












Bonjour,
Je teste comme à l'habitude le KeyPress lors de saisie, mais là, je ne sais pas pourquoi, le compilateur me fait une erreur:
je vous mets l'image car l'éditeur souligne l'endroit où il coince, juste avant la première lettre accentuée! Est-ce le codage en unicode qui complique les choses?
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
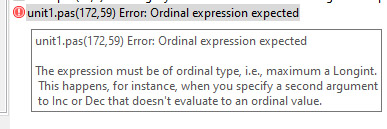
Et le message du compilateur:
Est-ce que ça signifie que j'ai dépassé les capacités d'énumération de l'ensemble: on parle de LongInt, ce qui me parait peu probable!
Si vous avez une idée? Je vais essayer de décomposer en deux ensembles distincts...
Bon, le Type SET n'est valable que pour les types de base en Lazarus, il faut donc procéder autrement...
Merci

 Répondre avec citation
Répondre avec citation









Partager