1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| import matplotlib
import matplotlib.pyplot as plt
from re import findall
import locale
locale.setlocale(locale.LC_ALL, ('fr_FR', 'UTF-8'))
matplotlib.rc('font', family='Arial')
matplotlib.pyplot.xticks(fontsize=14)
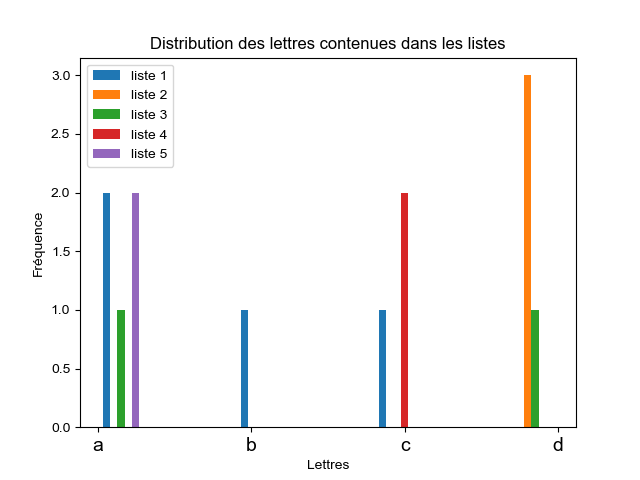
plt.hist([["a", "b", "a", "c"], ["d", "d", "d"],
["a", "d"], ["c", "c"], ["a", "a"]])
plt.title("Distribution des lettres contenues dans les listes")
plt.xlabel("Lettres")
plt.ylabel("Fréquence")
plt.legend(["liste 1", "liste 2", "liste 3", "liste 4", "liste 5"])
plt.show()
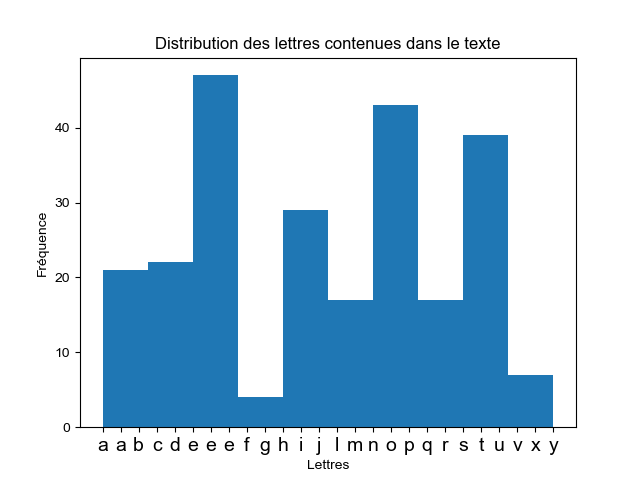
texte = """Bonjour, l'idée est de faire un l'histogramme en pièce jointe en python via matplotlib.
Après pas mal de recherche (je débute en python) et d'essai je n'arrive pas à trouver une solution
qui me convient.
L'idée serait d'afficher les position des occurences d'élément dans une chaine de caractère
par exemple: !"""
lst = sorted(findall(
'[a-zA-Z\u00C0-\u00D6\u00D8-\u00F6\u00F8-\u00FF]', texte.lower()), key=locale.strxfrm)
print(lst)
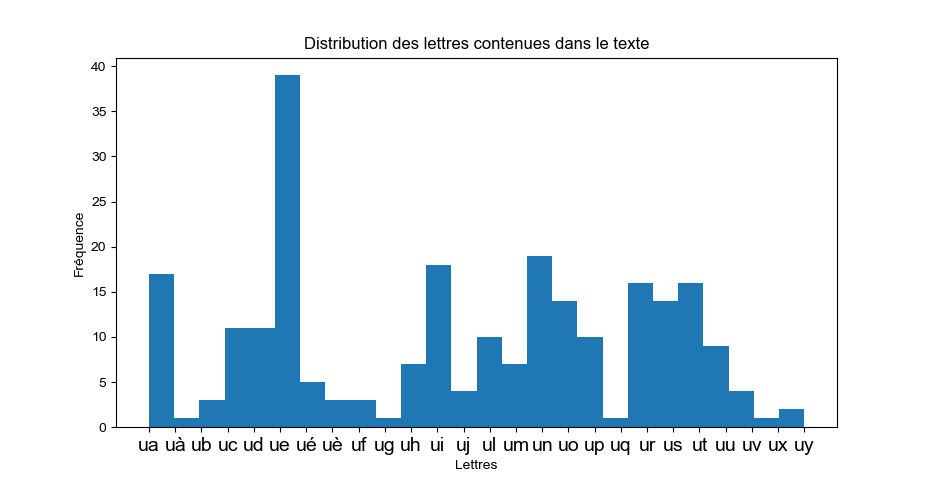
""" Les caractères accentués sont bien présents dans le texte mais pas dans hist """
matplotlib.rc('font', family='Arial')
matplotlib.pyplot.xticks(fontsize=14)
plt.hist(lst)
plt.title("Distribution des lettres contenues dans le texte")
plt.xlabel("Lettres")
plt.ylabel("Fréquence")
plt.show() |










 Répondre avec citation
Répondre avec citation













Partager