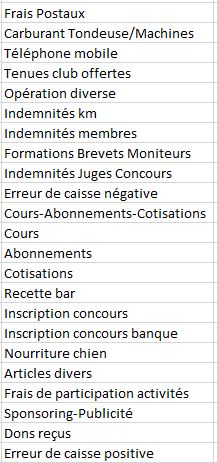
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| // A amélioré encore sûrement
function checkChar($str){
// Si la chaîne est détectée en UTF-8
if(mb_detect_encoding($str) == 'UTF-8'){
// On s'occupe d'abord du cas ou des accents sont présent mais bien encodé
// Cela pour éviter le double encodage, alors qu'il est déjà bon, ce qui génrerai des ? dans un losange
$search_ex = array('/é/','/ë/','/è/','/ç/','/oe/','/â/','/î/','/à/');
$search = array('é','ë','è','ç','oe','â','î','à');
$replace_ex = array('/\[ET\]/','/\[EY\]/','/\[ES\]/','/\[CS\]/','/\[OE\]/','/\[AC\]/','/\[IC\]/','/\[AA\]/');
$replace = array('[ET]','[EY]','[ES]','[CS]','[OE]','[AC]','[IC]','[AA]');
$str = preg_replace($search_ex, $replace, $str);
// Maintenant on converti la chaîne, pour la rendre compatible avec toutes les données
$str = mb_convert_encoding($str, 'iso-8859-1');
// Mes é sont devenu des é, etc...
// on peux donc replacé les caractères qui étaient bon
$str = preg_replace($replace_ex, $search, $str);
}
return $str;
// Je peux faire le ré-encodage en UTF8 à la sortie si besoin
// return utf8_encode($str);
} |











 Répondre avec citation
Répondre avec citation










Partager