











Je comprend bien l'objection, et la réticence suscitée l'accumulation des valeurs extrêmes.Envoyé par AbsoluteLogic

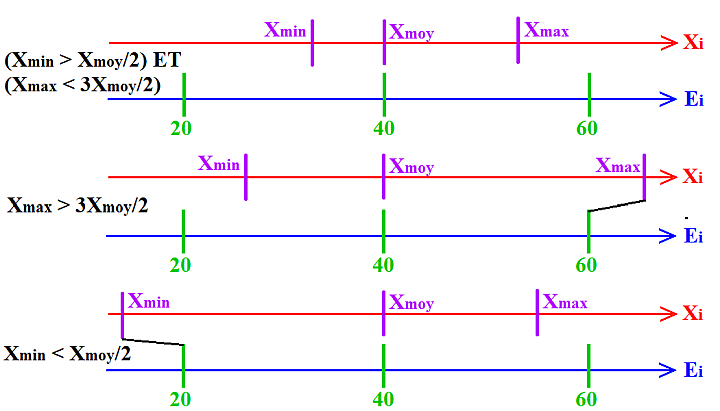
La difficulté provient de l'écart considérable séparant la distribution uniforme sur [0 ; 1[ des valeurs retournées par une fonction pseudo-aléatoire, et la distribution très resserrée exigée par l'énoncé:
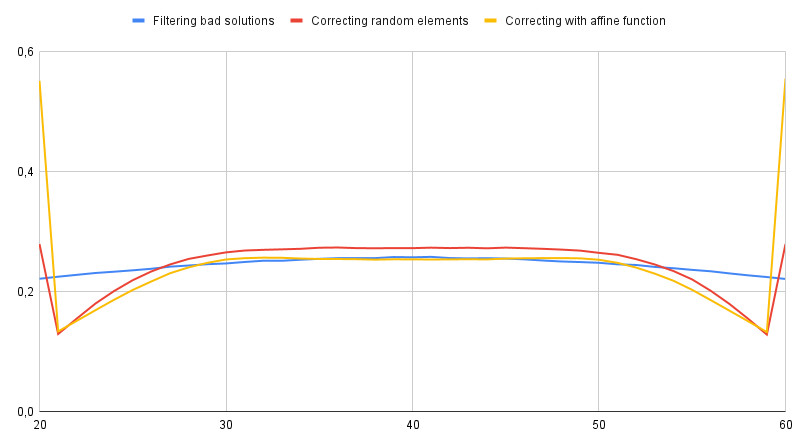
Vmoy/2 ≤ Vmin ; Vmax ≤ 3.Vmoy/2 ,qui n'est fortuitement réalisée que pour une faible proportion des tirages (~1.5 %).
Elle provient aussi de l'absence, dans l'énoncé, de toute indication concernant le type de calculs ou la densité de probabilité des valeurs obtenues, laissant ainsi libre cours à l'inventivité de chacun.
