











Les compilations à la volée (Just-In-Time / JITs) ne seraient pas ergonomique
selon un développeur qui propose des améliorations
Les ordinateurs n'exécutent pas le code source que nous écrivons dans les langages de programmation, ils exécutent le code machine. Dans des circonstances normales, il existe deux façons de passer d'un langage de programmation au code machine :
- les compilateurs, qui créent une fois un exécutable en code machine à partir de votre code source, et vous pouvez exécuter ce blob encore et encore. Compilation lente, exécution rapide
- les interpréteurs, qui lisent le programme ligne par ligne lors de son exécution et exécutent un autre programme qui exécute ces lignes. Démarrage plus lent, performances plus lentes, mais aucune étape de compilation lente après les modifications.
Les langages compilés sont plus rapides et plus sûrs. Les langages interprétés sont plus flexibles, plus productifs et plus faciles à apprendre.
La compilation à la volée (just-in-time compilation ou JIT compilation en anglais) est une technique visant à améliorer la performance de systèmes compilés en bytecode par la traduction de bytecode en code machine natif au moment de l'exécution. La compilation à la volée se fonde sur deux anciennes idées : la compilation de bytecode et la compilation dynamique. Elle apporte donc le meilleur des deux mondes, en théorie.
La compilation à la volée s'adapte dynamiquement à la charge de travail courante du logiciel, en compilant le code « chaud », c'est-à-dire le code le plus utilisé à un moment donné (ce qui peut représenter tout le programme, mais souvent seules certaines parties du programme sont traitées par compilation à la volée). Obtenir du code machine optimisé se fait beaucoup plus rapidement depuis du bytecode que depuis du code source. Comme le bytecode déployé est portable, la compilation à la volée est envisageable pour tout type d'architecture, à la condition d'avoir un compilateur JIT pour cette architecture, ce qui est facilité par le fait que les compilateurs de bytecode en code machine sont plus faciles à écrire que les compilateurs code source - code natif.
La compilation à la volée ne serait pas ergonomique selon un développeur
Abe Winter est un développeur reconverti qui a des années d'expérience professionnelle en tant que programmeur avec différents paradigmes de langage (statique, dynamique, JIT). Il pense que JIT nest pas ergonomique :
« Le travail sur les performances en 2020 peut concerner autant la mise en cache et la conception intelligente de RPC que les performances linéaires d'une fonction. Mais les performances en ligne droite comptent toujours. Et l'ergonomie de mesure de la performance d'un morceau de code en ligne droite en prod est mauvaise.
« Jaccuse le JIT.
« J'aime l'idée de JIT, mais l'outillage est sous-développé. Le battage médiatique dit "compétitif avec C pour les fonctions numériques courtes", mais la réalité est "quelque part entre Python et Java". Cest comme un bus qui vous dépose à mi-chemin et ne vous laisse pas emporter de vélo. Il serait plus rapide de parcourir tout le chemin à vélo plutôt que den parcourir la moitié à pied ».
Voici les arguments quil avance pour soutenir son affirmation :
JS JIT rend le test de performance impossible
« Je ne sais pas comment faire ces choses en JavaScript :
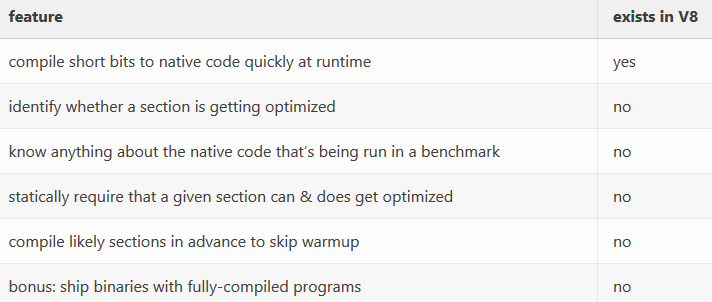
- savoir si une fonction est optimisée dans une exécution donnée ;
- savoir si une fonction sera optimisée en prod ;
- exiger statiquement qu'une fonction soit optimisée en prod ;
- être informé des dépôts dans les chemins critiques (hot paths).
« En l'absence d'un sous-ensemble de ces astuces, je n'ai aucun moyen de tester à la perfection mon code JS sans tester la charge à pleine échelle. Cela finit par être une énorme perte de temps et c'est la raison pour laquelle les gens réécrivent les services JS dans d'autres langages lorsqu'ils grandissent. »
Les benchmarks mentent
« C'est peut-être une façon forte de le dire. Mais les langages JIT rendent difficile l'utilisation du micro-benchmarking pour prédire les performances du même morceau de code en prod, pour plusieurs raisons:
- les benchmarks (qui exécutent la même fonction avec les mêmes entrées des millions de fois de suite) sont très amies avec la gigue (jitter en anglais, variation de la latence au fil du temps) ;
- la fonction que vous testez peut être appelée avec différentes entrées en prod. Dans JS, même l'ordre des clés dans un objet peut confondre le typer JIT ;
- si vous comparez une fonction JIT / native et que votre configuration de produit finit par utiliser du code interprété, vous n'aurez rien appris.
« Ne pas savoir combien de temps prend la réalité mène au vaudou et à la gymnastique.
« Oui, les langages compilés ont leur propre version de ceci avec une cohérence de cache. Oui, le JIT peut conduire à de meilleures performances que la précompilation en théorie à cause du collecteur de statistiques, mais je ne contrôle aucune de ces choses. »
Il est plus facile d'écrire du code performant (choisissez votre poison)
« Et plus important encore, maintenir le code performant. Ne vous méprenez pas, je ne dis pas que C++, Go ou Java sont des langages plus productifs que JS. Mais si votre budget est tel que les serveurs coûtent plus cher que la paie, il est difficile de conserver votre logique de base à grande échelle dans un langage interprété / JIT.
Pour deux raisons :
- loptimisation des hot paths : il y aura un moment où vous aurez besoin d'un chemin de code plus rapide et le JIT fera que cela marche comme si vous étiez en train de vous servir de la gélatine avec des pincettes ;
- des régressions de performances : quelqu'un va à un moment donné effectuer un changement moyen ou grand dans le code qui va dégrader subtilement les performances et nuire à la qualité du produit, et à moins que votre surveillance soit excellente, vous ne le saurez pas
Abe Winter ne demande pas dabandonner le système JIT, mais de laméliorer
« Tout ce que je demande, c'est des informations et un contrôle. La prémisse de base de JIT de compiler uniquement des parties de votre programme me convient. Je voudrais pouvoir contrôler les parties en questions et le moment de compilation.
« Je voudrais une collecte de statistiques efficace sur les dépôts en prod, donc je sais quelles fonctions traiter comme des hot paths.
« Les langages compilés ont un paquet d'astuces qui sont en quelque sorte sur ce sujet : optimisation guidée statistiquement, optimisation de programme entier. Les compilations à la volée y arriveront. »
Voici une liste déléments quil voudrait voir implémentés :
Source : Abe Winter
Et vous ?
Partagez-vous son avis ? Dans quelle mesure ?

 Répondre avec citation
Répondre avec citation




















Partager