


Que renvoie ton traitement d'exception ?
Inscrivez-vous gratuitement
pour pouvoir participer, suivre les réponses en temps réel, voter pour les messages, poser vos propres questions et recevoir la newsletter









Que renvoie ton traitement d'exception ?
Il y a peut-être plus simple, mais ça tourne.
Quand tout a échoué utilisez l'option RTFM

1 conseil pour les gros traitements : virer l'audit dynamique et performances dans le tableau de bord du projetEnvoyé par lololebricoleur

Ca occupe beaucoup de ressources




Tu n'aurais pas une histoire de taille de fichier limitée à 2 Go :
- par l'analyse ?
- par l'OS (fat 32) ?
Commencez toujours appuyer sur la touche F1 et puis n'hésitez à passer par un moteur de recherche...
Le forum est fait pour répondre aux questions : pas la peine de me les envoyer par MP. Merci.
Sur internet, tout est vrai ! Honoré de Balzac
Make it real not fantasy... Herman Rarebell

J'ai déjà eu le cas où en debug ça finit par planter mais par contre si tu crées un exe là plus de problème. Tu peux peut-être faire le test.
Philippe,
N'hésitez à lever le pouce si mon aide vous a été utile.




A chaque ligne insérée dans un fichier HF, l'index se dégrade un peu, et grossit anormalement.
Tu peux compter les lignes traitées, et toutes les 100000 lignes par exemple, faire un hRéindex() sur le fichier HF. le hReindex peut diviser la taille du fichier ndx par 10 dans certains cas.
N'oubliez pas le bouton Résolu si vous avez obtenu une réponse à votre question.

La réindex à chaud est même à priori possible en CS bien que sur un fichier intensément accédé je n'ai jamais testé.
De plus pour accélerer les ajouts HEcrit peut être utilisé, il ne met pas à jour les index (ce qui devra être fait par reindexation à la fin du traitement). Ca permet si c'est possible car parfois la mise à jour de l'index est nécessaire pour le traitement, d'écrire plus vite dans le fichier mais pareil, jamais eu l'occasion de faire un bench.

