






Bonjour !
Je suis actuellement en stage et je dois mettre en place une solution décisionnelle... Je connais les grands concepts de la chaine décisionnelle, mais seulement dans la théorie... Pourriez-vous m'éclairer un peu plus au niveau pratique ? (Désolée, je sais que mes questions sont bêtes et vraiment dignes d'une débutante...)
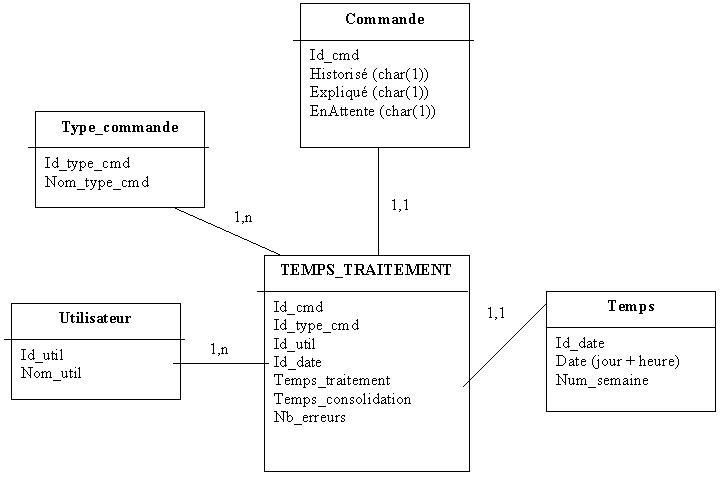
1) J'ai modélisé mon datawarehouse avec un schéma en étoile, et maintenant je souhaite le mettre en place sous Oracle. Comment faut-il que je m'y prenne concrètement ? Quand on dit construire un datawarehouse, est-ce que cela signifie créer les tables du modèle en étoile que j'ai fait, et ce exactement comme si je créais les tables d'une BD relationnelle sous Oracle (avec des CREATE TABLE) ?
2) Je compte utiliser KETTLE comme ETL pour alimenter mon DW. Concrètement, est-ce que si j'envoie directement les données à partir des différentes sources vers mon DW que j'aurai construit sous Oracle (cf. question 1) grâce à Kettle (avec éventuellement des transformations), c'est ce qu'il faut faire ?
3) Je voulais utiliser Mondrian pour créer mes cubes, et pour le reporting : Jfreereport, Birt ou encore IReport de Jasper (des outils open sources en gros). Est-ce que ces outils peuvent se connecter directement aux cubes créés sous Mondrian ?
Merci d'avance pour vos réponses...
@++")
 Répondre avec citation
Répondre avec citation







 N'oubliez pas le bouton
N'oubliez pas le bouton  et pensez aux balises [code]
et pensez aux balises [code]

 et pour ta réactivité !!!
et pour ta réactivité !!! 



Partager