Calcul de poules pour un championnat
Bonjour,
Je voudrais trouver un algorithme qui me permette de générer en automatique un championnat à plusieurs poules en optimisant les kilomètres parcourus par chaque équipe.
j'ai 30 équipes et je connais toutes les distances entre chaque équipes. Cela se passe sous forme de matchs A/R sur 18 dates : tout le monde se déplace chez tout le monde.
L'objectif est de faire 3 poules de 10 équipes en optimisant les kilomètres pour tout le monde.
Merci de me donner quelques pistes ...
Calcul de poules pour un championnat
Bonjour, :D
Citation:
Envoyé par
tbc92

... Ca ressemble un peu au problème du voyageur de commerce, très classique, mais je ne pense pas que tu puisses utiliser cet algorithme tel quel.
La force brute, recenser toutes les combinaisons possibles... bof, trop de combinaisons ...
À partir d'un nombre pair (N) d'équipes en compétition, on peut envisager plusieurs séries de rencontres éliminatoires opposant deux à deux les équipes rivales, dans le but d'en sélectionner la moitié (N/2) à l'issue de deux matchs aller-retour.
Une poule est définie par l'ensemble des (N/2) paires d'équipes qui vont devoir s'affronter, soit par exemple pour N = 8:
P = { (A, B), (C, D), (E, F), (G, H) } ;
elle est représentée par la liste arbitrairement ordonnée des couples:
L1 = ( (A, B), (C, D), (E, F), (G, H) ) , mais tout aussi bien par:
L2 = ( (A, B), (C, D), (G, H), (E, F) ) ... etc , soit au total: 6 = 3! = (N/2 - 1)! listes commençant par le premier couple (A, B).
De plus à chacune de ces listes correspondent plusieurs itinéraires, par retournement de l'un des couples: en partant ainsi de la première liste (L1), on peut envisager les parcours:
I1 = (AB_CD_EF_GH) ,
I2 = (AB_DC_EF_GH) ,
I1 = (AB_CD_FE_GH) ... etc, soit en tout: 8 = 23 = 2(N/2-1) itinéraires orientés commençant par (A) puis (B).
Le nombre (Ni) de tels itinéraires étant égal à (N - 2)! , celui des poules envisageables vaut: Np = (N - 2)! / (2(N/2-1) * (N/2 - 1)!) ;
on obtient dans le cas où N = 32 : Np = 30! / (215 * 15!) ~ 6.19.1015 , ce qui fait effectivement beaucoup - bien que le résultat soit très inférieur au précédent (Ni = 30! ~ 2.65.1032).
La différence essentielle avec le problème du voyageur de commerce, c'est que seule compte la moitié des distances de la boucle (ABCD ...), ce qui constitue un atout pour la méthode aléatoire: une recherche pourra donner de "bons" résultats, pour peu qu'elle soit bien conduite.
Le procédé suivant part de la liste des (N) équipes en compétition, arbitrairement ordonnée (par exemple selon l'ordre alphabétique):
1°) Tirage aléatoire de (A); détermination de l'équipe la plus proche (B);
2°) Tirage aléatoire de (C) sur les (N - 2) équipes restantes; détermination de l'équipe la plus proche (D) parmi les (N - 3) disponibles;
3°) Tirage aléatoire de (E) sur les (N - 4) équipes restantes; détermination de l'équipe la plus proche (F) parmi les (N - 5) disponibles;
... et ainsi de suite, la poule apparaissant au bout de (N/2 - 1) tirages, puisque le dernier couple est d'emblée formé des deux dernières équipes restantes.
L'itération de ce procédé doit conduire doit conduire rapidement à des sommes de distances de plus en plus basses.
Je comprend mal les données proposées par skywalker70 ...
Citation:
Envoyé par
skywalker70
... J'ai 30 équipes et je connais toutes les distances entre chaque équipes. Cela se passe sous forme de matchs A/R sur 18 dates : tout le monde se déplace chez tout le monde.
L'objectif est de faire 3 poules de 10 équipes en optimisant les kilomètres pour tout le monde ...
Je pensais qu'on mettait 32 équipes en compétition ... Un détail m'échappe sans doute. Je n'ai pas d'avis sur ce point, ne connaissant que très peu de choses sur le sujet.
J'espère seulement ne pas avoir sorti trop d'énormités :pastaper: dans tout ce qui précède !
Calcul de poules pour un championnat
Je n'avais rien trouvé sur la Toile concernant l'organisation des rencontres de championnat, en m'en étais tenu au schéma binaire (ou ce que j'en avais retenu) que l'on commente dans la presse sportive. Les possibilités sont de fait beaucoup plus souples et variées, et j'étais à côté de la plaque :D.
Il faut réaliser une partition de l'ensemble (E) des 30 villes en 3 sous-ensembles de points (E1, E2, E3) de proximité maximale, ce qui n'est pas facile si l'on ne dispose seulement que de la matrice des distances, et non des coordonnées cartésiennes.
On peut tenter de repérer "à l'aveugle":
a) la ville (M0) la plus proche de l'isobarycentre de l'ensemble, caractérisée par la valeur minimale de la somme des carrés des distances:
S(M0) = Smin = Min(Si=030(M0Mi)2) ;
b) la quinzaine de villes excentrées (12 à 18 environ) situées à la limite du nuage, donc les plus éloignées de (M0), et qui forment un sous-ensemble (F);(1)
c) les triangles (Fk, F'k, F"k) à peu près équilatéraux formés à partir des sommets successifs de (F), et de deux autres.
La partition de (E) en (E1, E2, E3) apparaîtra spontanément par la recherches des 9 points les plus proches des sommets précédents (Fk, F'k, F"k).