Merci pour toutes vos idées et infos,
J'ai tenté d'utiliser un serveur HF mais même problème, sa plante.
Du coup je fais autrement :
- Je commence par découper mon gros fichier en plusieurs moins lourds
- Et j'insère les enregistrement en lisant les fichiers créés
C'est long mais ça plante pas
tbc92, je note l'info, très intéressant.
Sait on pourquoi l'index se dégrade peu à peu ?
Du coup, peut être que mon découpage de fichier ne sers à rien.
Je vais faire des tests
Merci à tous de votre aide ;-)
Les solutions les plus simples sont les plus efficaces
Tbc92,
J'ai testé en réindexant tout les 100000 lignes et ça a marché.
Ca prend un temps de dingue par compte.
J'ai 50 000 000 d'enregistrements créés donc c'est probalement normal.
Si vous avez une idée ou astuce pour accéler la chose, suis prenneur.
Merci de votre aide
Les solutions les plus simples sont les plus efficaces
Sur les index, voici ce que j'avais appris il y a très longtemps.
Imaginons un fichier avec les 36000 communes de France, et un index sur le code postal.
Si l'index est parfaitement bâti (donc après un hReindex), il contiendra en gros les informations suivantes :
Enregistrement n°0 = Code postal 45123 (=un n° proche du milieu) et à gauche de 45123, il y a 22234 et 67890 (22234 est la commune telle que 25% des communes sont avant ce n°, et 25% entre ce n° et 45123, et même logique our 67890)
En dessous de 22234, il va contenir des liens vers les lignes situées à 12.5% et 37.5% du fichier ...
En résumé : en dessous de chaque noeud, il donne des liens vers 2 noeuds, de façon à découper l'ensemble de toutes les lignes en 2 groupes égaux, puis 4 groupes égaux, puis 8 etc etc. Chaque enregistrement à donc 2 enfants ; maximum 2 enfants, un à sa droite et un à sa gauche.
Maintenant, si on importe des données, et qu'on ne fait pas de hReindex, l'index va prendre le 1er enregistrement lu , par exemple la commune 05123. A ce niveau, le fichier n'a qu'1 enregistrement, les liens vers les 2 enfants pointent vers rien du tout. Ce 1er enregistrement restera en haut de l'arbre tant qu'on ne fera pas de hReindex(), l'index servira à positionner tous les enregistrements à droite ou à gauche de ce 05123. Et dans les faits, l'arbre va être très déséquilibré, parce que 95% des enregistrements seront sur la branche de droite, et seulement 5% sur la branche de gauche.
Et ainsi de suite, à chaque nouvel enregistrement qu'on ajoute, il le positionne dans un des sous-arbres.
Il ne modifie jamais les premiers éléments de l'arbre, il ne peut que rajouter un noeud au niveau le plus bas de l'arbre.
Si par exemple, on insère les valeurs 2 4 6 8 10 1 3 5 7 9 dans un fichier dans cet ordre, il va dire :
2 est en haut de l'arbre, ses 2 enfants sont 1 et 4
1 a pour enfants Vide et 3
4 a pour enfants Vide et 6
3 a pour enfants Vide et 5
6 a pour enfants Vide et 8
5 a pour enfants Vide et 7
8 a pour enfants Vide et 10
7 a pour enfants Vide et 9
Ca c'était la théorie il y a très longtemps. Ce n'était pas spécifique à HFSQL, c'était la logique pour n'importe quel index de n'importe quelle base de données.
Dans la vraie vie, c'est plus optimisé que ça ; quand on insère une nouvelle ligne, le moteur peut faire quelques réaménagements mineurs pour tenter de garder l'arbre le plus équilibré possible. Et c'est surtout plus compliqué ; je ne connais pas la théorie, mais je crois que chaque noeud peut avoir plus que 2 enfants. Par exemple, quand on réindexe, on peut spécifier si on veut optimiser l'écriture (le programme va laisser délibérément quelques emplacements libres dans l'arbre, pour faciliter l'écriture), ou si on veut optimiser la lecture.
