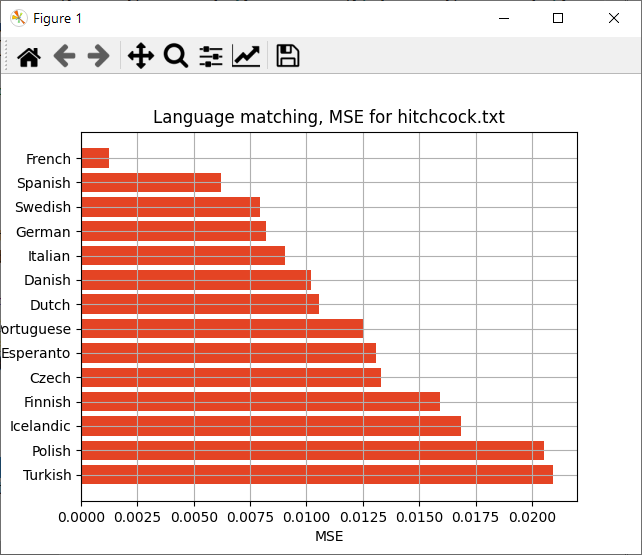
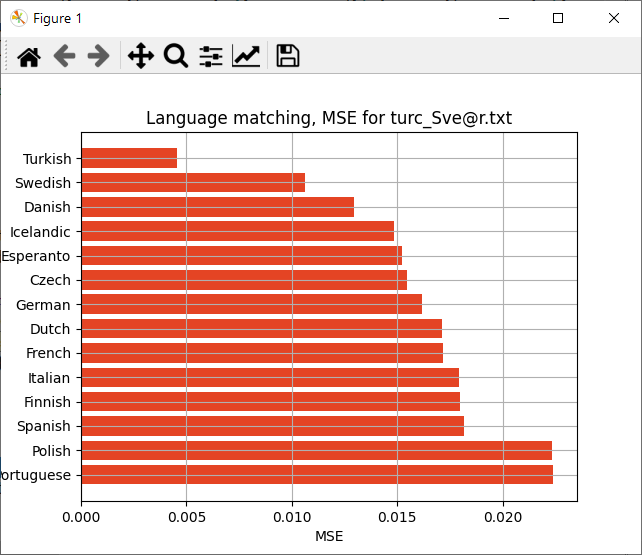
 Faudrait maintenant tester d'autres langues pour voir si ça matche
Faudrait maintenant tester d'autres langues pour voir si ça matche 



Partager