










Bonjour,
J'aimerais si possible avoir de l'aide pour faire une requête sur IBM DB2 ; je travaille, en tant qu'étudiant sur un projet immobilier. j'ai 3 tables
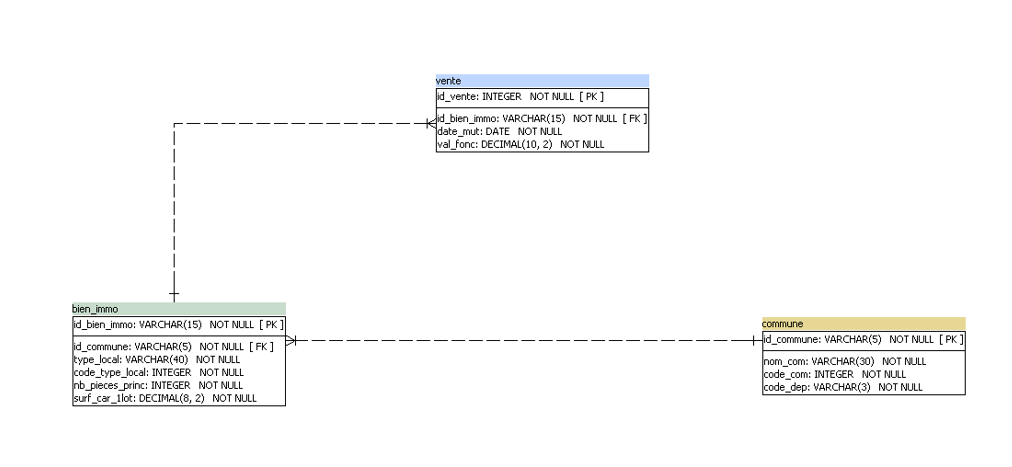
Des erreurs apparaissent quand je lance ma requête ( je cherche à trouver la Liste des communes où le nombre de ventes a augmenté d'au moins 20% entre le premier et le second trimestre de 2020)
.
Les 2 sous requêtes donnent bien des resultats , je pense que les problemes vienennt de la fin dans la division si le nb de ventes du 1er trim est de 0 ; ou bien la nomination des colonnes ambigues...
Où si vous suggérez une autre façon décrire cette requête je suis preneur")
Merci
 Répondre avec citation
Répondre avec citation




 N'oubliez pas le bouton
N'oubliez pas le bouton  et pensez aux balises [code]
et pensez aux balises [code]









Partager