Vous ne manquerez pas d'être comme moi déconcertés par le flou des instructions décrites en (b) et (c), qui font de chaque nuage un cas d'espèce.
(1) Elles sont également repérables par une valeur élevée - sinon maximale - de la somme des carrés des distances:
SFk = Si=030(FkMi)2 .
8 pièce(s) jointe(s)
Calcul de poules pour un championnat
L'intérêt du sujet est de conduire à la partition d'un nuage de points en trois sous-ensembles équipotents.
J'ai donc repris le problème à partir de l'ensemencement aléatoire d'un carré de côté 1000 par 30 points, à partir duquel il devient possible de calculer la matrice des distances - matrice symétrique (dij = dji) à éléments entiers, correspondant aux valeurs exprimées en kilomètres.
On envisage pour chacun des(N) points la somme des carrés des distances qui le séparent de ses 29 voisins:
Sj = Si=1i=N(dij2) .
Leur distribution spatiale se caractérise par trois données:
# la valeur minimale (Sd2min), qui caractérise le point (M0) le plus proche de (G);
# les valeurs moyenne et maximale (Sd2moy , Sd2max), qui seront par la suite utilisées.
1°) Un processus en deux étapes permet la recherche des éventuels triangles quasi-équilatéraux (QEL):
a) la présélection des points les plus éloignés de la région centrale du nuage, et vérifiant la condition: (Sk > Sd2moy) ;
on en trouve généralement 10 à 15;
b) le repérage des éventuels triangles QEL, que l'on caractérise très simplement par le facteur de forme (r = dmax / dmin) ,
égal à l'unité dans le cas d'un triangle équilatéral;
la condition de sélection ici utilisée (r < 1.200 = rmax) conduit à un angle maximal compris entre 65.38° et 73.74° , bornes correspondant aux deux cas limites:
# pour le triangle (1, 1, rmax): amax = 2*Arcsin(rmax / 2) = 73.7398°
(l'angle minimal vaut alors b = 53.1301°) ;
# pour le triangle (1, rmax, rmax):amin = 90° - Arcsin(1 / (2*rmax)) = 65.3757°
(l'angle minimal vaut alors b = 49.2486°) .
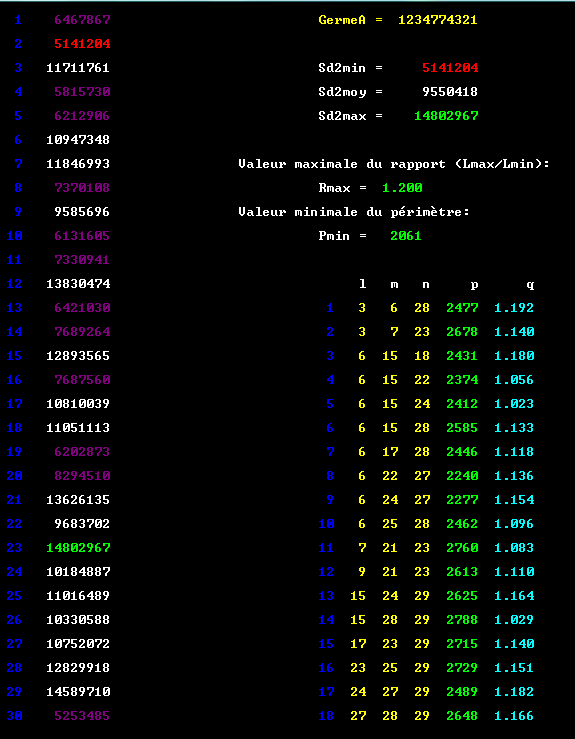
2°) On trouve ainsi pour un nuage donné un nombre variable de triangles QEL, allant communément de 5 à 25 - par exemple 18 dans le cas du tirage suivant:
Pièce jointe 328386
Remarquer la possibilité de construire (selon l'étroitesse du critère de sélection) plusieurs triangles à partir d'un (ou de deux) sommets donnés: voir la fréquence anormalement élevée des sommets 6, 15 et 29).
3°) Il apparaît de temps à autre des réponses inutilisables, en raison des faibles dimensions de la figure: le périmètre correspondant (p) est alors très nettement inférieur aux autres valeurs affichées:
Pièce jointe 328331__Pièce jointe 328335
Cela vient de ce que l'on trouve parfois en bordure du nuage, avec une probabilité faible mais non négligeable, des points relativement proches constituant un triangle conforme au critère de sélection.
4°) Le procédé décrit fournit des triangles en nombre très variable; il arrive même qu'il n'y en ait aucun:
Pièce jointe 328336
Le nuage de points est alors trop allongé pour que l'on puisse y construire un triangle QEL.
Cela se vérifie, pour un tirage donné,
Code:
1
2
3
4
5
6
| RandSeed:= 1116666999;
FOR i:= 1 TO Nmax DO
WITH LstP[i] DO BEGIN
r:= Random; x:= Round(DmX * r);
r:= Random; y:= Round(DmY* r)
END; |
lorsque l'on fait varier les dimensions du domaine, à aire constante:
(DmX, DmY) = (1000, 1000) ; (1100, 909) ; (1150, 870) ; (1200, 833)
Pièce jointe 328357__Pièce jointe 328360__Pièce jointe 328361__Pièce jointe 328366
5°) En l'absence de triangles QEL, la partition du nuage n'est pas pour autant compromise: on choisira le point (M0) déjà mentionné, ainsi que le couple des points les plus éloignés (ou quelques couples correspondant aux plus grandes distances): il suffira ensuite de lister les 27 points restants les plus proches des 3 précédents.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}