















kotlinx.serialization : la version 1.2 de la bibliothèque de sérialisation disponible
avec un traitement JSON deux fois plus rapide, la prise en charge des classes value et plus encore
kotlinx.serialization 1.2 est disponible. La dernière version de la bibliothèque de sérialisation multiplateforme apporte un certain nombre daméliorations, notamment :
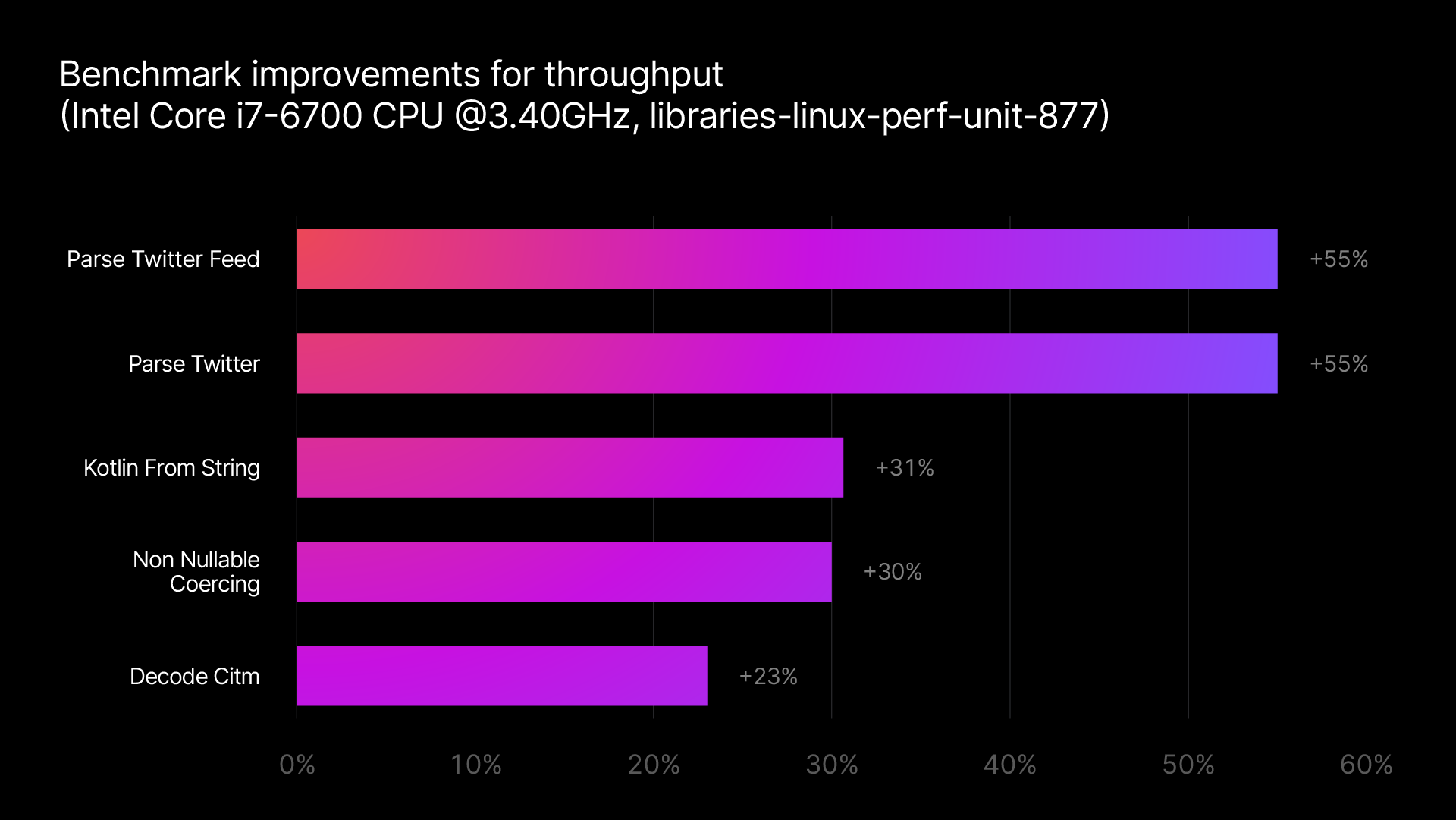
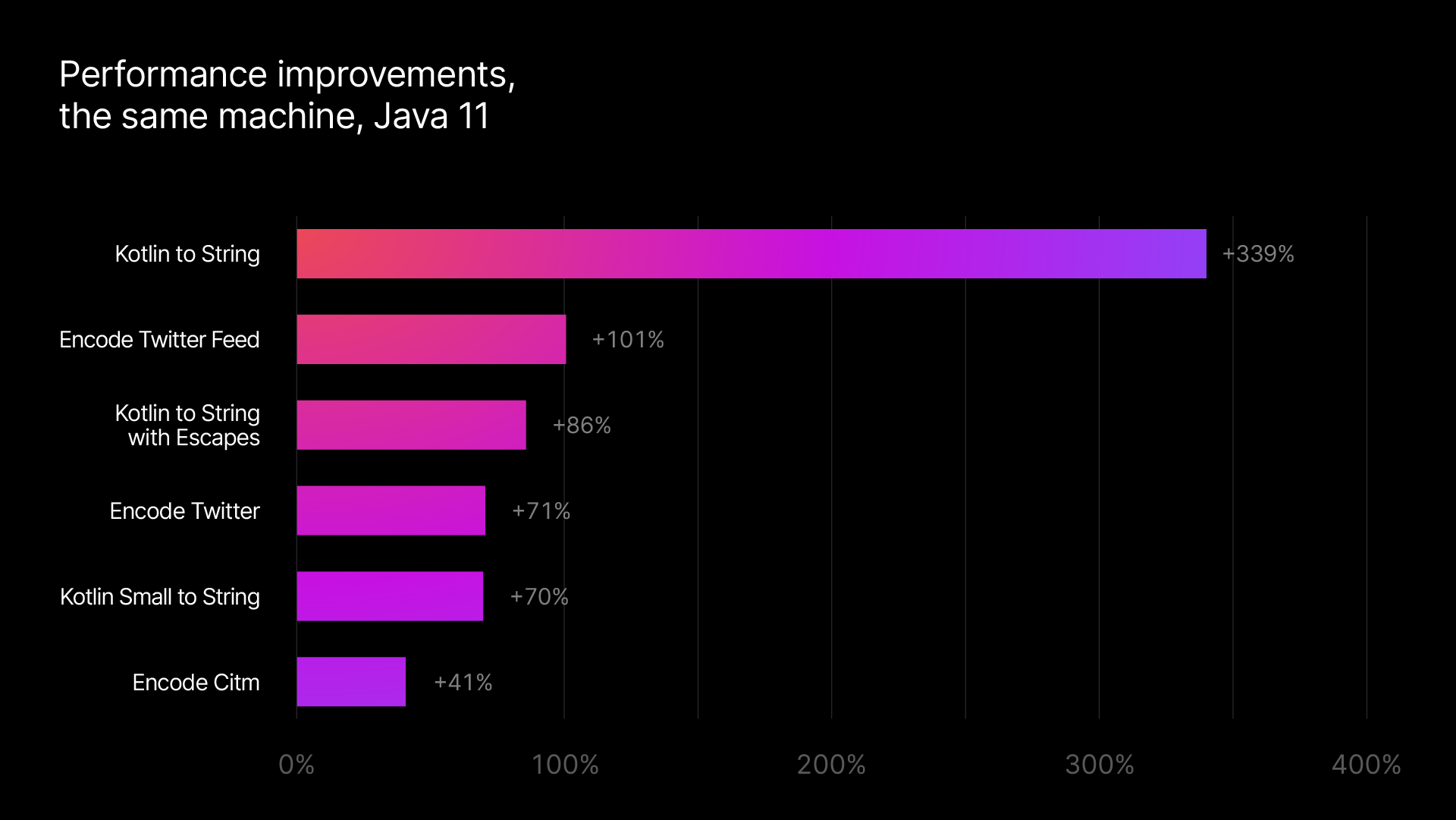
- Une augmentation significative de la vitesse de la sérialisation JSON. Avec la version 1.2 , lanalyse de JSON en objets Kotlin de type sécurisé et la conversion des objets Kotlin en représentations textuelles sont jusquà deux fois plus rapides quavec la version précédente.
- Les ajouts au système de types de Kotlin 1.5 sont désormais pris en charge. Les classes value et les nombres non signés peuvent être convertis en JSON et inversement, comme toute autre classe Kotlin.
- La nouvelle documentation de lAPI facilite la découverte des différentes fonctionnalités de kotlinx.serialization.
La version 1.2 apporte aussi une nouvelle prise en charge des noms alternatifs pour les champs JSON et une nouvelle approche expérimentale qui génère automatiquement des schémas Protobuf à partir de classes Kotlin, une fonctionnalité à propos de laquelle JetBrains aimerait avoir vos commentaires.
