











Les modèles de langages coûtent 10 fois plus cher à développer dans certaines langues que dans d'autres,
d'après l'analyse d'une chercheuse en IA
Les modèles de langage sont des systèmes informatiques capables de générer ou de comprendre du texte naturel. Ils sont utilisés pour de nombreuses applications, comme la recherche, la traduction, la rédaction ou le dialogue. Mais Yennie Jun, ingénieure en machine learning et chercheuse en AI, a démontré que tous les modèles de langage ne se valent pas : selon la langue quils traitent, ils peuvent avoir des performances et des coûts très différents.
Les modèles de langage sont des outils puissants et prometteurs pour traiter le texte naturel, mais ils ont aussi un coût qui varie selon la langue quils manipulent. Ce coût dépend de plusieurs facteurs, comme la taille du modèle, la qualité des données ou le niveau de spécialisation. Il a des conséquences importantes pour les développeurs, les utilisateurs et lenvironnement.
Le concept de tokenisation
La tokenisation est une étape essentielle dans la plupart des modèles dIA actuels. La tokenisation consiste à découper un texte ou une autre modalité en unités plus petites et plus gérables, appelées tokens. Par exemple, un texte peut être découpé en mots, en syllabes ou en caractères. Une image peut être découpée en pixels ou en régions. Un son peut être découpé en fréquences ou en phonèmes.
La tokenisation permet de réduire la complexité et la taille des données à traiter par les modèles dIA, mais elle présente aussi des inconvénients. Tout dabord, elle nécessite de choisir un vocabulaire de tokens adapté au domaine et à la langue des données, ce qui peut être coûteux et fastidieux. Ensuite, elle introduit une perte dinformation et une ambiguïté dans la représentation des données, car certains tokens peuvent avoir plusieurs sens ou ne pas correspondre exactement aux unités sémantiques des données. Enfin, elle limite la capacité des modèles à traiter des séquences longues et variées, car le nombre de tokens augmente avec la longueur et la diversité des données.
Pour être plus clair, les grands modèles de langage tels que ChatGPT traitent et génèrent des séquences de texte en divisant d'abord le texte en unités plus petites appelées tokens (ou jetons). Dans l'image ci-dessous, chaque bloc coloré représente un token unique. Des mots courts ou courants tels que you, say, loud et always sont leurs propres token, tandis que des mots plus longs ou moins courants tels que atrocious, precocious, and supercalifragilisticexpialidocious sont divisés en sous-mots plus petits.
Ce processus de tokenisation n'est pas uniforme d'une langue à l'autre, ce qui entraîne des disparités dans le nombre de jetons produits pour des expressions équivalentes dans différentes langues. Par exemple, une phrase en birman ou en amharique peut nécessiter 10 fois plus de jetons qu'un message similaire en anglais.
Dans son billet, Yennie Jun a exploré le processus de tokenisation et s'est intéressé à sa variation d'une langue à l'autre. Elle a notamment :
- analysé des distributions de tokens dans un ensemble de données parallèles de messages courts qui ont été traduits dans 52 langues différentes ;
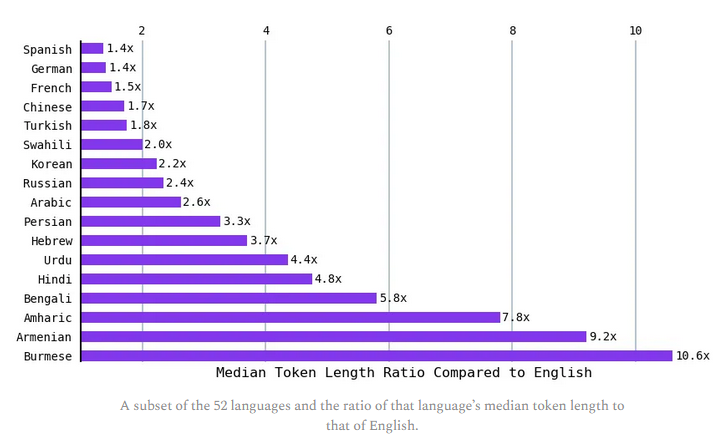
- noté que certaines langues, comme l'arménien ou le birman, nécessitent 9 à 10 fois plus de tokens que l'anglais pour tokeniser des messages comparables ;
- noté l'impact de cette disparité linguistique, rappelant au passage que ce phénomène n'est pas nouveau pour l'IA et précisant que cela correspond à ce que nous observons dans le code Morse et les polices informatiques.