La réindexation à chaud : je ne pense pas que ce soit efficace sur un traitement aussi massif.
Utiliser hEcrit() au lieu de hAjoute() : je n'y avais pas pensé, et c'est probablement une très bonne idée ici. hEcrit va beaucoup plus vite que hAjoute ... mais on a l'obligation de faire hReindex à la fin. Et attention, si on a des enregistrements en double par exemple dans le fichier, hEcrit ne va pas les rejeter, et hReindex va planter.
N'oubliez pas le bouton Résolu si vous avez obtenu une réponse à votre question.
Voroltinquo a parlé de HImporteTexte et c'est bon
pour 108 CSV (FANTOIR VOIE CSV) traités à la chaine soit 1 total de plus de 8000000 d'enregistrements, je met 4 mn avec une clé unique sur une machine rapide
les rubriques du FIC doivent correspondre à celles du CSV
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
j'ai alimenté mon FIC avec plus de 65 000 000 entrés en moins d'une heure en répétant le clic de ce code
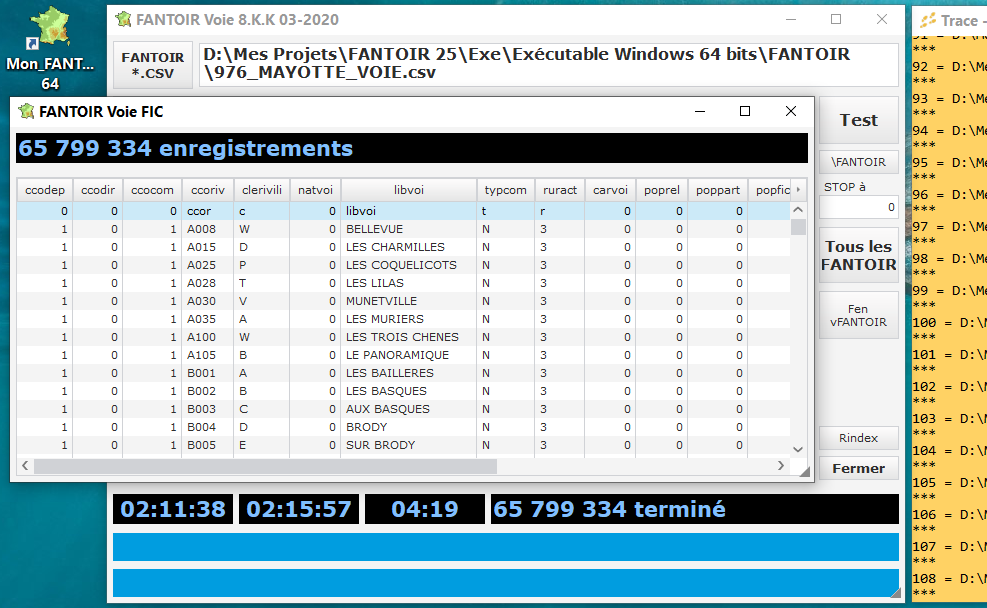
tbc92 tu as raison pour ça
La réindexation à chaud : je ne pense pas que ce soit efficace sur un traitement aussi massif.
j'ai ajouté expré 1 idcléunik dans mon fichier de récupération de CSV dans code que j'ai donné avant et réindexé au fur et à mesure pour voir et ça n'aporte rien
les SSD gére mieux les écritures? à voir
sur un HDD qui fragmente vite, ça doit etre plus utile comme défragmenter régulièrement
si pas de clé, c'est moin utile de réindexer je crois
Pour accélérer le traitemetn, la solution est de passer par hEcrit.
Pour chacun des enregistrements, hEcrit doit ajouter l'enregistrement dans le fichier FIC, alors que hAjoute doit ajouter l'enregistrement dans le fichier FIC, plus mettre à jour l'index (ou les index s'il y en a plusieurs).
Donc hAjoute est en gros 2 ou 3 fois plus lent.
En plus, tu vas faire une seule fois hReindexe() à la fin de l'import, au lieu de 500 fois dans le scénario actuel.
MAIS, il y a forcément un mais... si dans ton fichier il y a des contraintes (clé unique ... ) et que ton fichier CSV contient quelques bugs ( lignes en double), alors hEcrit ne détectera pas le problème, et hReindexe refusera de réindexer ... impasse.
Si tu es 100% sûr que le fichier CSV ne contient aucun bug de ce genre, tu peux passer par hEcrit.
Si tu restes sur le scénario actuel, le dosage "un hReindexe tous les 100000 enregistrements" est peut-être trop fréquent. Le ratio que j'avais en tête, c'est : quand on modifie (ou ajoute) 10% des enregistrements, il faut faire un hReindexe.
N'oubliez pas le bouton Résolu si vous avez obtenu une réponse à votre question.
La solution par laquelle je passe dans ce cas là est de stocker la clé unique dans un tableau. Avant de traiter la ligne je regarde si la clé existe déjà dans le tableau. Si non alors Hécrit, si oui, j'enregistre la ligne lue dans un fichier de log.
Commencez toujours appuyer sur la touche F1 et puis n'hésitez à passer par un moteur de recherche...
Le forum est fait pour répondre aux questions : pas la peine de me les envoyer par MP. Merci.
Sur internet, tout est vrai ! Honoré de Balzac
Make it real not fantasy... Herman Rarebell
Et en terme de performance, ça se passe bien ?
Parce que en fait, d'une certaine façon, la gestion de l'index qui devrait être faite par HFSQL, c'est toi qui la fais dans ton process.
Tu passes par un tableau associatif : tb_deja_vu( ma_cle) = vrai ou quelque chose comme ça ?
N'oubliez pas le bouton Résolu si vous avez obtenu une réponse à votre question.
