Bonjour,
Malgré l'en-tête de la discussion, la courbe de référence s'apparente moins à un graphe logarithmique qu'à celui d'une fonction puissance
y = K.x
n , avec n ~ 1/2 :
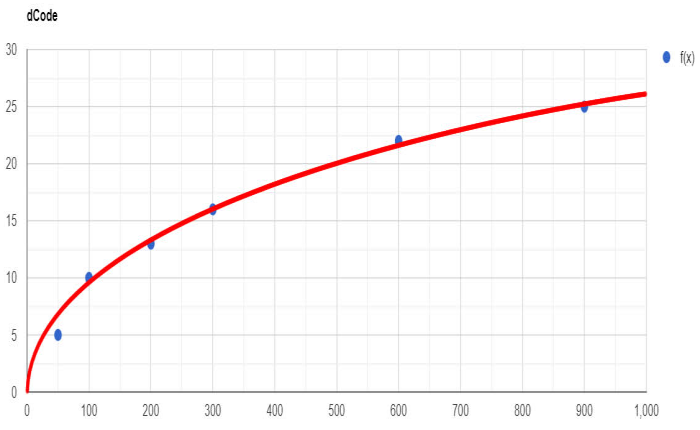
On pourrait donc procéder à une régression linéaire sur les logarithmes des coordonnées:
Ln(y) = a + b.Ln(x) , avec a = Ln(K) et b = n ;
on trouve: a = 2.943252101 , n = 0.5305254408 , K = ea = 18.97746268 , σ = (1 - r2)1/2 = 0.196
soit donc une dispersion moyenne de l'ordre de 20 % .
Les valeurs recalculées pour l'ordonnée sont les suivantes:
5904 8528 12319 15275 22065 27360
d'où pour le second point un écart de 15% par rapport à l'ordonnée y = F(100E3) = 10E3 .
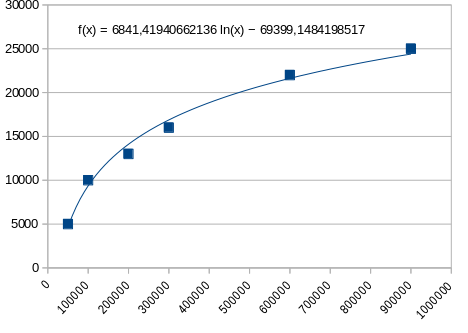
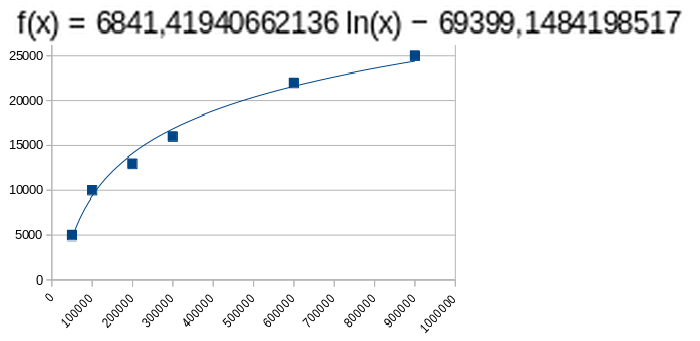
# La régression semi-logarithmique proposée par Flodelarab
donne pour le second point un écart moindre: 6 % , puisque (y2) vaut dans ce cas: 9366 .
Un problème subsiste cependant, entrevu par Ehouarn: l'obligation imposée à tous les graphes de passer exactement par un point donné, contrainte clairement exprimée par l'auteur du sujet:

Envoyé par
Mike91

... J'ai par contre impérativement besoin qu'elle passe par le deuxième point si possible (100 000 => 10 000) ...
Il faut par conséquent mettre à part le second point, qui ne peut être mis sur le même plan que les autres pour le traitement statistique du nuage.
# Revenons-en à la première fonction: on n'affecte pas sensiblement la dispersion en prenant n = 0.5 , soit: 1/2 ;
ce qui revient à imposer à fonction recherchée l'expression approchée: F(x) = (1000*x)1/2
compatible avec la contrainte: x2 = E5 ==> y2 = E4 .
On envisage donc la nouvelle fonction:
G(x) = F(x)[1 + a(F(x) - y2) + b(F(x) - y2)2)
extension naturelle de la précédente, et dont une transformation appropriée se prête à une nouvelle régression linéaire:
H(x) = [G(x)/F(x) - 1]/(F(x) - y2) = a + b(F(x) - y2) .
ma calculette donne: a = -3.75300E-6 , b = 5.30219E-12 , r = 0.614 , σ = .789 ;
la dispersion est ici énorme, mais elle concerne des termes correctifs de moindre importance, et provient de la disposition erratique d'un petit nombre de points autour du graphe moyen.
Il faut un plus grand nombre de données pour obtenir des moyennes plus fiables.
D'autres solution numériques sont bien sûr envisageables.









alors j'aurais besoin d'un peu d'aide si possible.
 Répondre avec citation
Répondre avec citation



 en bas à droite du message.
en bas à droite du message.


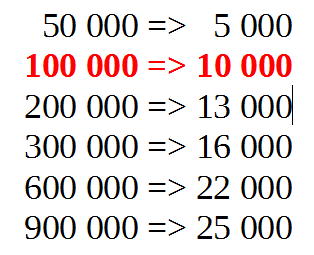



Partager