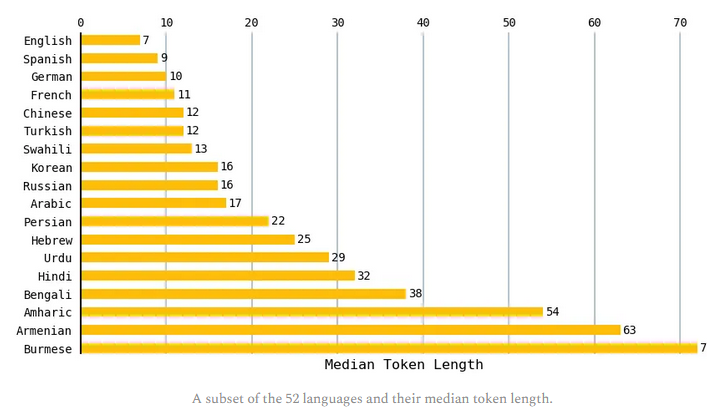
Certaines langues se segmentent systématiquement en longueurs plus longues
Pour chaque langue, Yennie a calculé la longueur médiane du token pour tous les textes de l'ensemble de données. Le tableau suivant compare un sous-ensemble de langues. Les textes anglais avaient la plus petite longueur médiane de 7 tokens et les textes birmans avaient la plus grande longueur médiane de 72 jetons. Les langues romanes telles que l'espagnol, le français et le portugais avaient tendance à donner un nombre similaire de token à l'anglais.
Comme l'anglais avait la longueur de jeton médiane la plus courte, Yennie a calculé le rapport entre la longueur médiane du token des autres langues et celle de l'anglais. Des langues telles que l'hindi et le bengali (plus de 800 millions de personnes parlent l'une ou l'autre de ces langues) ont donné une longueur symbolique médiane d'environ 5 fois celle de l'anglais. Le ratio est 9 fois celui de l'anglais pour l'arménien et plus de 10 fois celui de l'anglais pour le birman. En d'autres termes, pour exprimer le même sentiment, certaines langues nécessitent jusqu'à 10 fois plus de token. Le français quant à lui nécessitait 1,5 fois le nombre de token en anglais pour exprimer le même sentiment.
Quels sont les facteurs qui influencent le coût des modèles de langage ?
Le coût dun modèle de langage dépend de plusieurs facteurs, dont les principaux sont :
- La taille du modèle : plus un modèle a de paramètres, cest-à-dire de variables internes qui déterminent son comportement, plus il est complexe et puissant, mais aussi plus il consomme de ressources informatiques pour être entraîné et déployé.
- La qualité des données : pour apprendre à produire ou à analyser du texte, un modèle de langage a besoin de données dentraînement, cest-à-dire de textes étiquetés ou non qui lui servent dexemples. La qualité de ces données influe sur la qualité du modèle : plus les données sont diverses, représentatives et sans erreur, plus le modèle sera performant et robuste. Or, certaines langues disposent de plus de données que dautres, notamment celles qui sont parlées par un grand nombre de personnes ou qui sont présentes sur le web. Par exemple, langlais bénéficie dun corpus de données très riche et varié, tandis que des langues moins répandues ou moins numérisées comme le basque ou le tibétain ont moins de données disponibles.