Examinons ensemble les changements et les ajouts que comporte cette nouvelle version.
Encodage et décodage JSON bien plus rapides
La possibilité dencoder les classes Kotlin en chaînes JSON et celle de transformer les chaînes JSON en classes Kotlin sont les fonctionnalités les plus utilisées de kotlinx.serialization, et JetBrains travaille constamment à les rendre plus performantes.
La version 1.2 remanie complètement la structure interne de kotlinx.serialization, ce qui permet dobtenir de bien meilleures performances pour ces fonctionnalités essentielles. JetBrains a réécrit son décodeur JSON (pour la conversion de texte en objets Kotlin) et apporté dimportantes optimisations à son encodeur JSON (pour la conversion des objets Kotlin en texte).
En utilisant la dernière version de la bibliothèque, vous pouvez bénéficier dune vitesse jusquà deux fois supérieure pour les tâches de codage et de décodage classiques. Avec ces changements, kotlinx.serialization atteint le même niveau de performance (voire un niveau supérieur à certains égards) que dautres autres bibliothèques JSON prêtes à lemploi. Même les extraits de code les plus simples bénéficient de ces améliorations :
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
La meilleure façon de se faire une idée de ces améliorations est de tester votre propre application avec la dernière version de la bibliothèque. Pour une estimation des performances, vous pouvez consulter les benchmarks internes de JetBrains pour lencodage et le décodage qui comparent la dernière version de kotlinx.serialization à la précédente version .
Sérialisation et désérialisation JSON stable pour les classes value et les types de nombres non signés
La version 1.5.0 de Kotlin récemment publiée a apporté les classes value et les types dentiers non signés, pour lesquels kotlinx.serialization 1.2 offre maintenant une prise en charge de lencodage et du décodage JSON de premier ordre. Voyons cela de plus près.
Prise en charge des classes value
Les classes value (auparavant appelées classes inline) sont un moyen dencapsuler un autre type Kotlin (par exemple, un nombre) de manière sécurisée, sans risque de surcharge lors de lexécution. Cela permet de rendre vos programmes plus expressifs et sûrs, sans affecter les performances.
La sérialisation JSON intégrée de kotlinx.serialization fonctionne maintenant pour les classes value. Comme pour les autres classes Kotlin, il suffit dannoter une classe value avec @Serializable.
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
Les classes value sont stockées (et sérialisées) directement comme leur type sous-jacent. Nous pouvons le voir en ajoutant un champ avec un type value class à une data class sérialisable et en examinant sa sortie :
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
Dans lexemple ci-dessus, NamedColor traite la value class Color comme la primitive sous-jacente (un Int). Cela signifie que vous bénéficiez dune sécurité de type maximale dans votre code Kotlin, tout en profitant dune représentation sérialisée concise de ces types, sans encapsulation ou imbrication inutile.
JetBrains est toujours en train daffiner le design des sérialiseurs personnalisés écrits à la main pour les classes value class et ils sont encore en phase expérimentale.
Prise en charge des entiers non signés
Les entiers non signés sont un ajout à la bibliothèque standard de Kotlin qui fournit des types et des opérations pour les nombres non négatifs. Avec la publication de Kotlin 1.5.0, les types de nombres non signés suivants sont disponibles :
- UByte, avec des valeurs de 0 à 255
- UShort, avec des valeurs de 0 à 65535
- UInt, avec des valeurs de 0 à 2^32 1
- ULong, avec des valeurs de 0 à 2^64 1
Lencodeur et le décodeur JSON dans kotlinx.serialization prennent maintenant directement en charge ces types. Tout comme pour les autres types de nombres, les valeurs entières non signées seront sérialisées dans leur représentation numérique standard (la même représentation que vous voyez en invoquant .toString), sans troncature, encapsulation ou conversion en types signés.
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
Veuillez noter que la prise en charge des classes value et des entiers non signés est actuellement disponible pour JSON. Dans une prochaine version, JetBrains fournira également des intégrations directes pour CBOR et Protobuf.
Prise en charge des noms alternatifs pour les champs JSON
Vous avez parfois besoin danalyser des champs JSON portant des noms différents, mais ayant la même signification, par exemple pour maintenir une compatibilité rétroactive. Avec la nouvelle annotation @JsonNames, vous pouvez désormais donner aux champs JSON des noms alternatifs, qui seront utilisés lors du processus de décodage.
