













DuckDB, le SGBD utilisé par Google, Facebook et Airbnb, arrive en version 0.5.0
elle apporte l'optimisation de l'ordre de jointure
DuckDB, le système de gestion de bases de données (SGBD) analytiques en cours de développement utilisé par Google, Facebook et Airbnb, vient de sortir sa version 0.5.0. Fruit du travail d'universitaires du centre de recherche en mathématiques et en informatique théorique Centrum Wiskunde & Informatica d'Amsterdam, DuckDB est intégré à un processus hôte. Il n'y a pas de logiciel serveur SGBD à installer, à mettre à jour ou à maintenir.
Par exemple, le paquetage Python de DuckDB peut exécuter des requêtes directement sur les données de la bibliothèque logicielle Pandas de Python, sans importer ni copier de données. Écrit en C++, DuckDB est gratuit et open source sous la licence MIT.
DuckDB utilise des index ART (Adaptive Radix Tree) pour faire respecter les contraintes et accélérer les filtres de requête. Jusqu'à présent, les index n'étaient pas persistants, ce qui entraînait des problèmes tels que la perte des informations d'indexation et des temps de rechargement élevés pour les tables avec des contraintes de données.
Les conseils et l'assistance sont fournis par DuckDB Labs. Le cofondateur et PDG Hannes Mühleisen, qui a également coécrit le code et assure la maintenance du projet, a déclaré qu'il s'était inspiré de SQLite, le moteur de base de données OLTP sans serveur, où il a vu l'opportunité d'une approche similaire, mais pour l'analytique.
« Nous travaillions beaucoup avec des praticiens de la science des données et ils avaient tous ces problèmes qui n'étaient plus des problèmes théoriques dans la recherche informatique - ils ont été résolus il y a des siècles - mais d'une manière ou d'une autre, le logiciel n'était tout simplement pas là pour eux. Avec les fournisseurs de logiciels commerciaux, la technologie se trouvait dans certains de ces paquets, mais n'était pas accessible ou était cachée derrière de très nombreuses couches de conneries d'entreprise », a-t-il déclaré.
Index ART
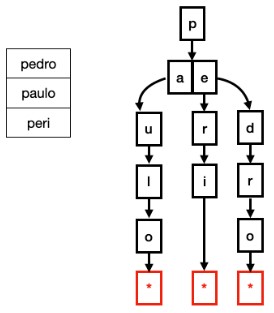
Les Adaptive Radix Trees sont, par essence, des Tries qui appliquent une compression verticale et horizontale pour créer des structures d'index compactes. Les Tries sont des structures de données arborescentes, où chaque niveau de l'arbre contient des informations sur une partie de l'ensemble de données. Elles sont généralement illustrées par des chaînes de caractères. Dans la figure ci-dessous, vous pouvez voir une représentation Trie d'une table contenant les chaînes de caractères "pedro", "paulo" et "peri". Le nud racine représente le premier caractère "p" avec des enfants "a" (de paulo) et "e" (de pedro et peri), et ainsi de suite.
Mühleisen et son cofondateur ont commencé à réaliser qu'une refonte de l'architecture de la base de données pourrait être nécessaire pour OLAP. « Nous avons repris l'idée des systèmes de gestion des données en cours d'exécution, où l'ensemble du gestionnaire de base de données fonctionne au sein du processus dans lequel vous vous trouvez - par exemple, Python ou même Excel - et nous avons repensé un système pour qu'il soit le premier de sa catégorie pour OLAP en utilisant cette approche », a déclaré Mühleisen, qui est toujours chercheur principal dans son institution universitaire.
DuckDB est également souvent utilisé dans le cadre d'une pile analytique ou de gestion de données plus large. Par exemple, si quelqu'un construit une application personnalisée qui collecte des données et souhaite ensuite créer une interface SQL, il devait auparavant copier les données et les déplacer dans un autre système, ce qui pouvait poser des problèmes de synchronisation, a-t-il expliqué.
Mais DuckDB peut interroger des ensembles de données tiers comme s'il s'agissait de ses propres données. « Vous pouvez l'intégrer à une application ou à un ensemble de données existant. Et c'est ce que font les gens » , a-t-il ajouté. La popularité du système parmi les constructeurs d'outils de données a même suscité son propre mème. La première version a été publiée en 2019 et n'a cessé depuis de gagner en popularité, avec des utilisateurs comme Google, Facebook et Airbnb.