Bonjour à tous,
J'ai lu le thread en diagonale, mais je crois que le but est d'insérer des données multiples dans un fichier table HFSql à partir d'un fichier texte au format csv, le tout en essayant d'être le moins long et le plus fiable possible.
Je ne connais pas HFSql, mais ne serait-il pas possible qu'il soit plus performant d'utiliser une requête du type :
Code SQL : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
à adapter bien sur, mais l'idée est là, ... à essayer
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
@tbc92,
je n'ai pas testé sur des fichiers de cette taille. Le "risque" est de devoir passer par une appli 64 bits afin de ne pas risquer une saturation mémoire.
J'utilise surtout cette méthode pour éviter de lire n fois la même chose dans un fichier. Notamment lorsque l'on fait des "bilans" de fin d'année.
@padbrain,
En règle générale, pour HF, le SQL est moins performant que les instructions Hxxxx.
Pour les autres bases de données, si tu as l'accès natif, autant rester également en instructions Hxxxx.
Commencez toujours appuyer sur la touche F1 et puis n'hésitez à passer par un moteur de recherche...
Le forum est fait pour répondre aux questions : pas la peine de me les envoyer par MP. Merci.
Sur internet, tout est vrai ! Honoré de Balzac
Make it real not fantasy... Herman Rarebell
C'est bien possible Frenchsting et je n'ai pas assez d'expérience sur windev pour dire le contraire, mais là on parle de x accès à la base contre 1 requête, donc 1 accès, dont les insertions multiples seront gérées par le moteur de base de données.
Il me semble que ce qui est couteux en temps sont les accès, maintenant, je dis peut-être une connerie, je soumet juste l'idée.
Oui, sauf, que vu le nombre d'ajouts (50 000 000 si j'ai bien compris), le moteur HFCS aura sûrement rendu les armes.
Tu travailles sur quel BDD ? Oracle, SQL Server ? Tu as essayé de balancer une requête comme celle-ci ?
Commencez toujours appuyer sur la touche F1 et puis n'hésitez à passer par un moteur de recherche...
Le forum est fait pour répondre aux questions : pas la peine de me les envoyer par MP. Merci.
Sur internet, tout est vrai ! Honoré de Balzac
Make it real not fantasy... Herman Rarebell
J'ai commencé à bosser sur windev il y a huit mois de ça, sur un nouveau poste, sur un projet de gestion commerciale connectée à une base MySql.
Et non, je n'ai jamais essayé de balancer une requête comme celle-ci. Mais si je devais gérer le truc, je n'hésiterais pas à le tenter, quitte à découper le fichier et faire plusieurs requêtes INSERT, qui seraient, toujours AMHA, de toute façon moins couteuses que 50 000 000 de HEcrit ou HAjoute.
Enfin, je pense mais j'ai p-e tord et, seul un essai pourrait nous le dire.")
Oui, tu as raison : qui ne tente rien n'a rien...
@lololebricoleur de faire de nous faire des retours de ses tests.
Commencez toujours appuyer sur la touche F1 et puis n'hésitez à passer par un moteur de recherche...
Le forum est fait pour répondre aux questions : pas la peine de me les envoyer par MP. Merci.
Sur internet, tout est vrai ! Honoré de Balzac
Make it real not fantasy... Herman Rarebell

Vous avez un bloqueur de publicités installé.
Le Club Developpez.com n'affiche que des publicités IT, discrètes et non intrusives.
Afin que nous puissions continuer à vous fournir gratuitement du contenu de qualité, merci de nous soutenir en désactivant votre bloqueur de publicités sur Developpez.com.
 Répondre avec citation
Répondre avec citation
Partager