Pour illustrer cela, prenons un exemple. Supposons quen fonction de sa version, un serveur nous donne lune des deux réponses suivantes :
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
name et title ont tous deux la même signification et nous voulons les mapper sur le même champ dans notre classe Kotlin. Avec la nouvelle annotation @JsonNames, nous pouvons spécifier title comme clé alternative pour la clé name :
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
Vous remarquerez la différence avec lannotation @SerialName, qui vous permet de renommer les champs pour lencodage et le décodage, mais ne vous permet pas de spécifier des alternatives. Cette fonctionnalité devrait vous permettre de travailler plus facilement avec des services qui renvoient des champs nommés différemment représentant les mêmes valeurs, de survivre aux migrations de schémas et dassurer des mises à jour harmonieuses de vos applications.
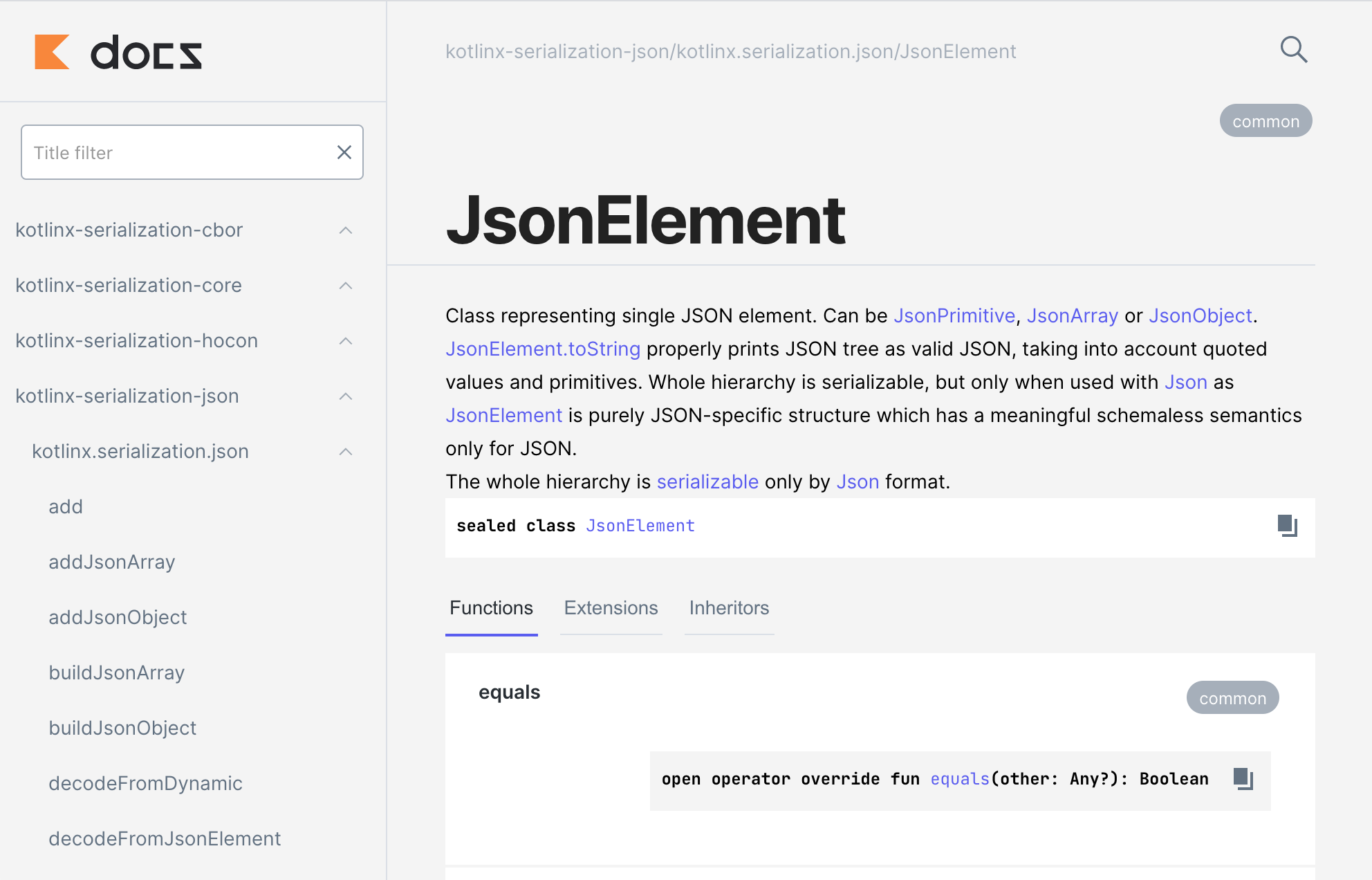
Nouvelle documentation de lAPI
Pour rendre votre apprentissage de kotlinx.serialization aussi simple et agréable que possible, JetBrains propose plusieurs documents de référence. Lun deux est le Guide Kotlin Serialization sur GitHub, qui présente les fonctionnalités de la bibliothèque et inclut des exemples complets pour vous aider à bien comprendre chaque fonctionnalité.