- Le niveau de spécialisation : un modèle de langage peut être généraliste ou spécialisé dans un domaine particulier, comme la médecine, le droit ou la finance. Un modèle spécialisé a lavantage dêtre plus précis et pertinent dans son domaine, mais il nécessite aussi des données plus spécifiques et plus rares, ce qui augmente son coût. Par exemple, un modèle de langage médical en français aura besoin de données issues de publications scientifiques, de rapports médicaux ou de dialogues entre médecins et patients en français, ce qui est moins facile à trouver quun corpus généraliste en français.
Il nexiste pas de mesure unique et universelle du coût des modèles de langage, car il dépend du contexte et du but recherché. Néanmoins, on peut distinguer deux types principaux de coût :
- Le coût dentraînement : il correspond au coût nécessaire pour créer un modèle à partir de données. Il inclut le coût du matériel informatique (processeurs, mémoire, stockage), du logiciel (frameworks, bibliothèques), de lélectricité et du temps humain (ingénieurs, chercheurs, annotateurs). Le coût dentraînement peut être très élevé pour les modèles les plus grands et les plus sophistiqués
- Le coût dinférence : il correspond au coût nécessaire pour utiliser un modèle existant pour générer ou comprendre du texte. Il inclut le coût du matériel informatique (serveurs, cloud), du logiciel (APIs, services), de lélectricité et du temps humain (utilisateurs, clients). Le coût dinférence peut varier selon la fréquence et la complexité des requêtes.
Le coût des modèles de langage a des implications importantes pour les acteurs qui les développent ou les utilisent, ainsi que pour les utilisateurs finaux qui en bénéficient. On peut citer quelques exemples :
- Le coût dentraînement peut être un frein à linnovation et à la diversité linguistique : seuls les acteurs disposant de moyens financiers importants peuvent se permettre dentraîner des modèles de pointe sur des langues peu dotées en données. Cela peut créer un déséquilibre entre les langues dominantes et les langues minoritaires, et renforcer les biais culturels ou idéologiques des modèles.
- Le coût dinférence peut être un facteur de compétitivité et de rentabilité : les acteurs qui proposent des services basés sur des modèles de langage doivent trouver le bon équilibre entre la qualité et le coût de leurs offres. Cela peut les inciter à optimiser leurs modèles, à choisir des langues plus rentables ou à répercuter le coût sur les utilisateurs.
- Le coût des modèles de langage peut avoir un impact environnemental : les modèles de langage consomment beaucoup dénergie, ce qui contribue au réchauffement climatique. Selon une étude menée par lUniversité du Massachusetts en 2019 , entraîner un modèle de langage comme BERT équivaut à émettre environ 284 tonnes de CO2, soit léquivalent de la consommation annuelle de 5 voitures américaines. Cela pose la question de la responsabilité écologique des acteurs du domaine.
Conclusion
Les disparités linguistiques dans la tokenisation révèlent un problème urgent en IA*: l'équité et l'inclusivité. Comme des modèles comme ChatGPT sont principalement formés à l'anglais, les langues de script non indo-européennes et non latines sont confrontées à des obstacles en raison des coûts de tokenisation prohibitifs.
Aussi, tous les modèles de langage ne se valent pas : selon la langue ciblée, le coût peut varier considérablement. Par exemple, le français est une langue moins représentée que langlais sur le web et dans les bases de données. Il existe donc moins de données disponibles pour entraîner des modèles de langage en français. De plus, le français est une langue plus riche et plus variée que langlais sur le plan morphologique et syntaxique. Il faut donc des modèles plus grands et plus complexes pour couvrir toutes les nuances du français.
Yennie Jun estime qu'il est « essentiel de s'attaquer à ces disparités pour assurer un avenir plus inclusif et accessible à l'intelligence artificielle, qui profitera en fin de compte aux diverses communautés linguistiques du monde entier ». Elle propose un tableau de bord exploratoire qu'elle a réalisé, disponible sur les espaces HuggingFace. Une fois dessus, vous pouvez comparer les longueurs de jeton pour différentes langues et pour différents tokenizers (ce qui n'a pas été exploré dans son article, mais qu'elle recommande aux curieux).
Essayez vous-même
Source : Yennie Jun
Et vous ?

 Répondre avec citation
Répondre avec citation
Partager