











Apache Brooklyn 1.0, l'infrastructure open source pour la modélisation, la surveillance et la gestion des apps déployées sur site ou dans le cloud,
est disponible en production
La Apache Software Foundation a publié Apache Brooklyn 1.0, une version de production de l'infrastructure open source pour la modélisation, la surveillance et la gestion des applications déployées sur site ou dans le cloud. Brooklyn utilise des blueprints YAML pour décrire une application et ses composants. Ces blueprints, qui intègrent des politiques de gestion d'une application, peuvent être traités comme des composants modulaires qui peuvent être composés et réutilisés de nombreuses manières.
Le terme blueprint désigne, en anglais, une reproduction d'un plan détaillé, ce que l'on appelle en dessin technique un dessin de définition. Ce terme, en tant qu'anglicisme, est utilisé dans certains domaines pour désigner une représentation spatiale d'un objet, selon un ou plusieurs points de vue définis par les standards du dessin industriel ou du dessin architectural (vue de face, de droite, de gauche, de dessus, de dessous, de derrière). Les blueprints sont utilisés, entre autres, par les modeleurs tridimensionnels, afin de sculpter à partir d'une référence, pour respecter l'échelle dudit objet.
Les blueprints de Brooklyn réagissent aux entrées telles que l'intégrité des applications ou la charge du système et prennent des mesures telles que la croissance d'un cluster ou le remplacement de nuds. Un blueprint peut être étendu via Java, les utilisateurs pouvant créer de nouvelles entités, stratégies et opérations «effectrices» à l'aide de ponts Java ou JVM.
Le projet fournit des blueprints pour des applications et des outils tels que Elasticsearch, les clusters MySQL et la gestion DNS. Les projets Apache tels que CouchDB et Kafka sont également pris en charge.
Avec une API et une interface graphique REST, les capacités de Brooklyn incluent:
- Surveillance de l'intégrité et des mesures d'une application.
- Comprendre les dépendances entre les composants.
- Appliquer des politiques complexes pour gérer les applications.
- Gestion du provisionnement et du déploiement des applications.
Brooklyn a été utilisée par des fournisseurs de logiciels et de services cloud, par des intégrateurs de systèmes mondiaux et par des applications dans des domaines tels que les services financiers et la gestion de la chaîne d'approvisionnement. Le framework prend en charge les clouds publics et privés.
Caractéristiques
Blueprinting
- Blueprints composables : une spécification de service YAML peut faire référence à d'autres blueprints, dans le catalogue ou par URL, et peut fournir une configuration personnalisée.
- Spécifications des machines portables - ou identifiants spécifiques à l'emplacement : définissez les spécifications des machines à l'aide de contraintes portables ou, lorsque vous en avez besoin, utilisez une imageId spécifique, des profils matériels, etc.
Gestion basée sur des politiques
- Mesures en direct : collectez des métriques en direct à utiliser dans les politiques, soit à partir de store de métriques, soit directement à l'aide de REST, JMX, SSH, etc.
- Politiques de gestion : choisissez parmi les stratégies intégrées, parmi lesquelles auto-scaling, failover, follow-the-sun et bien dautres, ou créez de nouvelles stratégies pour effectuer une gestion d'exécution personnalisée. Utilisez les clés de configuration pour personnaliser les stratégies en fonction de vos systèmes, directement dans le plan YAML.
- Reconfiguration dynamique : reconfigurez les stratégies, suspendez-les ou ajoutez-en de nouvelles à la volée via l'API REST.
