






C'est très intéressant mais on s'est probablement mal compris.Envoyé par MaximeCh

Ici tu montres bien que la documentation de SQL Server est insuffisante et bien en deçà de ce que propose ICU. Et éventuellement que ICU propose bien plus d'options. Certes.
Par contre quand je lis ce message, auquel je réponds, on a l'impression que c'est la collation elle-même qui a des fonctions en moins et même que c'est pour cette raison que SQL Server peut se permettre de supporter le LIKE contrairement à Postgres.
Et dans tous les cas, un exemple pratique serait bien plus lisible que beaucoup de documentation.
Là encore, tu as mal compris comment j'ai interprété la phrase de SQL Builder. Tel que j'ai compris (mais peut-être nous dira-t-il que c'était ton interprétation qui était correcte), SQL Server s'attend à priori à être seul sur sa machine, et s'autorise donc par défaut à s'approprier toutes les ressources disponibles, voire même à s'accorder plus de priorité que le système d'exploitation...
Donc, quand on investit dans SQL Server, il faut être aussi prêt à investir dans une machine dédiée, sinon autant se contenter de la version express.
Et non, je n'ai pas écrit que Postgres ne sait pas le faire, j'ai seulement voulu dire que ce n'est pas la manière dont il est utilisé la plupart du temps.
Puisqu'on est dans la sémantique, je continue:
Ici j'ai voulu garder un nom assez court, tant qu'on sait que cette collation sera la seule utilisée dans l'application ça peut suffire. Par contre pour les collations fournies par défaut, il vaut mieux des noms plus longs.
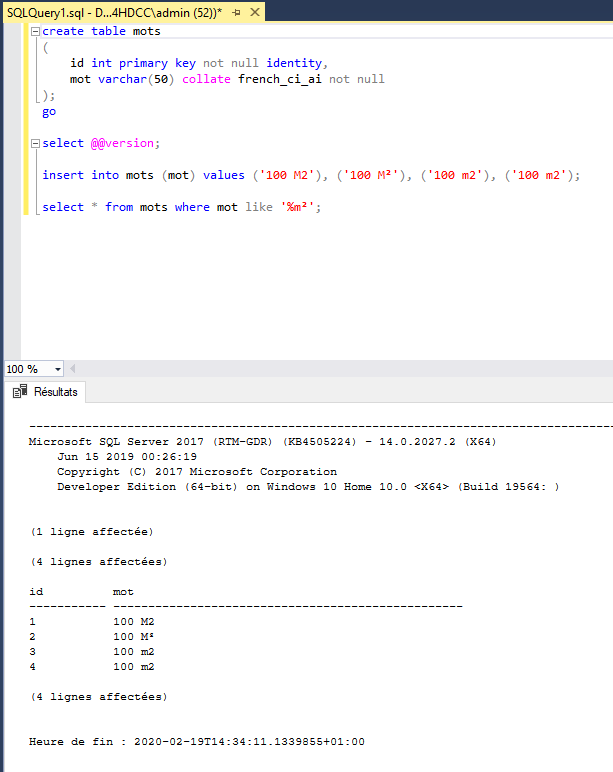
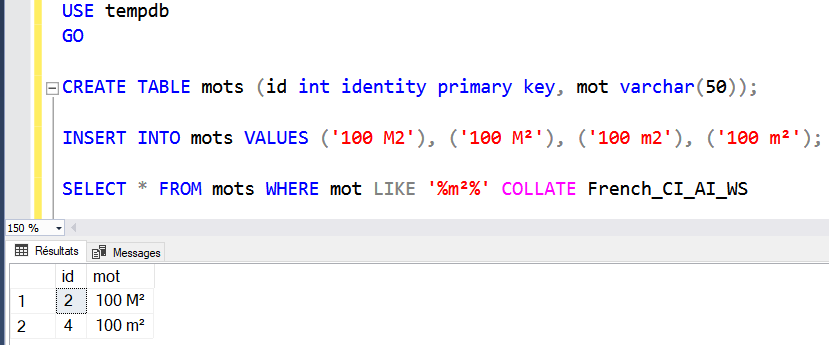
Peut-être que le A est mal choisi en effet (j'aurais mis un D pour Diacritique mais j'aurais alours oublié les ligatures comme ) mais fondamentalement, sais-tu seulement à quoi correspond "french"? Il faut quand même savoir que "insensible aux accents" n'a pas le même sens pour la langue française que pour d'autres langues. En français on admet généralement que si on doit écrire sans accents (sur un ordinateur avec un clavier qwerty par exemple) alors façade doit être écrit facade. En allemand c'est déjà plus compliqué, le remplaçant de ö n'est pas o mais oe (sans la ligature évidemment) et surtout le remplaçant de ß est ss... et comme si ce n'était pas assez compliqué, il y a deux ordres alphabétiques couramment utilisés: un dans lequel ö est remplacé par o, et un autre où il est remplacé par oe!
Tout ça pour dire que ou ç sont en fait contenus dans "french", et ensuite, pour chaque langue on va avoir une ou plusieurs collations qui vont différer par la manière dont elles traitent les signes diacritiques (par exemple æ existe aussi bien dans la collation française et danoise, mais le traitement appliqué pour l'ordre de tri n'est pas du tout le même!). Une fois qu'on sait cela, le choix du nom french_ci_ai n'est pas si absurde que cela, finalement. Le seul problème est qu'on aimerait bien avoir quelque part une définition complète listant pour chaque collation, les substitutions qui sont faites. Pour ICU on a au moins le code source, mais ce ne serait pas inutile non plus.
 Répondre avec citation
Répondre avec citation


















Partager