Pour en revenir à la difficulté initialement évoquée, le tirage d'une valeur aléatoire supplémentaire (Kal) permet de passer à une seconde suite finie de 10 valeurs réelles:
Yj = Xmoy + Kal*(Xj - Xmoy)à partir de laquelle on peut recalculer (Ymin, Ymoy, Ymax), ainsi que les rapports Rmin = Ymin/Ymoy et Rmax = Ymax/Ymoy ; le cas idéal se retrouve alors réalisé beaucoup plus souvent (55 % des cas):
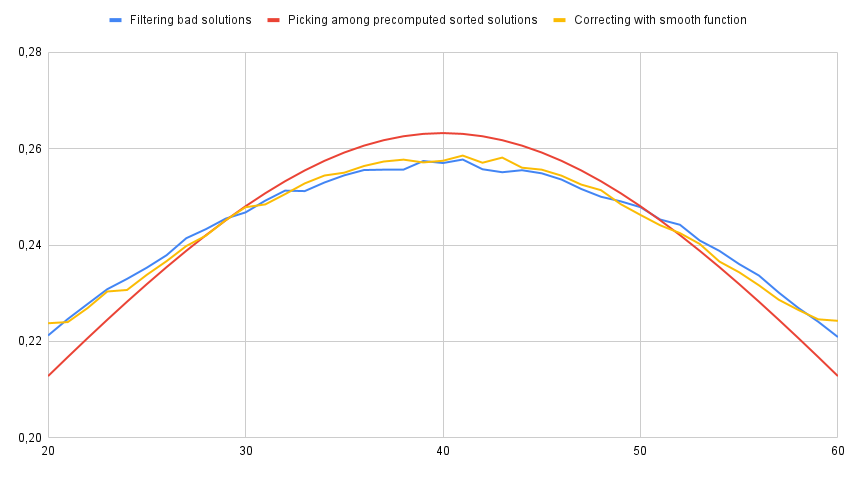
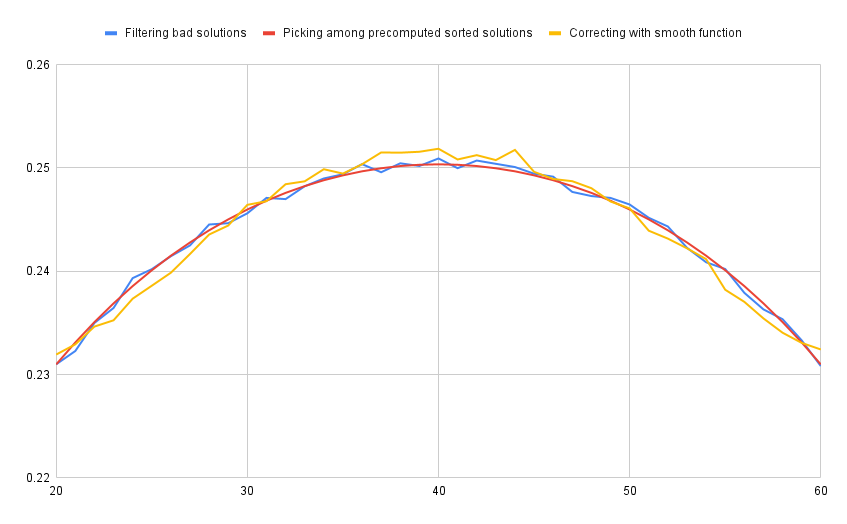
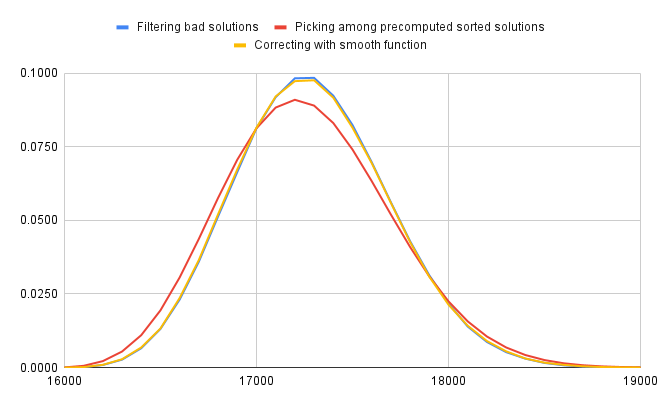
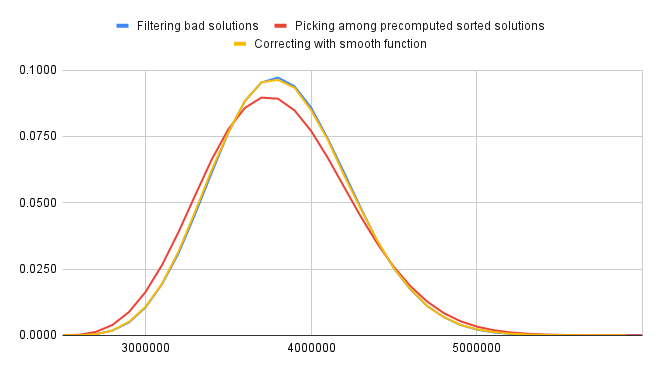
À ce stade, on pourrait ne plus tenir compte des tirages défavorables, désormais minoritaires.
 Répondre avec citation
Répondre avec citation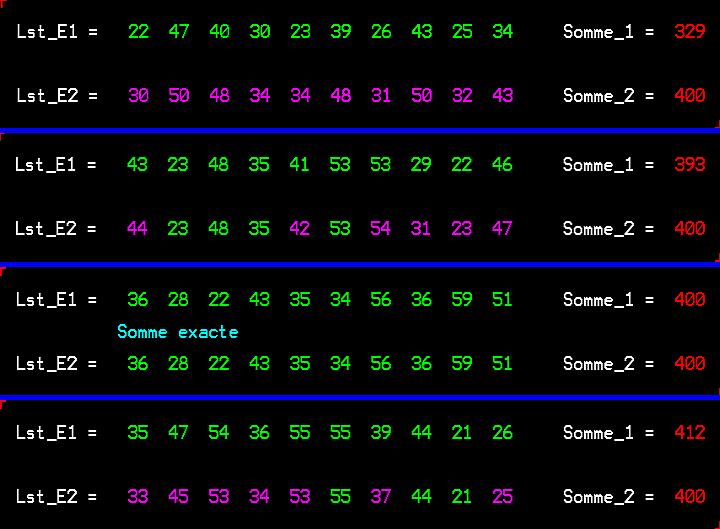










 en bas à droite du message.
en bas à droite du message.


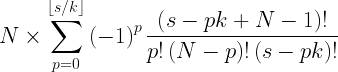

 ).
).
Partager