
Envoyé par
New York Times
4. UTILISATION INTERDITE DES SERVICES
4.1 Vous ne pouvez pas accéder ou utiliser, ou tenter d'accéder ou d'utiliser, les Services pour prendre des mesures qui pourraient nous nuire ou nuire à un tiers. Vous ne pouvez pas utiliser les Services en violation des lois applicables, y compris les contrôles et les sanctions à l'exportation, ou en violation de notre propriété intellectuelle ou de celle d'un tiers ou d'autres droits de propriété ou légaux. Vous acceptez en outre de ne pas tenter (ni d'encourager ou de soutenir la tentative de quiconque) de contourner, d'effectuer une ingénierie inverse, de décrypter ou de modifier ou d'interférer avec les Services, ou tout contenu des Services, ou de faire une utilisation non autorisée des Services. Sans le consentement écrit préalable de NYT, vous ne devez pas :
(1) accéder à toute partie des Services, du Contenu, des données ou des informations auxquelles vous n'avez pas la permission ou l'autorisation d'accéder ou pour lesquelles NYT a révoqué votre accès ;
(2) utiliser des robots, des scripts, des services, des logiciels ou tout dispositif, outil ou processus manuel ou automatique conçu pour extraire des données ou récupérer le contenu, les données ou les informations des services, ou utiliser, accéder ou collecter le contenu des données ou informations des Services utilisant des moyens automatisés ;
(3) utiliser le Contenu pour le développement de tout programme logiciel, y compris, mais sans s'y limiter, la formation d'un système d'apprentissage automatique ou d'intelligence artificielle (IA).
(4) utiliser des services, des logiciels ou tout dispositif, outil ou processus manuel ou automatique conçu pour contourner toute restriction, condition ou mesure technologique qui contrôle l'accès aux Services de quelque manière que ce soit, y compris le remplacement de toute fonction de sécurité ou le contournement ou le contournement de tout accès contrôler ou utiliser les limites des Services ;
(5) mettre en cache ou archiver le Contenu (à l'exception de l'utilisation par un moteur de recherche public pour créer des index de recherche) ;
(6) prendre des mesures qui imposent une charge déraisonnable ou disproportionnée sur notre réseau ou notre infrastructure ; et
(7) faire tout ce qui pourrait désactiver, endommager ou modifier le fonctionnement ou l'apparence des Services, y compris la présentation de publicités.
4.2 S'engager dans une utilisation interdite des Services peut entraîner des sanctions civiles, pénales et/ou administratives, des amendes ou des sanctions à l'encontre de l'utilisateur et de ceux qui l'assistent.










 Répondre avec citation
Répondre avec citation



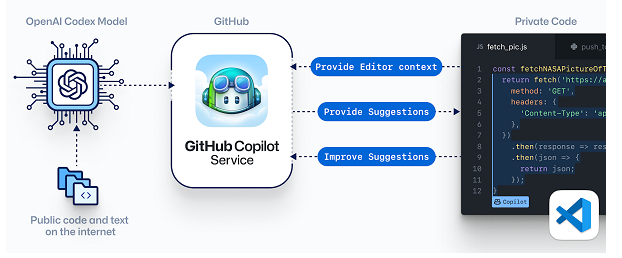
 Que pensez-vous de Copilot ?
Que pensez-vous de Copilot ?
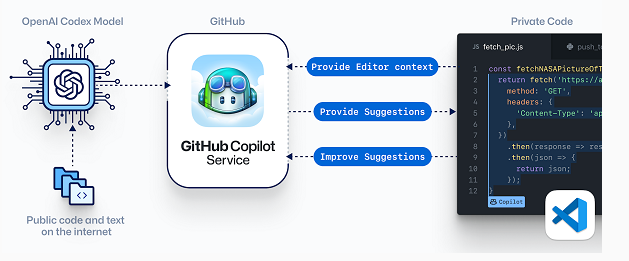


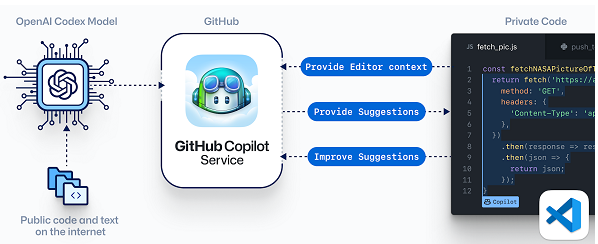
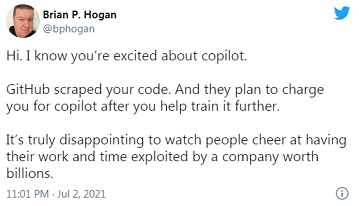


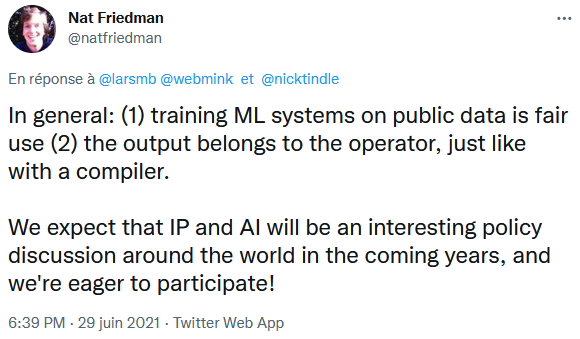
 Bien sur qu'ils contestent, quelle blague sérieux.
Bien sur qu'ils contestent, quelle blague sérieux.














Partager