Par ailleurs, JetBrains a totalement remanié la documentation de lAPI kotlinx.serialization. Basée sur une nouvelle version de Dokka, le moteur de documentation de Kotlin, la documentation de lAPI dispose dun nouveau design adaptatif et moderne, ainsi que de symboles faciles à parcourir.
Protobuf : génération de schémas expérimentale à partir de classes Kotlin
Protocol Buffers (Protobuf) est un format de sérialisation binaire pour les données structurées créé par Google. En tant que format binaire, il requiert moins despace que JSON ou XML, tout en fournissant une structure indépendante du langage que vous pouvez utiliser pour la communication entre applications.
Avec kotlinx.serialization, vous pouvez utiliser la sérialisation multiplateforme Protobuf (en utilisant la sémantique Proto2) avec une stabilité expérimentale. Comme avec les autres formats, annotez votre classe comme @Serializable et utilisez les méthodes encode / decode intégrées :
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
Avec vos classes Kotlin comme source of truth (source de données unique et fiable), combinées à la personnalisation que vous pourriez vouloir appliquer, kotlinx.serialization est capable de déduire le schéma binaire des données, rendant ainsi la communication Protobuf entre plusieurs applications Kotlin concise et pratique.
kotlinx.serialization 1.2 comprend maintenant aussi un générateur de schémas expérimental pour Protocol Buffers. Il vous permet de générer des fichiers .proto à partir de vos classes de données Kotlin, qui peuvent à leur tour être utilisées pour générer des représentations de vos schémas de communication dans dautres langages, notamment Python, C++ et TypeScript.
Une fois le fichier .proto généré, vous pouvez le stocker dans votre référentiel et lutiliser pour générer des représentations de vos classes Kotlin dans dautres langages. Cela devrait vous permettre dutiliser plus facilement lintégration Protobuf de kotlinx.serialization dans des applications multilangages, sans avoir à renoncer à la commodité de gérer vos schémas directement dans le code source Kotlin.
Il sagit de la première itération du générateur de schémas Protobuf. JetBrains compte donc sur vos retours. N'hésitez pas à l'essayer et faire un retour sur vos cas dutilisation, de la façon dont vous gérez vos modèles et vos fichiers .proto, des problèmes que vous rencontrez et des fonctionnalités dont vous voudriez disposer.
Gardez à lesprit que le générateur de schémas comprend certaines limites. En règle générale, si une classe Kotlin peut être sérialisée avec limplémentation protobuf incluse dans kotlinx.serialization, alors le générateur de schémas la prendra en charge. Cela signifie également que les mêmes restrictions sappliquent. Voici quelques points à surveiller :
- Les classes et noms de propriétés de Kotlin doivent se conformer à la spécification de protobuf et ne pas contenir de caractères non autorisés.
- La nullabilité de Kotlin nest pas reflétée dans le schéma (parce que proto2 na pas de sémantique pour cela). Les champs optionnels tels que fournis par protocol buffers sont utilisés si vos propriétés Kotlin définissent des valeurs par défaut.
- Les valeurs par défaut de Kotlin ne sont pas incluses dans le schéma (ce qui signifie que vous devrez assurer vous-même la cohérence des valeurs par défaut dans les différentes implémentations du langage).
Pour commencer à utiliser kotlinx.serialization 1.2
Si vous utilisez déjà kotlinx.serialization, la mise à niveau vers la version 1.2 est très rapide. Et si vous navez pas encore essayé kotlinx.serialization, vous pouvez tester cette nouvelle version. Tout dabord, mettez à jour le bloc plugins dans votre fichier build.gradle.kts :
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
Ensuite, mettez à jour votre bloc dependencies avec la bibliothèque dexécution, y compris les formats que vous voulez utiliser dans votre application :
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
Explorez la nouvelle documentation d'API de Kotlinx.serialisation
 Répondre avec citation
Répondre avec citation
Partager