Les opérations
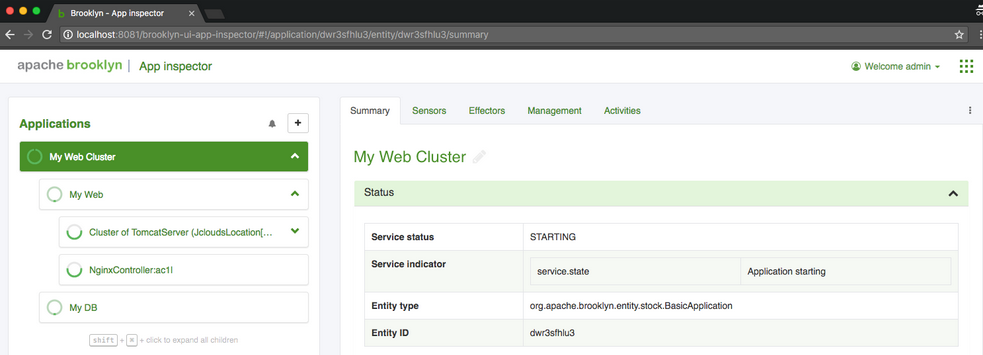
- Console de Brooklyn : Brooklyn fonctionne avec une console GUI donnant un accès facile à la hiérarchie de gestion, aux capteurs et aux activités.
- La haute disponibilité : exécutez des nuds de secours qui peuvent éventuellement être automatiquement promus en maître en cas de défaillance du maître. Les nuds de secours peuvent fournir un accès supplémentaire en lecture seule aux informations d'entité.
- Persistance de l'état : les informations sur le plan directeur, le catalogue, la topologie et les capteurs peuvent être automatiquement conservées dans n'importe quel système de fichiers ou store d'objets pour arrêter Brooklyn et reprendre où vous vous étiez arrêté.
- API REST : la console est purement JS-REST, et toutes les données affichées dans l'interface graphique sont disponibles via une API REST / JSON simple. Dans de nombreux cas, l'API REST est simplement le point de terminaison GUI sans le # principal. Par exemple, les données de #/v1/applications/ sont disponibles dans /v1/ applications/. Et dans tous les cas, Swagger doc est disponible dans le produit.
- Console Groovy : avec les bonnes autorisations, les scripts Groovy peuvent être envoyés via l'interface graphique ou via REST.
- Informations détaillées sur les tâches : la console affiche les flux de tâches en temps réel, y compris les commandes `stdin` et` stdout` pour le shell, ce qui simplifie le débogage.
Java
- Configuration détectable : les clés de configuration, les capteurs et les effecteurs peuvent être définis sur les classes de manière à être automatiquement détectables lors de l'exécution. Les informations de type, les paramètres, la documentation et les valeurs par défaut sont renvoyés via l'API REST et affichés dans l'interface graphique.
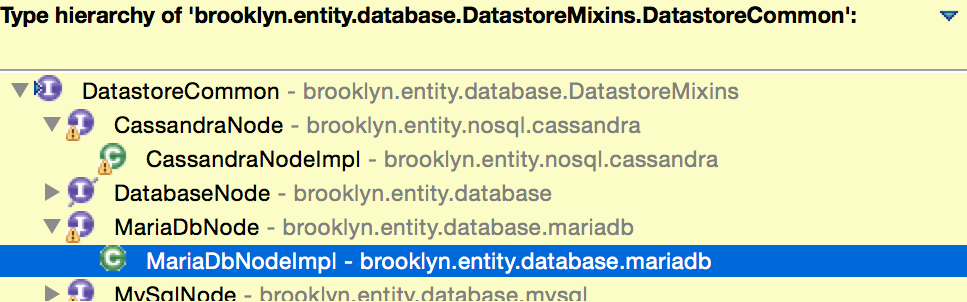
- Hiérarchie des types : utilisez des interfaces et des mixages pour partager et hériter le comportement d'une manière fortement typée.
- Bibliothèques de tâches : des bibliothèques de tâches de style Fluent builder sont incluses pour créer des chaînes d'activités qui s'exécutent en parallèle ou séquentiellement, exécutant SSH, REST ou des commandes Java arbitraires. L'état, le résultat, les hiérarchies et les erreurs de tâche sont exposés via l'API REST et dans l'interface graphique.
Source : Brooklyn
 Répondre avec citation
Répondre avec citation
Partager