










Bonjour,
Débutant
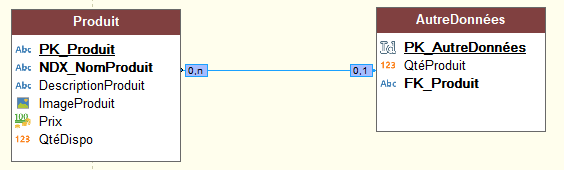
J'ai une Table alimenté par une requête FullText qui fonctionne bien.
je souhaiterais par programmation que mes références DEV0001 à DEV000X de ma table requête affichent les résultats de la rubrique quantité enregistré dans un autre fichier qui lui aussi a les même références.
Pour DEV0001 ma COL_Quantité de ma table requête affiche le résultat de mon fichier Quantité qui pour DEV0001 à pour dans la rubrique Qté le résultat correspondant.
Ceci pour toutes mes lignes de ma table. Car si j'ajoute à ma requête cette rubrique de mon fichier Quantité ma condition FullText est inopérante.
J'ai essayé en regardant du coté de HLIT et de POURTOUT mais je n'y arrive pas.
J'espère avoir été clair même si c'est mal formulé
Merci pour votre aide.
 Répondre avec citation
Répondre avec citation










Partager