Parmi les nouvelles fonctionnalités, citons "out of core", qui vise à résoudre les problèmes qui peuvent survenir lorsque les données en cours de traitement sont plus volumineuses que la mémoire en proposant des résultats intermédiaires. Le projet a également ajouté l'optimisation de l'ordre de jointure, un problème récurrent dans les bases de données analytiques. Hyoun Park, PDG et analyste en chef chez Amalgam Insights, a déclaré que la différenciation de DuckDB vient du fait qu'il s'agit d'une petite application qui fonctionne dans le cadre de processus basés sur le code pour analyser rapidement de grands magasins de données.
« Cela est de plus en plus important car les charges de travail sont distribuées, les performances sont nécessaires dans une variété de cas d'utilisation analytique, et les données analytiques continuent de doubler d'année en année dans les grandes organisations », a déclaré Park. "En tant que base de données open source facilement intégrable dans des tâches analytiques spécifiques, DuckDB est bien adapté pour combler les lacunes là où les bases de données OLAP monolithiques traditionnelles sont plus rigides, plus coûteuses ou nécessitent des efforts de transfert et de duplication pour supporter la variété analytique.
« DuckDB peut souvent exécuter des requêtes directement sur les données sans traitement intermédiaire, ce qui améliore le traitement. D'un point de vue purement technologique, il est quelque peu similaire à Actian Vector, qui adopte également une approche de requête OLAP vectorisée en colonnes, bien qu'Actian soit conçu pour apporter des données plutôt que de travailler dans un processus ou une charge de travail spécifique. »
Mais il existe des limites claires quant au moment et à l'endroit où le système doit et ne doit pas être utilisé. Bien qu'à certains égards, il offre une alternative bon marché à un entrepôt de données, et pourrait offrir à chaque spécialiste des données un système sur son ordinateur portable, il ne remplace pas nécessairement les systèmes d'entrepôt de données d'entreprise de sociétés telles que Teradata, Oracle et IBM. La page d'accueil indique clairement qu'il ne doit pas être utilisé pour « de grandes installations client/serveur pour l'entreposage centralisé de données d'entreprise. » « C'est une question de priorité pour votre organisation ou le problème des données. Est-ce qu'il faut vraiment que tout le monde travaille sur les mêmes données ? Si c'est le cas, ce n'est peut-être pas la meilleure solution », a déclaré Mühleisen.
S'agissant de bases de données open source, le projet arrive avec un nom inhabituel. Alors que CockroachDB a été baptisé en raison de sa nature supposée immuable, et que MongoDB est une contraction de "humongous", DuckDB a bien sûr été nommé en l'honneur de Wilbur, l'animal de compagnie de Mühleisen, qui est d'ailleurs apparu dans le journal The Guardian.
Le projet travaille à la sortie de la version 1.0, après laquelle les modifications rétrogrades ne seront plus possibles. « Je pense que nous y arrivons avec beaucoup de travail. Nous disons toujours d'ici la fin de l'année, mais je crains que cela ne se produise pas cette année », a déclaré Mühleisen.
Une expérience utilisateur élégante est l'un des principaux objectifs de conception de DuckDB. Cet objectif guide une grande partie de l'architecture de DuckDB : il est simple à installer et facile à intégrer. La parallélisation se fait automatiquement et si un calcul dépasse la mémoire disponible, les données sont gracieusement mises en mémoire tampon sur le disque. Et bien sûr, la vitesse de traitement de DuckDB permet d'accomplir plus de travail. Cependant, selon les responsables de DuckDB, SQL n'est pas réputé pour être convivial. DuckDB veut changer cela ! DuckDB comprend à la fois une API relationnelle pour le calcul de type dataframe et une version de SQL hautement compatible avec Postgres.
La jointure des tables par ligne est l'une des opérations fondamentales et distinctives du modèle relationnel. Une jointure relie deux tables horizontalement en utilisant une condition booléenne appelée prédicat. Cela semble simple, mais la vitesse d'exécution de la jointure dépend des expressions du prédicat. Cela a conduit à la création de différents algorithmes de jointure qui sont optimisés pour différents types de prédicats.
Source : Duckdb
Et vous ?
Quel est votre avis surle sujet ?
Voir aussi :

 Répondre avec citation
Répondre avec citation
Partager